
Machine Learning (8) - Logistic Regression (Multiclass Classification)
0 / 0 / 创建于 7年前
 Rachel 的个人博客
Rachel 的个人博客
引言

上一节我们重点关注了 binary classification, 也就是预测结果非是则非,这一节我们来学习多种分类值的模型。
正文

我们通过识别手写数字的例子, 学习 Multiclass Classification。需要借助 The Digit Dataset 的数据集, 它是由 1797 个 8*8 的图像组成的。如下图所示, 每一个图像都是一个手写数字。也就是说, 我们通过这个数据集, 可以获得 1797 条数据用来训练模型。

与 binary classification 的不同之处在于, 这里获得的结果不是 yes or no 的二选一, 而是数字从 0-9 的 10 种分类.
第一步:引入数据, 并对其特性做简单的了解
%matplotlib inline
import matplotlib.pyplot as plt
// 引入 load_digits 数据集
from sklearn.datasets import load_digits
digits = load_digits()
// 查看这个数据集都有哪些属性
dir(digits)
// 输出
['DESCR', 'data', 'images', 'target', 'target_names']
digits.data
// 输出
array([[ 0., 0., 5., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 10., 0., 0.],
[ 0., 0., 0., ..., 16., 9., 0.],
...,
[ 0., 0., 1., ..., 6., 0., 0.],
[ 0., 0., 2., ..., 12., 0., 0.],
[ 0., 0., 10., ..., 12., 1., 0.]])
// 查看这个数据集的整体结构, 从输出可以看到这是一个二维数组, 一共是有 1797 条数据, 每条数据由 64 个数字组层
digits.data.shape // 输出 (1797, 64)
// 查看二维数据的第一个, 也就是代表了第一个数字
digits.data[0]
// 输出
array([ 0., 0., 5., 13., 9., 1., 0., 0., 0., 0., 13., 15., 10.,
15., 5., 0., 0., 3., 15., 2., 0., 11., 8., 0., 0., 4.,
12., 0., 0., 8., 8., 0., 0., 5., 8., 0., 0., 9., 8.,
0., 0., 4., 11., 0., 1., 12., 7., 0., 0., 2., 14., 5.,
10., 12., 0., 0., 0., 0., 6., 13., 10., 0., 0., 0.])
// 再来看下 images 属性, 输出前 4 个数字看看
for i in range(4):
plt.matshow(digits.images[i])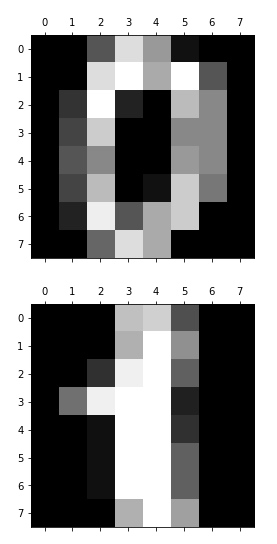
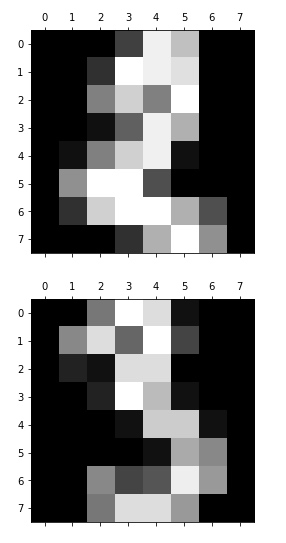
// target 属性, 也就是 data 里一堆数字到底是代表数字几
digits.target[0:4] // 输出 array([0, 1, 2, 3])
digits.target_names[0:4] // 输出 array([0, 1, 2, 3])第二步:准备训练模型
// 按照 20% 测试数据的比例, 把数据集分为训练数据和测试数据
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target, test_size = 0.2)
len(X_train) // 输出 1437
len(X_test) // 输出 360
// 训练模型
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
// 查看模型准确度
model.score(X_test, y_test) // 输出 0.9777777777777777以上, 就是借助于 load_digits 数据集完成了对 multiclass 模型的训练, 并且得出了精确度还比较准确. 如果想更加细致地了解误差的位置, 可以通过 confusion_matrix 类实现:
y_predicted = model.predict(X_test)
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_predicted)
cm
// 输出
array([[36, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 45, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 36, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 39, 0, 0, 0, 0, 0, 0],
[ 0, 1, 0, 0, 27, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 35, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 36, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 34, 0, 1],
[ 0, 2, 0, 0, 0, 1, 0, 0, 26, 1],
[ 0, 0, 0, 0, 0, 0, 0, 2, 0, 38]])为了将上面的输出可视化更强, 引入 seaborn 包, 需要在终端安装 pip3 install seaborn
import seaborn as sn
plt.figure(figsize = (10, 7))
sn.heatmap(cm, annot=True)
plt.xlabel('Predicted')
plt.ylabel('Truth')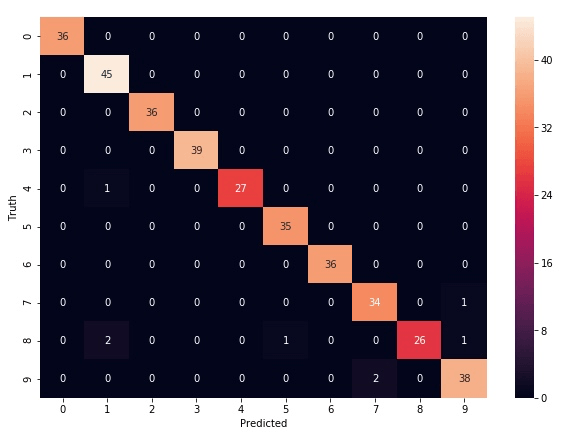
简单解释这个图表:
x 轴是预测的值, y 轴是实际的值
以左上角的 36 为例, 表示一共有 36 个数字 0 (看 y 轴), 而预测的也都是数字 0 (x 轴), 表示对 0 的预测没有误差.
再看最下面一行的 2, 表示有两个数字 9 (y 轴) 被预测成了数字 7 (x 轴), 也就是说在数字 9 的预测上有两个错误.
这个表上所有数字加起来正好是 360, 也就是测试数据的数据量.
这就非常直观地看出我们这个数据模型的准确度表现了.
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



