
Pandas 基础 (19) - 操作数据库 (read_sql, to_sql)
0 / 0 / 创建于 7年前
 Rachel 的个人博客
Rachel 的个人博客
安装两个包:
pip3 install PyMySQL
pip3 install sqlalchemy连接 Mysql 数据库:
import pandas as pd
import sqlalchemy
engine = sqlalchemy.create_engine('mysql+pymysql://root:root@localhost:3306/express')这是连接 mysql 数据库的参数规则, 如果是其他数据库, 可参照 官网 下图这个部分
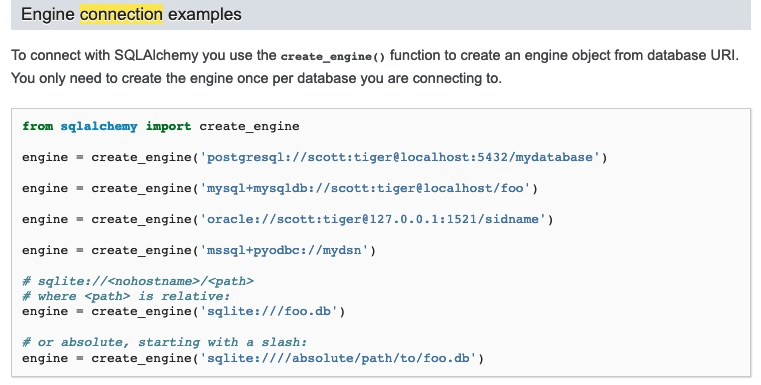
读
下面就可以从数据库读取数据了:
df = pd.read_sql_table('users', engine)
df只想读取指定字段也可以:
df = pd.read_sql_table('users', engine, columns=['email', 'mobile'])
df执行 sql 语句:
query = '''
SELECT nick_name, email from users where id < 5
'''
df = pd.read_sql_query(query, engine)
df写
假如你有一份 csv 格式的文件, 想要导入数据库
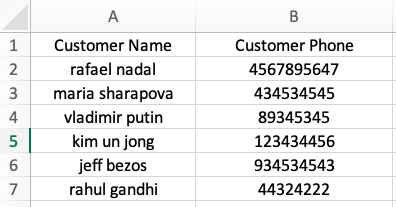
先把它转成 dataframe 吧:
df = pd.read_csv('/Users/rachel/Sites/pandas/py/pandas/21_sql/customers.csv')
df输出:
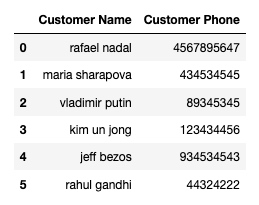
把表头重命名, 要保证跟要插入的数据表的字段名一致, 否则是无法插入的:
df.rename(columns = {
'nick_name': 'name',
'Customer Phone': 'mobile',
}, inplace = True)
df下面就是执行导入数据库的命令了. 第一个参数是指定要导入到哪个表中, 第二个参数是连接用的, 第三个参数是要去掉索引, 第四个参数是指如果数据库里已经有某个值了, 就 keep both, 这个参数值有几种不同的, 比如"覆盖"等.
df.to_sql(
name = 'admin_users',
con = engine,
index = False,
if_exists = 'append'
)介绍最后一个函数 pd.read_sql(), 它是 read_sql_table() 和 read_sql_query() 的集合, 也就说它会根据传入的第一个参数自动判断是 table 还是 query:
df = pd.read_sql('admin_users', engine)
dfand:
query = '''
SELECT nick_name, email from users where id < 5
'''
df = pd.read_sql(query, engine)
df以上就是 Pandas 对数据库的基本操作, 也是 Pandas 基础学习的最后一篇, 我要开始进军 Data Analysis. 耽误好久了, 人笨, 走得慢.......
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



