
Machine Learning (11) - 关于 Decision Tree 的小练习
0 / 0 / 创建于 7年前
 Rachel 的个人博客
Rachel 的个人博客
题目
以泰坦尼克号的人员名单为草料,从多个维度值决定一个人是否会遇难。目前我们手上有一份真实的泰坦尼克号的所有人员名单,其中有一列是 Survived, 也就是此人是否遇难。现在的要求是,根据 Pclass,Fare,Age,Sex 列的值来训练模型。
正文
引入数据
import pandas as pd
df = pd.read_csv('/Users/rachel/Sites/pandas/py/ML/9_decision_tree/Exercise/titanic.csv')
df.head()输出

去掉对是否生还结果没有影响的字段
df = df.drop(['PassengerId', 'Name', 'SibSp', 'Parch', 'Ticket','Cabin','Embarked'], axis = 'columns')
df.head()输出:
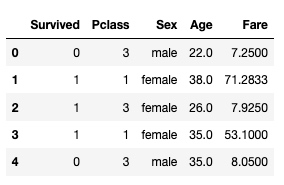
把非数字列的值转为数字
from sklearn.preprocessing import LabelEncoder
le_sex = LabelEncoder()
df.Sex = le_sex.fit_transform(df.Sex)
df.head()输出:
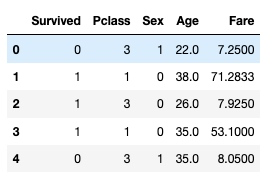
取出用于训练的 X 列
input = df.drop('Survived', axis = 'columns')
input[:10]输出:
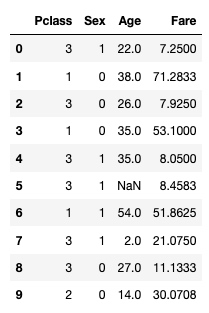
用平均值填充 NAN
input = input.fillna(input.Age.median())
input[:10]输出:
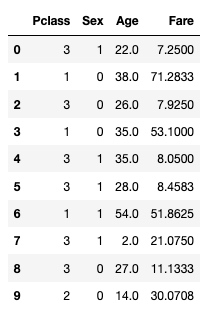
划分训练数据和测试数据
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(input, target, test_size = 0.2)训练模型
from sklearn import tree
model = tree.DecisionTreeClassifier()
model.fit(X_train, y_train)
model.score(X_test, y_test) // 输出: 0.7821229050279329本作品采用《CC 协议》,转载必须注明作者和本文链接




 关于 LearnKu
关于 LearnKu




推荐文章: