
scrapy + mogoDB 网站爬虫
2 / 0 / 创建于 7年前 /
 Rachel 的个人博客
Rachel 的个人博客
工具环境
语言:python3.6
数据库:MongoDB (安装及运行命令如下)
python3 -m pip install pymongo
brew install mongodb
mongod --config /usr/local/etc/mongod.conf框架:scrapy1.5.1 (安装命令如下)
python3 -m pip install Scrapy用 scrapy 框架创建一个爬虫项目
在终端执行如下命令,创建一个名为 myspider 的爬虫项目
scrapy startproject myspider即可得到一个如下结构的文件目录
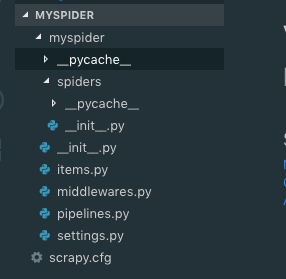
创建 crawl 样式的爬虫
针对不同的用途, scrapy 提供了不同种类的爬虫类型,分别是
Spider:所有爬虫的祖宗
CrawlSpider:比较常用的爬取整站数据的爬虫(下面的例子就是用这种)
XMLFeedSpider
CSVFeedSpider
SitemapSpider
先在命令行进入到 spiders 目录下
cd myspider/myspider/spiders然后创建 crawl 类型的爬虫模板
scrapy genspider -t crawl zgmlxc www.zgmlxc.com.cn参数说明:
-t crawl指明爬虫的类型
zgmlxc是我给这个爬虫取的名字
www.zgmlxc.com.cn是我要爬取的站点
完善小爬虫 zgmlxc
打开 zgmlxc.py 文件,可以看到一个基本的爬虫模板,现在就开始对其进行一系列的配置工作,让这个小爬虫根据我的指令去爬取信息。
配置跟踪页面规则
rules = (
// 定位到 www.zgmlxc.com.cn/node/72.jspx 这个页面
Rule(LinkExtractor(allow=r'.72\.jspx')),
// 在上面规定的页面中,寻找符合下面规则的 url, 爬取里面的内容,并把获取的信息返回给 parse_item()函数
Rule(LinkExtractor(allow=r'./info/\d+\.jspx'), callback='parse_item'),
) 这里有个小坑, 就是最后一个 Rule 后面必须有逗号, 否则报错, 哈哈哈
rules = ( Rule(LinkExtractor(allow=r'./info/\d+\.jspx'), callback='parse_item', follow=True), )
在items.py内定义我们需要提取的字段
import scrapy
class CrawlspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
content = scrapy.Field()
piclist = scrapy.Field()
shortname = scrapy.Field()完善 parse_item 函数
这里就是把上一步返回的内容,配置规则,提取我们想要的信息。这里必须用 join 方法,是为了方便后面顺利导入数据库。
def parse_item(self, response):
yield {
'title' : ' '.join(response.xpath("//div[@class='head']/h3/text()").get()).strip(),
'shortname' : ' '.join(response.xpath("//div[@class='body']/p/strong/text()").get()).strip(),
'piclist' : ' '.join(response.xpath("//div[@class='body']/p/img/@src").getall()).strip(),
'content' : ' '.join(response.css("div.body").extract()).strip(),
}PS: 下面是提取内容的常用规则,直接总结在这里了:
1). 获取 img 标签中的 src:
//img[@class='photo-large']/@src2). 获取文章主题内容及排版:
response.css("div.body").extract()
将信息存入 MogoDB 数据库
设置数据库信息
打开 settings.py 添加如下信息:
# 建立爬虫与数据库之间的连接关系
ITEM_PIPELINES = {
'crawlspider.pipelines.MongoDBPipeline': 300,
}
# 设置数据库信息
MONGODB_SERVER = "localhost"
MONGODB_PORT = 27017
MONGODB_DB = 'spider_world'
MONGODB_COLLECTION = 'zgmlxc'
# 设置文明爬虫, 意思是每个请求之间间歇 5 秒, 对站点友好, 也防止被黑名单
```py
DOWNLOAD_DELAY = 5在 piplines.py 中
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
def process_item(self, item, spider):
valid = True
for data in item:
if not data:
valid = False
raise DropItem("Missing {0}!".format(data))
if valid:
self.collection.insert(dict(item))
log.msg("Question added to MongoDB database!",
level=log.DEBUG, spider=spider)
return item在终端运行这个小爬虫
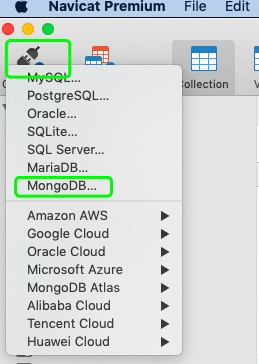
scrapy crawl myspider在 navicat 中查看信息入库情况
如下图新建一个 MogoDB 的数据库连接,填入上面配置的信息,如果一切顺利, 就可以看到我们想要的信息都已经入库了。
以上就完成了自定义爬虫到数据入库的全过程辣~~~
参考:
scrapy 官方文档Web Scraping and Crawling with Scrapy and MongoDB
本作品采用《CC 协议》,转载必须注明作者和本文链接








 关于 LearnKu
关于 LearnKu




推荐文章: