
Deep Learning With Python, Tensorflow & Keras - Neural Network For Image Classification
0 / 0 / 创建于 7年前
 Rachel 的个人博客
Rachel 的个人博客
引言
这节课将针对图片识别的需求,建立第一个 “Neural Network”。在 Keras fashion MNIST dataset 中,有如下图这样的一个关于服饰图形的数据集,我们可以用这些数据集来训练模型,就好像是训练一个小孩的大脑一样,裤子的样子可以有很多种,我们拿很多种裤子给这个小孩,告诉他这个样子的都是叫做 “裤子”,从而形成他对裤子的认知,Deep Learning 也是同样的原理。

另外,这张图上的每个图像都是由 28*28=784 个像素构成的。而每一个像素都可以看作是一个神经元,每个神经元的值都是 0-1,表现出来的就是由白到黑等不同的灰度,最终,784个不同灰度的像素块构成了每一张图,就像这个靴子一样:
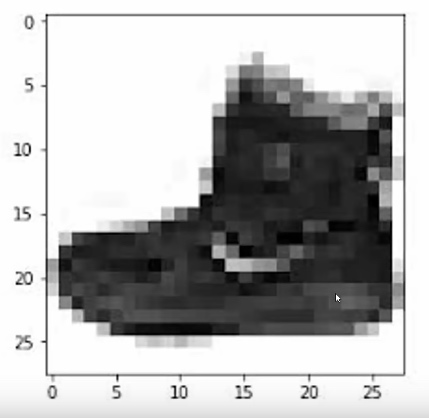
正文
引入需要的包
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import keras
// 常看目前 keras 使用的引擎,也就是默认使用的 backend
keras.backend.backend() // 输出 'tensorflow'1. 引入数据集
a). 根据 Keras Api 文档,执行如下命令,就可以下载到我们所需要的数据集:
from keras.datasets import fashion_mnist
(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()P.S.: 这里的
X_train和X_test中的X必须用大写
b). 简单看下该数据集的内容
训练数据和测试数据的整体结构
X_train.shape // 输出 (60000, 28, 28),说明有 6000 个数据,每个数据都是由 28*28 个像素构成的
X_test.shape // 输出 (10000, 28, 28),说明有 1000 个测试数据具体分析某个数据
X_train[0]输出的是一个二维数组(这里只截取部分),横向和纵向分别是 28 行和 28 列,总体 784 个像素点分别以不同的色号存在,并组合成一个图像。
以图像的形式查看这个数据(一共有 6000个测试数据,大家可以随意试下 6000 以内的数字,看看输出图像的样子):
plt.matshow(X_train[0])输出:

查看第一个数据对应的 label
y_train[0] // 输出 9在上面提到过的 API 文档中,可以看到 label 9 对应的图像就是 Ankle boot.

c). 总结这个数据集的结构
这个数据集一共有 7000个数据,其中,6000 个作为训练数据,1000 个作为测试数据。每个数据都可以看成是一个对象,由 28*28 个像素(会有不同的 RGB 色号, 从而表现出不同的颜色)构成一幅图,同时还对应着 0-9 的 label 值,而 0-9 又分别代表着不用的服饰类别。所以就是一共有 7000 个服饰的图像,可以归纳为 10 个类别。以上,希望我讲明白了,如果有不清楚的,欢迎留言谈论。。。。。。
d). 整理数据集
目前每个像素的值都是 0-255,训练模型时,需要的值是 0-1,所以对数据做如下处理:
X_train = X_train/255
X_test = X_test/2552. 使用 [Keras Sequential model](Keras Sequential model) 建立 linear Neural Network
a). 引入包
from keras.models import Sequential
from keras.layers import Dense, Activation, Flattenb). 创建模型
model = Sequential()c). 建立 neurons network
model.add(Flatten(input_shape=[28,28])) // 输入层
model.add(Dense(200, activation='relu')) // 中间层
model.add(Dense(10, activation='softmax')) // 输出层d). 查看模型
model.summary()输出
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_4 (Flatten) (None, 784) 0
_________________________________________________________________
dense_5 (Dense) (None, 200) 157000
_________________________________________________________________
dense_6 (Dense) (None, 10) 2010
=================================================================
Total params: 159,010
Trainable params: 159,010
Non-trainable params: 0
_________________________________________________________________e). 编译模型
model.compile(loss="sparse_categorical_crossentropy",
optimizer = "adam",
metrics = ["accuracy"])f).训练模型
model.fit(X_train, y_train,epochs = 3 )g). 查看模型精度
model.evaluate(X_test, y_test) // 输出 0.8684h). 测试模型
在 X_test 中,随机抽取一个数据来查看模型的准确度
plt.matshow(X_test[10])输出:
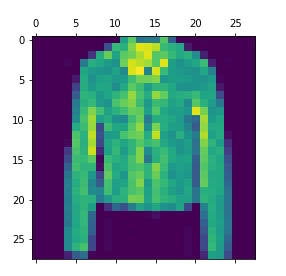
// 得出所有的测试数据 yp
yp = model.predict(X_test)
// 查看第一个测试数据的值
yp[10]
// 输出
array([8.87211208e-05, 8.38008709e-05, 1.22824974e-01, 5.10792916e-06,
8.17192376e-01, 7.80780056e-07, 5.97540773e-02, 2.47130760e-08,
4.97993715e-05, 2.97149313e-07], dtype=float32)
// 以上输出的是一个数组,其中数值最大的元素,就是最终得出的值,可以借助 numpy 的 argmax() 函数来得出这个最大值
np.argmax(yp[10]) // 输出 4 通过上面的预测,我们得到的结果是 4,再去查看 Fashion-MNIST database API, 看到 label 4 对应的就是 coat, 说明模型预测成功。

本作品采用《CC 协议》,转载必须注明作者和本文链接








 关于 LearnKu
关于 LearnKu



