
Machine Learning (6) - Logistic Regression (Binary Classification)
0 / 0 / 创建于 7年前 /
 Rachel 的个人博客
Rachel 的个人博客
引言
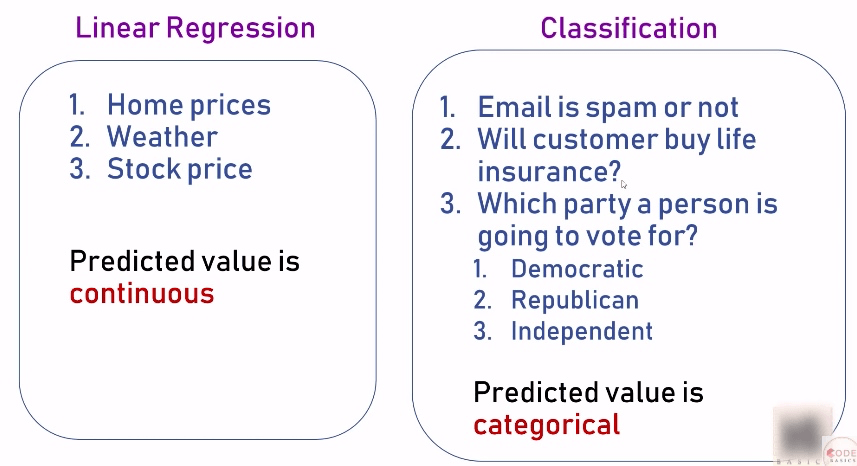
我们前面学习了 Linear Regression,它可以用于房价,天气,股价等的预测,会发现这些场景的数据值都是连续性的。因此可以总结,Linear Regression 用于预测连续的值。
而在现实中还有另外一种场景,比如,判断邮件是否为垃圾邮件,判断某人是否会买保险,或者是判断某人会投票给共和党还是民主党等。这些场景有个共同的特点,就是要预测的值是一种明确的分类。我们把这种问题称为 Classification (分类) 问题。可以用 Logistic Regression 来解决。

Classification (分类) 问题还分为两种情况,一种是预测的值只有 yes 或 no 两种分类,我们把这种分类问题称为 Binary Classification, 另一种是预测值是多种分类。
这节课先来看 Binary Classification 的处理方法。
正文
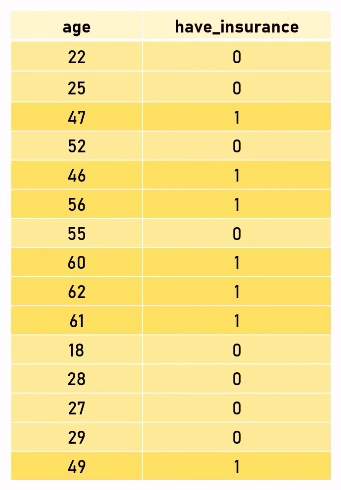
假如你是一个保险公司的数据分析师,任务是在已知上述数据的前提下,做分析,预测一个人购买保险的可能性。目测这个表的数值,可以大概看出,年轻人买的可能性比较小,年纪大的人买的可能性比较大。
引入数据
import pandas as pd
from matplotlib import pyplot as plt
%matplotlib inline
df = pd.read_csv('/Users/rachel/Downloads/py-master/ML/7_logistic_reg/insurance_data.csv')输出
图形化输出目前的数据分布
plt.scatter(df.age, df.bought_insurance, marker='+', color='red')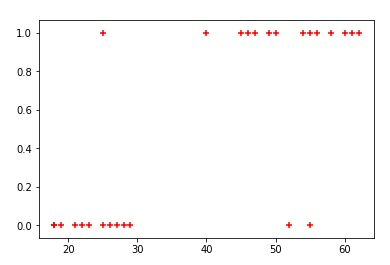
拆分训练数据和测试数据
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df[['age']], df.bought_insurance, test_size=0.2)引入模型并训练
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
// 训练模型
model.fit(X_train, y_train)
// 用测试数据预测
model.predict(X_test) // 输出 array([1, 0, 1, 0, 1, 1])
// 测试数据实际的值
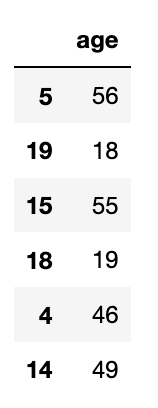
X_test输出
至此,一个简单的模型建立基本完成,现在我们来看下,形成这个模型的参数值 m 和 b 分别是多少?
model.coef_
// 输出,这是 Linear Regression 公式 mx+b 中 m 的值
array([[0.04271745]])
model.intercept_
// 输出,这是 Linear Regression 公式 mx+b 中 b 的值
array([-1.47546937])来分析一下预测数据的合理性,预测的值是 1,0,0,对应着年龄来看,就是 50岁的人会买保险,29岁和 30岁的人不会买保险。这也符合我们最初的分析。
查看模型精度
下面用 score() 函数查看模型的准确度:
model.score(X_test, y_test) // 输出 1.0, 由于数据量小, 所以准确度非常高
// 精确查看每个数据倾向的百分比
model.predict_proba(X_test)
array([[0.19136177, 0.80863823],
[0.76147559, 0.23852441],
[0.87036695, 0.12963305]])
// 随意预测一个年龄
model.predict([[25]]) // 输出 array([0]),意味着不买的可能性比较大本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



