
Machine Learning (10) - Decision Tree
0 / 0 / 创建于 7年前
 Rachel 的个人博客
Rachel 的个人博客
引言
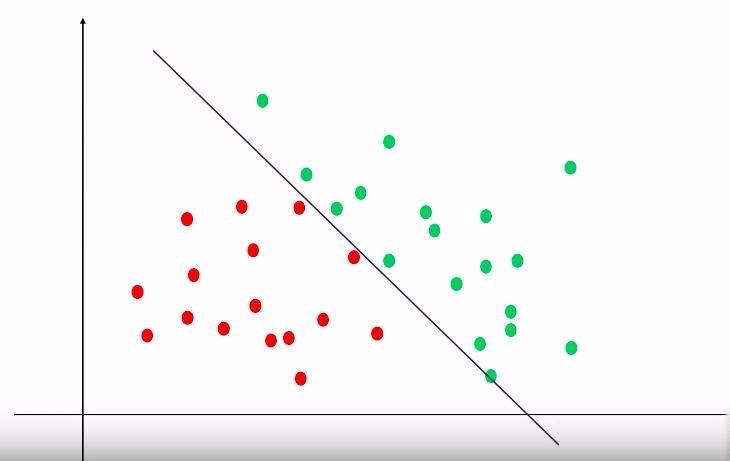
对于上图这样一个数据集,我们可以很容易地使用 Logistic Regression 来画出这条分界线。
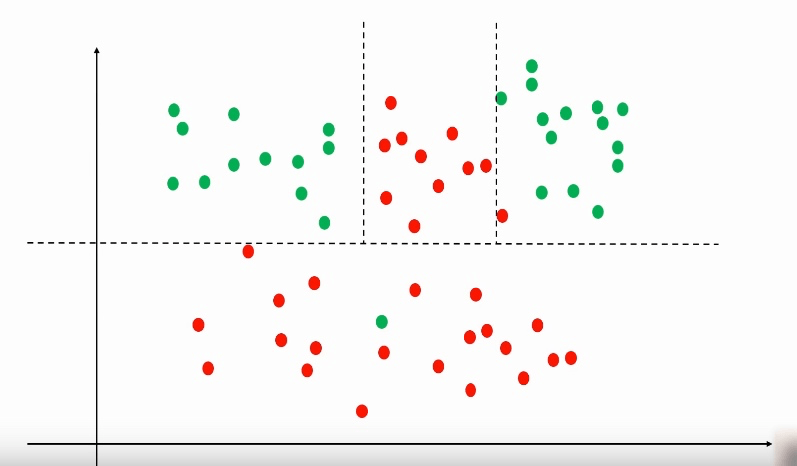
但是,对于一些数据分布更加随意的数据集, 就要像下图一样,需要多条线来做分割,才能做到比较准确的分类。这时我们就需要 Desision Tree Algorithm 来帮我们完成这个工作。
应用场景
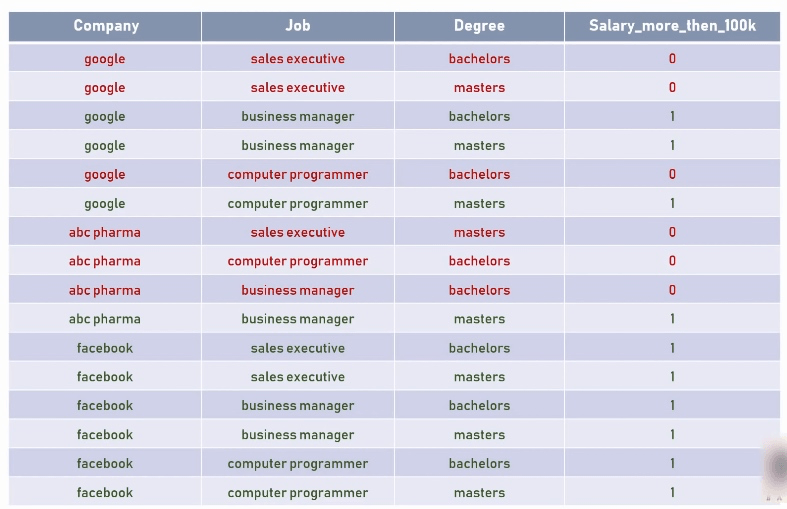
从公司, 职位, 学历三个维度衡量工资水平是否超过 100k,以下是草料:
拿到这个需求, 首先都会在脑海里做一个树形分类:
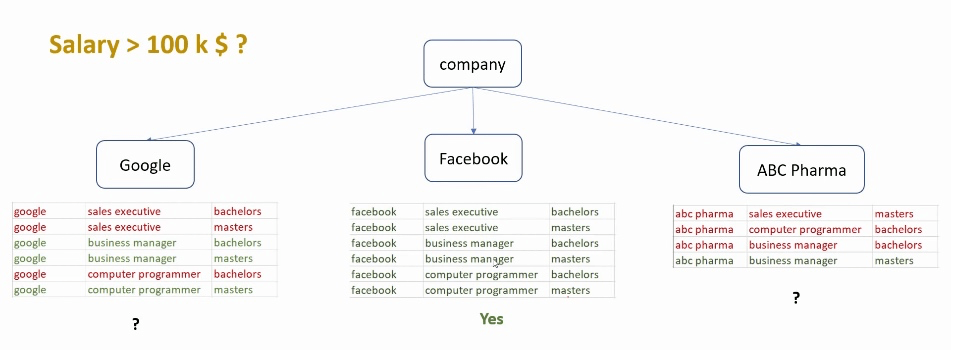
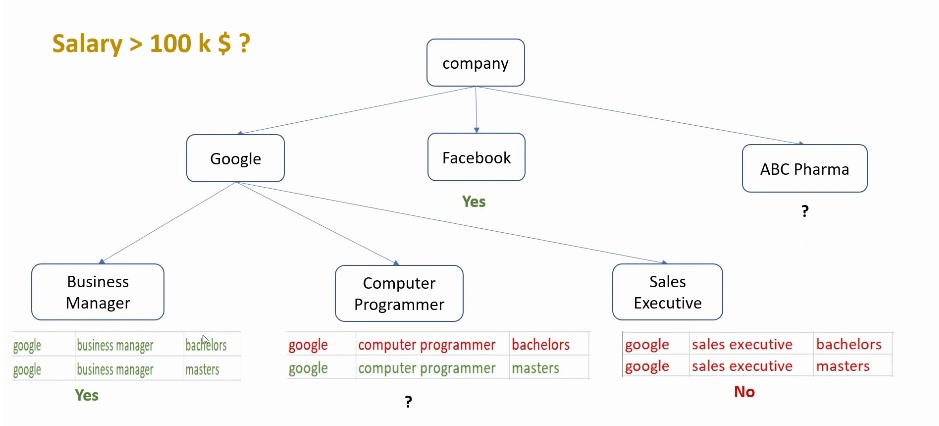
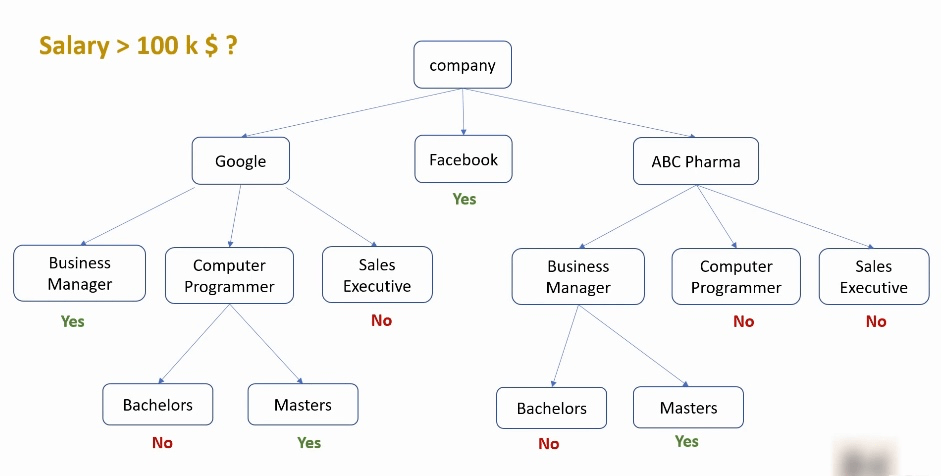
上面是以公司作为总维度来划分的, 还可以尝试以学历为总维度来划分, 都会得到不一样的效果:
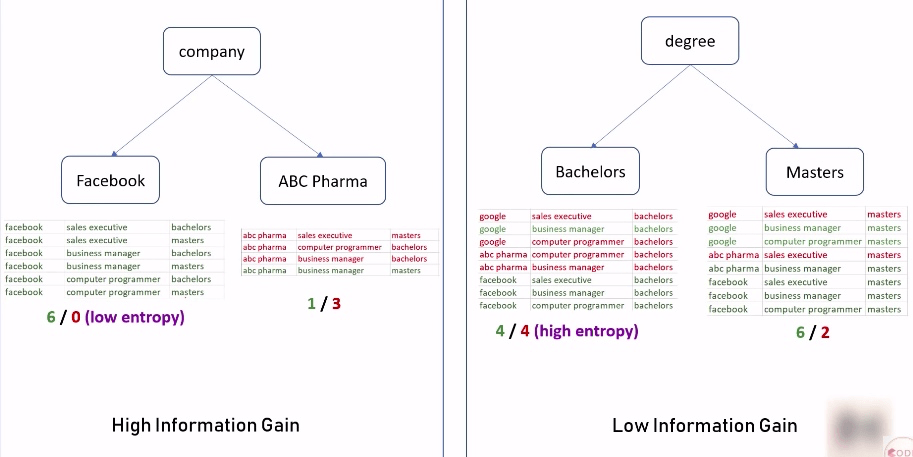
但其实目前的数据是相对来说, 非常简单的, 在实际应用中, 这个树可能会有50层那么高, 那就很难这样呈现了. 所以这里就可以用DecisionTreeClassifier 来完成这个工作.
如何使用
引入数据文件
import pandas as pd
df = pd.read_csv('/Users/rachel/Downloads/py-master/ML/9_decision_tree/salaries.csv')
df
转换非数字列
由于 Machine Learning 只支持对数字的分析, 所以要把 company, job 和 degree 列的数据都转成数字。这里用的是 LabelEncoder, 虽然像 company 和 job 列都是 nominal 而非 ordinary, 但是由于我们要用的是 DecisionTreeClassifier, 所以可以用 LabelEncoder。
from sklearn.preprocessing import LabelEncoder
le_company = LabelEncoder()
le_job = LabelEncoder()
le_degree = LabelEncoder()
dfle = df
dfle.company = le_company.fit_transform(dfle.company)
dfle.job = le_job.fit_transform(dfle.job)
dfle.degree = le_degree.fit_transform(dfle.degree)
dfle.head()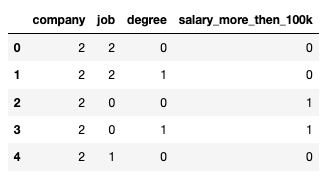
整理用于训练模型的数据
inputs = dfle.drop('salary_more_then_100k', axis = 'columns')
target = dfle['salary_more_then_100k']
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(inputs, target, test_size = 0.3)训练模型
from sklearn import tree
model = tree.DecisionTreeClassifier()
model.fit(X_train, y_train)本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu



