
Machine Learning (5) - Training and Testing Data
0 / 0 / 创建于 7年前
 Rachel 的个人博客
Rachel 的个人博客
引言
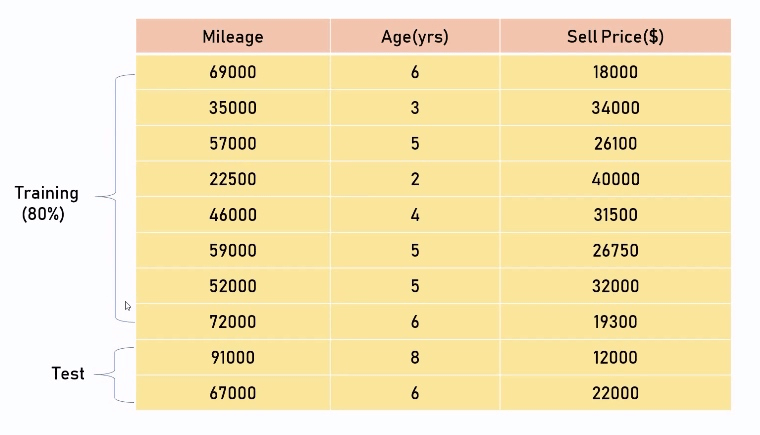
Machine Learning 的最佳实践是,拿到一个数据集, 将其按比例划分, 取其中大部分数据做数据模型, 一小部分用来对分析出来的模型做测试. 原因是显而易见的,如果用同样的数据既做训练又做测试,是没有意义的。
实现的方法很简单,使用 train_test_split()函数即可。
正文
通过一个简单的例子,看下 train_test_split() 函数的用法。
import pandas as pd
// 引入数据集
df = pd.read_csv('/Users/rachel/Downloads/py-master/ML/6_train_test_split/carprices.csv')
// 将数据集以图形化的形式输出
import matplotlib.pyplot as plt
%matplotlib inline
plt.scatter(df['Mileage'], df['Sell Price($)'])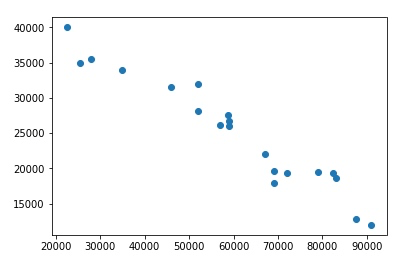
plt.scatter(df['Age(yrs)'], df['Sell Price($)'])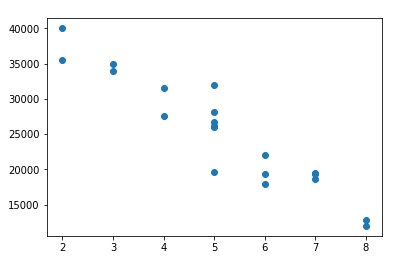
X = df[['Age(yrs)', 'Mileage']]
y = df['Sell Price($)']
// 划分数据, 30% 做测试, 加入 random_state=10 参数,
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=10)
len(X_train) // 查看建模数据的长度为 14
len(X_test) // 查看测试数据的长度为 6
from sklearn.linear_model import LinearRegression
clf = LinearRegression()
// 训练模型
clf.fit(X_train, y_train)
// 对于测试数据进行预测的结果
clf.predict(X_test)
// 输出
array([20668.52722622, 16762.33242213, 25160.18381011, 27209.30003936,
37903.32633702, 14729.61531335])
// 测试数据的实际值
y_test
// 输出
7 19300
10 18700
5 26750
6 32000
3 40000
18 12800
Name: Sell Price($), dtype: int64
// 模型准确度评估 0.9212422483776328
clf.score(X_test, y_test) 本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu



