
知识分享--云原生
4 / 0 / 创建于 6年前 /
 Shine-x 的个人博客
Shine-x 的个人博客
Docker
K8S
istio
consul
Consul架构介绍
High-Level 架构
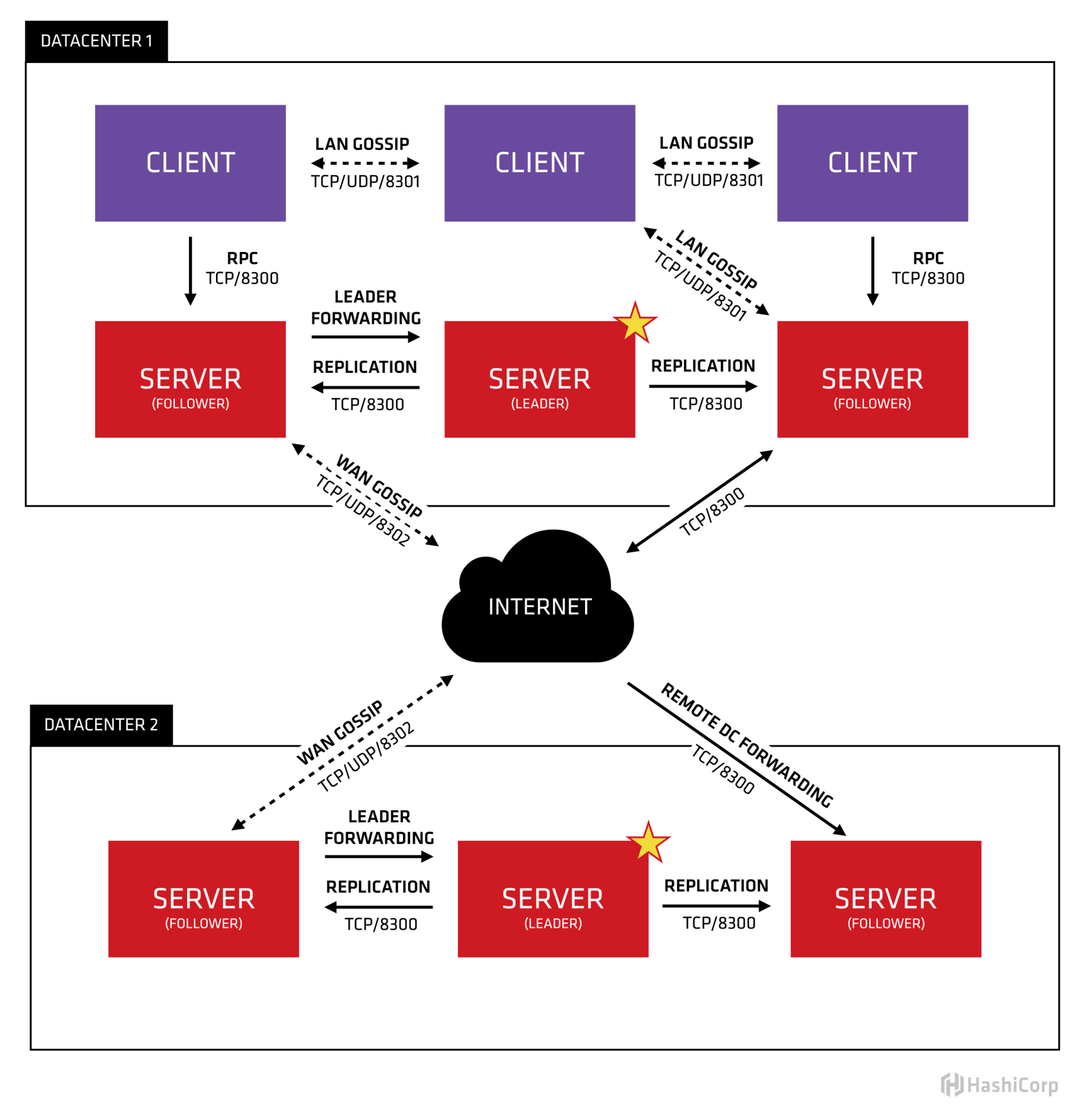
- 一个显著特点是可以跨数据中心进行状态和其他数据同步,同步的协议是gossip
- Consul集群之间的数据一致性协议通过基于Raft算法的Consensus协议完成, Consul一致性是CP模式
不同注册中心对比
| Feature | Consul | Zookeeper | Etcd | Eureka |
|---|---|---|---|---|
| 服务健康检查 | 服务状态,内存,硬盘等 | (弱)长连接,keepalive | 连接心跳 | 可配支持 |
| 多数据中心 | 支持 | — | — | — |
| kv存储服务 | 支持 | 支持 | 支持 | — |
| 一致性 | raft | paxos | raft | — |
| CAP定理 | CA (应为CP) | CP | CP | AP |
| 使用接口(多语言能力) | 支持http和dns | 客户端 | http/grpc | http(sidecar) |
| watch支持 | 全量/支持long polling | 支持 | 支持 long polling | 支持 long polling/大部分增量 |
| 自身监控 | metrics | — | metrics | metrics |
| 安全 | acl /https | acl | https支持(弱) | — |
| Spring Cloud集成 | 已支持 | 已支持 | 已支持 | 已支持 |
- 服务的健康检查
Euraka 使用时需要显式配置健康检查支持;Zookeeper,Etcd 则在失去了和服务进程的连接情况下任务不健康,而 Consul 相对更为详细点,比如内存是否已使用了90%,文件系统的空间是不是快不足了。
prometheus
grafana
API Gateway
在选择API Gateway的时候,要面向未来,综合考虑性能,易用性和生态体系,总结一下目前的在CNCF Cloud Native Interactive Landscape中出现的API Gateway, 主要分以下几类:
- 基于Nginx和OpenResty的
- APISIX
- Kong
- 3Scale
- Java
- Sentinel
- Mule
- Go
- Krakend
- traefik
- Tyk
- Ambassador
- Gloo
- Other
- Express gateway
- Reactive Interaction Gateway
Service Mesh
zookeeper
Leader选举是保证分布式数据一致性的关键所在。当Zookeeper集群中的一台服务器出现以下两种情况之一时,需要进入Leader选举。
- (1) 服务器初始化启动。
- (2) 服务器运行期间无法和Leader保持连接。
下面就两种情况进行分析讲解。
1. 服务器启动时期的Leader选举
若进行Leader选举,则至少需要两台机器,这里选取3台机器组成的服务器集群为例。在集群初始化阶段,当有一台服务器Server1启动时,其单独无法进行和完成Leader选举,当第二台服务器Server2启动时,此时两台机器可以相互通信,每台机器都试图找到Leader,于是进入Leader选举过程。
选举过程如下
- (1) 每个Server发出一个投票。由于是初始情况,Server1和Server2都会将自己作为Leader服务器来进行投票,每次投票会包含所推举的服务器的myid和ZXID,使用(myid, ZXID)来表示,此时Server1的投票为(1, 0),Server2的投票为(2, 0),然后各自将这个投票发给集群中其他机器。
- (2) 接受来自各个服务器的投票。集群的每个服务器收到投票后,首先判断该投票的有效性,如检查是否是本轮投票、是否来自LOOKING状态的服务器。
- (3) 处理投票。针对每一个投票,服务器都需要将别人的投票和自己的投票进行PK,PK规则如下
- · 优先检查ZXID。ZXID比较大的服务器优先作为Leader。
- · 如果ZXID相同,那么就比较myid。myid较大的服务器作为Leader服务器。
对于Server1而言,它的投票是(1, 0),接收Server2的投票为(2, 0),首先会比较两者的ZXID,均为0,再比较myid,此时Server2的myid最大,于是更新自己的投票为(2, 0),然后重新投票,对于Server2而言,其无须更新自己的投票,只是再次向集群中所有机器发出上一次投票信息即可。
- (4) 统计投票。每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到相同的投票信息,对于Server1、Server2而言,都统计出集群中已经有两台机器接受了(2, 0)的投票信息,此时便认为已经选出了Leader。
- (5) 改变服务器状态。一旦确定了Leader,每个服务器就会更新自己的状态,如果是Follower,那么就变更为FOLLOWING,如果是Leader,就变更为LEADING。
2. 服务器运行时期的Leader选举
在Zookeeper运行期间,Leader与非Leader服务器各司其职,即便当有非Leader服务器宕机或新加入,此时也不会影响Leader,但是一旦Leader服务器挂了,那么整个集群将暂停对外服务,进入新一轮Leader选举,其过程和启动时期的Leader选举过程基本一致
假设正在运行的有Server1、Server2、Server3三台服务器,当前Leader是Server2,若某一时刻Leader挂了,此时便开始Leader选举。选举过程如下
- (1) 变更状态。Leader挂后,余下的非Observer服务器都会讲自己的服务器状态变更为LOOKING,然后开始进入Leader选举过程。
- (2) 每个Server会发出一个投票。在运行期间,每个服务器上的ZXID可能不同,此时假定Server1的ZXID为123,Server3的ZXID为122;在第一轮投票中,Server1和Server3都会投自己,产生投票(1, 123),(3, 122),然后各自将投票发送给集群中所有机器。
- (3) 接收来自各个服务器的投票。与启动时过程相同。
- (4) 处理投票。与启动时过程相同,此时,Server1将会成为Leader。
- (5) 统计投票。与启动时过程相同。
- (6) 改变服务器的状态。与启动时过程相同。
出处:北京英浦教育
本作品采用《CC 协议》,转载必须注明作者和本文链接







 关于 LearnKu
关于 LearnKu




推荐文章: