
Machine Learning (4) - 用 Dummy Variables & One Hot Encoding 处理非数字列值
0 / 0 / 创建于 7年前
 Rachel 的个人博客
Rachel 的个人博客
问题
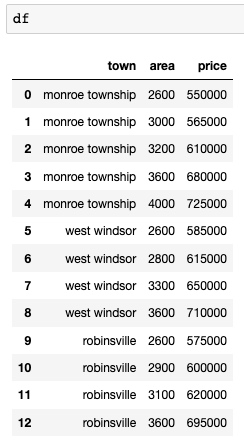
在实际应用中,我们经常会遇到像下图这样的情况,那就是有的列是非数字的。但是 Machine Learning 只善于处理数字,所以我们需要将非数字的内容进行合理的转换,再来训练模型。
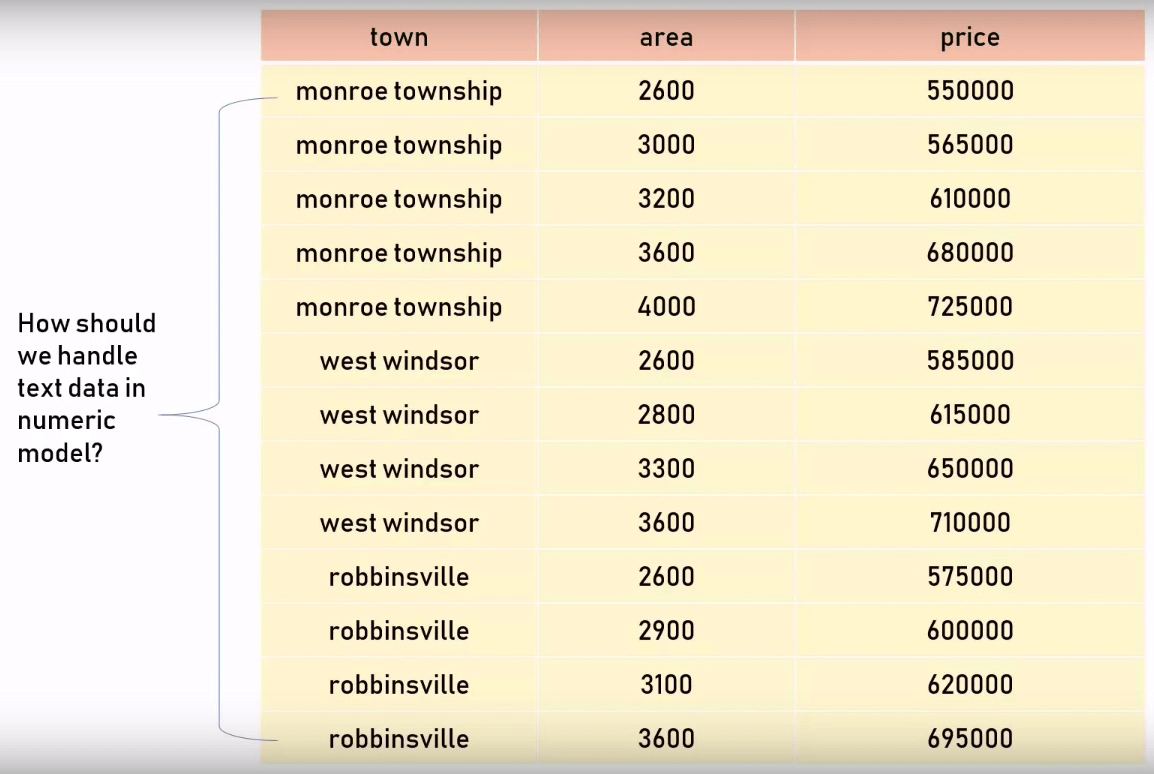
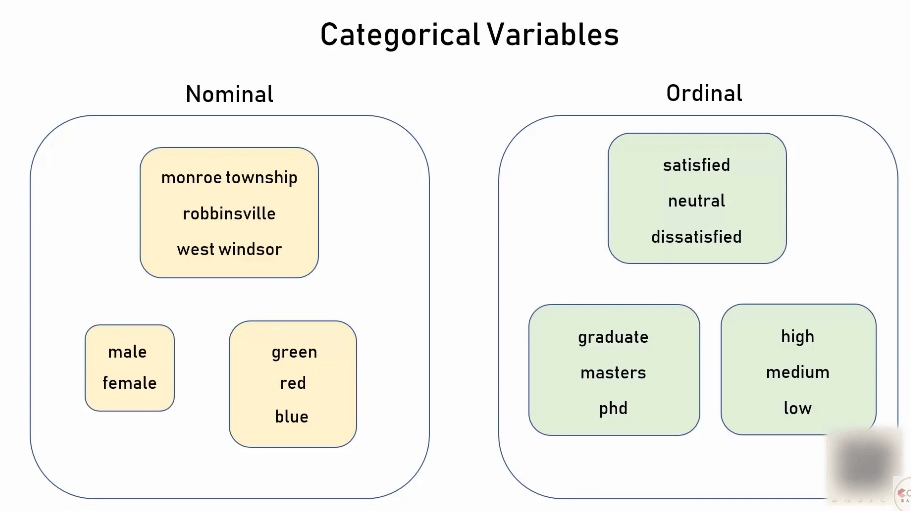
在上图中的 town 列被称为 categorical variables(类别变量)。categorical variables 又分为两种,一种是 nominal,另一种是 ordinal。下面分别解释一下:
nominal: 分类的值没有任何先后顺序或等级关系
ordinal:分类的值是有等级关系的
例子如下:
解决方案
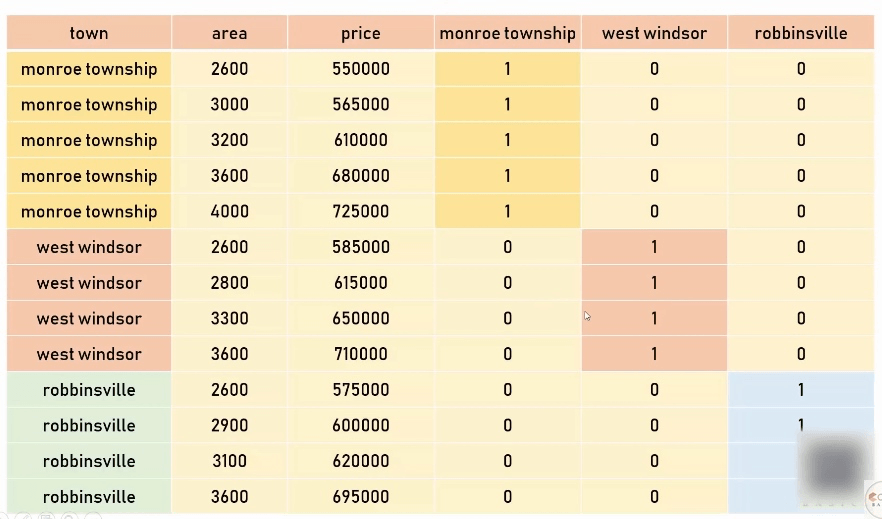
很显然,上面 town 列应该属于 nominal category variables, 我们可以用一种名为 One Hot Encoding 的技术来解决这个问题。我们为列中的每一种分类都分别单独建一个列,用 0 或 1 填充,这些新建的列被称作 dummy vaiables。最终想要的效果如下图:
具体实现方法(两种):
方法一:使用 Pandas 的 get_dummies 方法
import pandas as pd
from sklearn import linear_model
df = pd.read_csv('/Users/rachel/Downloads/py-master/ML/5_one_hot_encoding/homeprices.csv')
// 获取 town 列的 dummies
dummies = pd.get_dummies(df.town)
// 合并新生成的 dummies 列与原表
merged = pd.concat([df, dummies], axis='columns')
// 把原表的 town 列删掉, 还要删掉 dummies 列中的任意一列
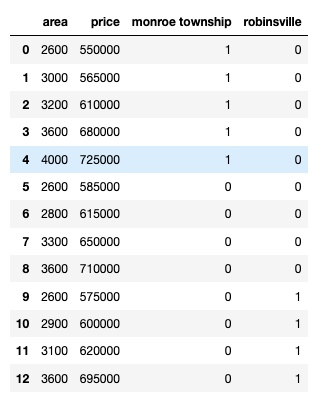
final = merged.drop(['town', 'west windsor'], axis='columns')Tips:
这里使用 'west windsor', 'monroe township' 和 'robbinsville' 三个列来分别表示原来 'town' 列的三个类别, 然后用 0 和 1 区别到底是哪个类别. 之所以要删掉一列, 是因为用两个列的值就可以推导出第三列的值, 比如, 我们现在随机删掉了 'west windsor' 列的值, 那么 'monroe township' 列或者 'robbinsville' 是 1 的时候, 'west windsor' 列必然是 0, 而如果这两列都为 0 的时候, 'west windsor' 列必然是 1, 所以, 就可以省掉那一列,据说也是必须删掉这多余的一列,否则在训练模型的时候会出现错误。另外, 如果是用 LinearRegression 的话, 其实, 它会自动帮我们删除一列, 但是为了养成良好的习惯, 还是自己主动删除吧.
看下最后整理后的数据:
// 实例化一个模型
model = linear_model.LinearRegression()
// 准备数据, 这里 x 的数据就是表里除了 price 的所有字段, 所以直接把 price 字段删了, 方便快捷
x = final.drop('price', axis='columns')
y = final.price
// 训练模型
model.fit(x, y)
// 从模型取数据: area 2800, robinsville 的房子价格
model.predict([[2800, 0, 1]])
// 这个方法是测下这个模型的精准度, 这个值应该是还可以
model.score(x, y) //0.9573929037221873方法二:使用 sklearn 的 OneHotEncoder
1. 重新引入 dataframe
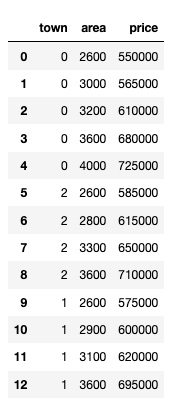
2. 将 town 列的值转为数字
from sklearn.preprocessing import LabelEncoder
// 创建 LabelEncoder 对象
le = LabelEncoder()
// 把原 dataframe 重新赋给变量 dfle
dfle = df
// 把 town 列转为数值
dfle.town = le.fit_transform(dfle.town)
dfle看下效果:
// 设置 x 的值, 通过 values 方法, 把 x 值转为数组, 否则是 dataframe
x = dfle[['town', 'area']].values
x
3. 用 OneHotEncoder 获取 dummy variables
from sklearn.preprocessing import OneHotEncoder
// 用 OneHotEncoder 将数组的第一列转为 dummy variable
ohe = OneHotEncoder(categorical_features=[0])
x = ohe.fit_transform(x).toarray()
// 取所有行的值, 去掉第一列的值, 也就是只保留 dummy variables 中的任意两列
x = x[:, 1:]
y = dfle.price
// 训练模型
model.fit(x, y)
model.predict([[1, 0, 2800]])本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



