
Machine Learning (12) - Support Vector Machine (SVM)
0 / 0 / 创建于 6年前
 Rachel 的个人博客
Rachel 的个人博客
引言
Support Vector Machine 简称 SVM, 是一种非常常用的分类算法。
下图是著名的 Iris 花, 相信大家已经不陌生了。它一共有 3 个品种,由 petal 花瓣的宽度和长度和 sepal 花瓣的宽度和长度 4 个特征,决定了每朵花的品种。

首先下面只是简单地从 Petal 的 Length 和 Width 两个维度做划分,可以看到明显地分出 Setosa 和 Versicolor 两个品种的花。然而,两种花的分界线要如何画呢,看似有很多种画法,哪条才是最佳的呢?

当然是选一条离每个离每个临界点都最远的线是最佳方案。这些边界点被称为 Support Vectors, 而 SVM 就可以帮我们画出这条最佳的分割线。
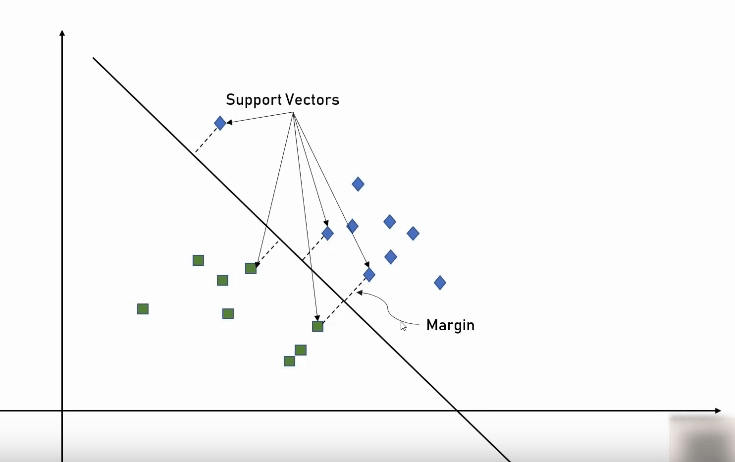
SVM 算法的作用是对由 n 个维度构成的数据进行划分, 也就是做数据分类, 比如对于二维属性的数据, 想将两类数据分开, 就需要一条线, 对于三维属性的数据, 就需要一个面, 那么 n 维属性呢(这在实际应用中是非常常见的, 比如 iris 花的种类就是分别由两种花瓣各自的长宽值决定的, 也就是 4 个维度), 我们把它称作做超面.

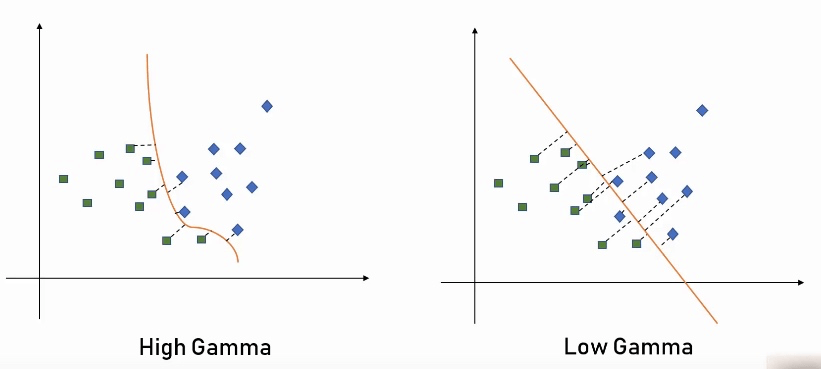
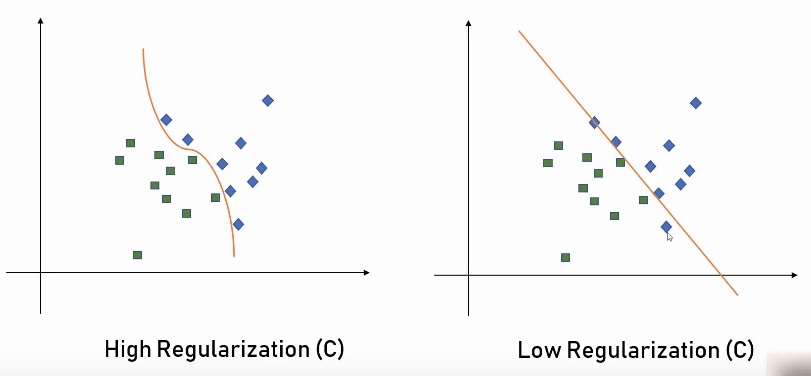
在 SVM 模型中, 线和面的形状都是可以通过参数来调节, 从而达到最大的准确度。比如下图中的 gamma 和 regularization 都是在训练模型时可调的参数。
比如有如下的一个数据集:
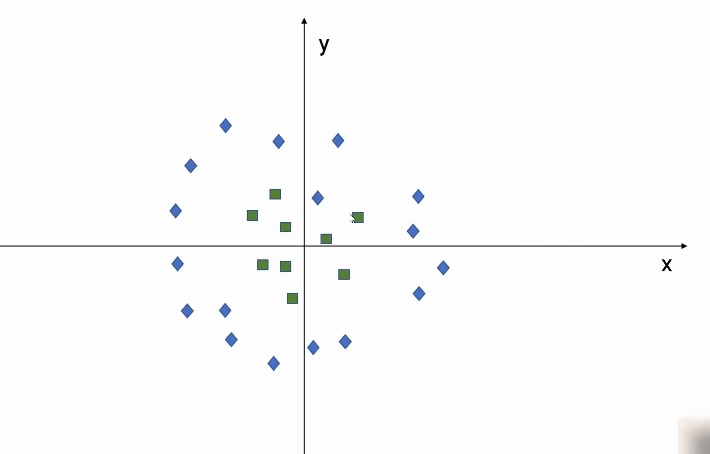
我们发现,如果单从 x 轴 和 y 轴的维度,很难对数据做划分,所以可以增加一个 z 轴,将数据做一下转换,从而可以轻松地将数据分类:
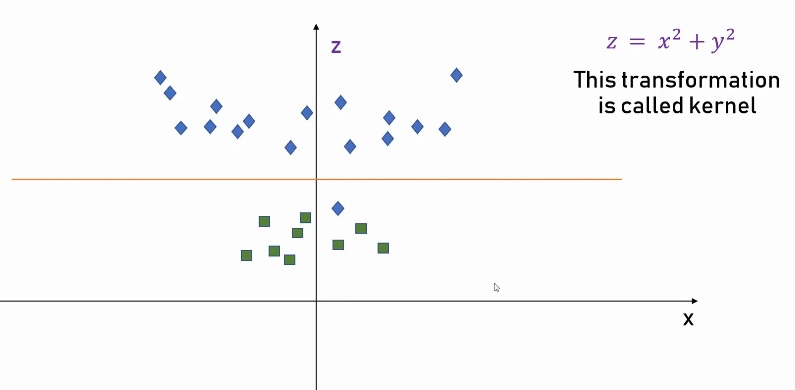
正文
引入并分析 The Iris Dataset 数据
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
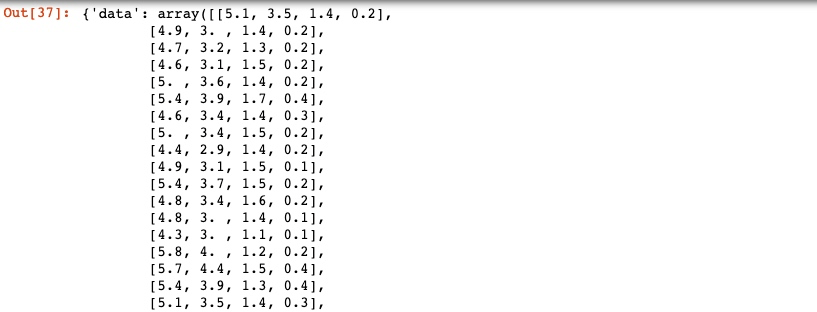
iris输出:
这里只截取了 data 属性的部分数据(在 jupyter 中向下拉, 还可以看到 iris 的其他属性), 可以看出 data 是一个二维数组.
利用 pandas 将这个二维数组转成 dataframe, 设置列名为它的 feature_names 属性, 也就是两种花瓣的长和宽
df = pd.DataFrame(iris.data, columns = iris.feature_names)
df.head()输出:
把 iris 的 target 属性加入 dataframe:
df['target'] = iris.target
df.head()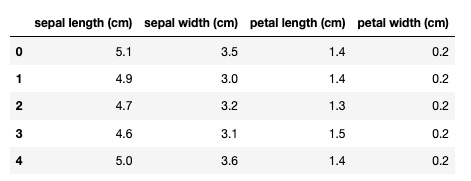
查看 target 为 2 的所有数据:
df[df.target == 2].head()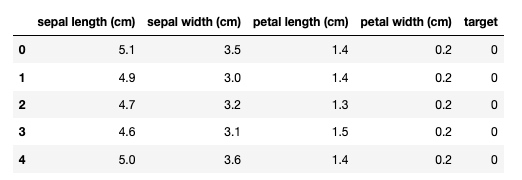
给这个 dataframe 增加 flower_name 列(也就是花的种类):
df['flower_name'] = df.target.apply(lambda x: iris.target_names[x])
df.head()
以上就是我们准备好的, 可以用于分析的数据, 下面根据花的品种, 将数据分成三份:
from matplotlib import pyplot as plt
%matplotlib inline
df0 = df[df.target == 0]
df1 = df[df.target == 1]
df2 = df[df.target == 2]
df0.head()
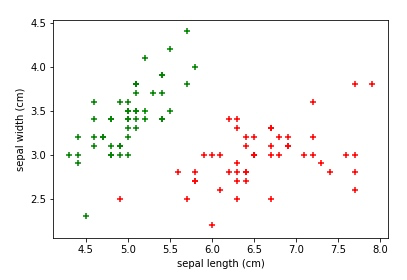
以图表的形式, 同时取第一种花和第三种花的 sepal 花瓣的长和宽输出:
plt.scatter(df0['sepal length (cm)'], df0['sepal width (cm)'],color='green', marker='+')
plt.scatter(df2['sepal length (cm)'], df2['sepal width (cm)'],color='red', marker='+')
plt.xlabel('sepal length (cm)')
plt.ylabel('sepal width (cm)')从下图中, 我们可以非常直观且明确地区分出这两种花
下面把第二种花的值也加上:
plt.scatter(df0['sepal length (cm)'], df0['sepal width (cm)'],color='green', marker='+')
plt.scatter(df1['sepal length (cm)'], df1['sepal width (cm)'],color='blue', marker='+')
plt.scatter(df2['sepal length (cm)'], df2['sepal width (cm)'],color='red', marker='+')
plt.xlabel('sepal length (cm)')
plt.ylabel('sepal width (cm)')我们发现每种花之间的分割线变得没那么容易画了, 尤其是在第二种(蓝)和第三种(红)之间, 出现了混合现象, 也就是说, 在指定 sepal 花瓣的长宽值的情况下, 我们并不容易区分出这是哪种花.
不过, 我们可以根据现有的数据来训练 SVM 模型, 通过调节参数, 建立一个比较准确的模型.
训练模型
from sklearn.model_selection import train_test_split
X = df.drop(['target', 'flower_name'], axis='columns')
X.head()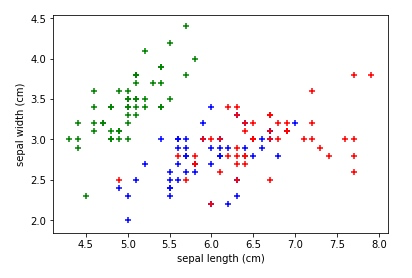
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
// 引入模型
from sklearn.svm import SVC
model = SVC(C = 100) // 这里就可以传参, 来微调模型的准确度
model.fit(X_train, y_train)
//输出, 这些参数都是可以用来微调模型的准确度的
SVC(C=100, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto_deprecated',
kernel='rbf', max_iter=-1, probability=False, random_state=None,
shrinking=True, tol=0.001, verbose=False)
// 测试模型准确度
model.score(X_test, y_test)
//输出
0.9666666666666667本作品采用《CC 协议》,转载必须注明作者和本文链接



 关于 LearnKu
关于 LearnKu



