
Machine Learning (7) - 关于 Logistic Regression (Binary Classification) 的小练习
0 / 0 / 创建于 7年前 /
 Rachel 的个人博客
Rachel 的个人博客
题目: 帮助 HR 做员工去留分析
第一步:处理数据
1. 引入基础数据
import pandas as pd
from matplotlib import pyplot as plt
%matplotlib inline
df = pd.read_csv('/Users/rachel/Downloads/py-master/ML/7_logistic_reg/Exercise/HR_comma_sep.csv')
df.head()输出:

上表中的各个列就是对员工多维度的数据统计, 最终体现员工去留的就是 left 列, left 列的值只有 0 和 1, 0 表示留下, 1 表示离开.
首先根据现有数据分析哪些维度会对员工的去留(也就是 left 列的值)产生比较大的影响.
2. 查看整个表中员工的去留人数分别是多少
// 查看数据中离开员工的人数
left = df[df.left==1]
left.shape输出:
(3571, 10)dataframe 的 shape 属性可以查看整个 dataframe 共有多少行多少列,所以这里就是 3571行 * 10列。也即是说,共有 3571位员工离开。
// 查看数据中留下员工的人数
retained = df[df.left==0]
retained.shape输出:
(11428, 10)表示共有 11428 位员工留下来。
3. 分析真正影响员工去留的字段
根据 left 字段进行分组, 并取平均值
df.groupby('left').mean()输出:

利用 pandas 的 crosstab 函数分析 salary 对 left 值的影响, 再以柱形图输出
pd.crosstab(df.salary, df.left).plot(kind='bar')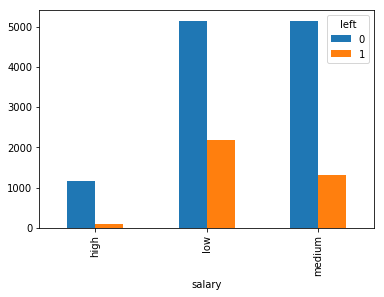
从结果可以看出高工资的人留下来的占比比较大.
利用 pandas 的 crosstab 函数分析 Department 对 left 值的影响, 再以柱形图输出
pd.crosstab(df.Department, df.left).plot(kind='bar')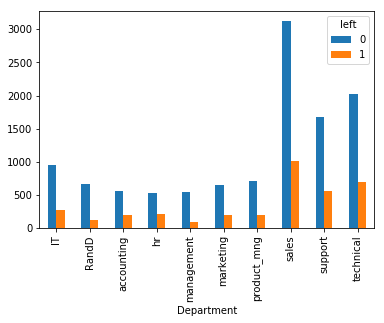
从结果可以看出部门对 left 值的影响不是很明显
以上分析了各个字段对 left 值的影响, 最后总结以下几个字段对 left 值的影响比较大, 所以后面将通过这些字段来训练数据模型。
4. 保留有用字段生成新的 dataframe
df_new = df[['satisfaction_level', 'average_montly_hours', 'Work_accident', 'promotion_last_5years', 'salary']]
df_new.head()输出: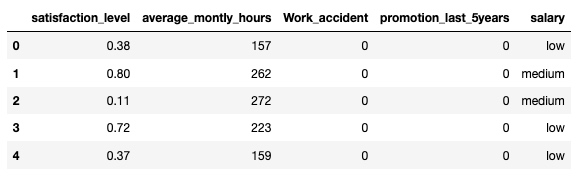
5. 通过 pandas 的 get_dummies 函数把 salary 列数字化
salary_dummies = pd.get_dummies(df.salary, prefix='salary')
df_with_dummies = pd.concat([df_new, salary_dummies], axis='columns')
df_with_dummies.head()输出:
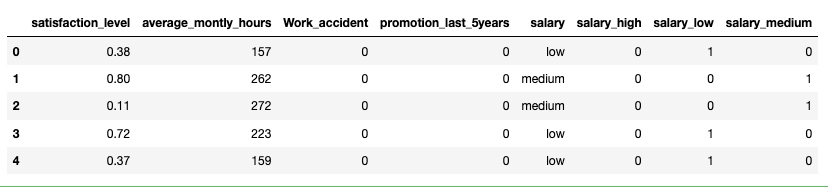
// 去掉 salary 列
df_with_dummies.drop('salary', axis='columns', inplace=True)
df_with_dummies.head()输出:
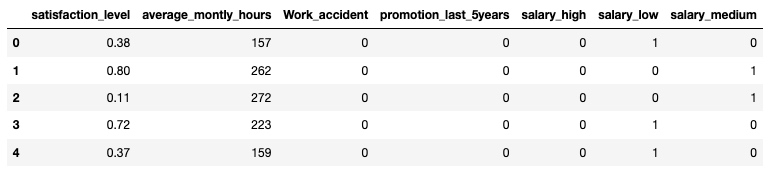
// 去掉 salary_medium 列
df_with_dummies.drop('salary_medium',axis='columns', inplace=True)
df_with_dummies.head()输出:
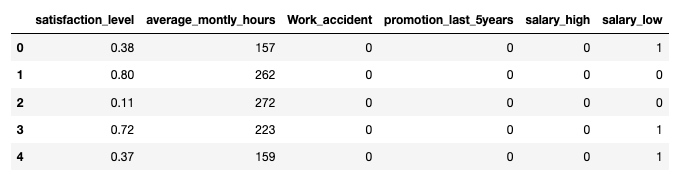
6. 准备用于训练模型的数据
X = df_with_dummies
X.head()输出:
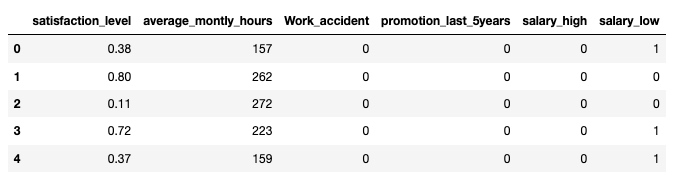
y = df.left
y.head()输出:
0 1
1 1
2 1
3 1
4 1
Name: left, dtype: int64
第二步:训练模型
1. 取出 20% 数据做测试用
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)2. 使用 LogisticRegression 训练模型
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)3. 分析模型准确度
model.score(X_test, y_test) // 输出 0.7773333333333333本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu




推荐文章: