
知识分享--数据库
6 / 1 / 创建于 6年前 /
 Shine-x 的个人博客
Shine-x 的个人博客
MySQL
MySQL中的索引
索引
索引常见的几种类型
索引常见的类型有哈希索引,有序数组索引,二叉树索引,跳表等等。主要探讨 MySQL 的默认存储引擎 InnoDB 的索引结构。
InnoDB的索引结构
有两种常用的索引, B+ 树索引和Hash索引
为什么使用B+Tree?
- 索引的常见模型常见的有,哈希表、有序数组、搜索树。
- 有序数组,优点是等值查询,范围查询都非常快,缺点也很明显,就是插入效率太低,因为如果从中间插入,要移动后面所有的元素。
- 在B+树中是只有叶子结点会存储数据,而且所有叶子结点会形成一个链表。而在InnoDB中维护的是一个双向链表。
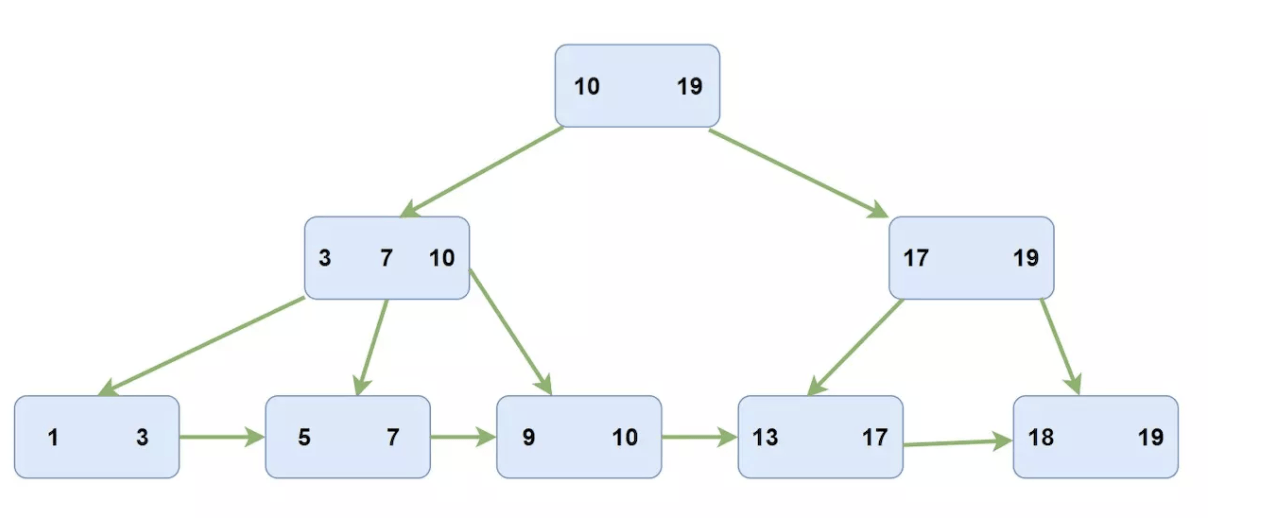
- 哈希结构只适用于等值查询(但这样速度非常快)。哈希结构不支持顺序检索例如’<’、’>’、”between and”等,这种存储结构属于“键值”查询,符合这种需求可以考虑使用哈希索引。
- 优化器不能使用哈希索引来加快 order by 操作。(此类型的索引不能用于按顺序搜索下一个条目。
- mysql 不能大致确定两个值之间有多少行 (范围优化器使用它来决定要使用哪个索引)。如果将 MyISAM 或 InnoDB 表更改为哈希索引的内存表, 这可能会影响某些查询。
为什么使用 B+树 而不使用二叉树或者B树?
首先,我们知道访问磁盘需要访问到指定块中,而访问指定块是需要 盘片旋转 和 磁臂移动 的,这是一个比较耗时的过程,如果增加树高那么就意味着你需要进行更多次的磁盘访问,所以会采用n叉树。而使用B+树是因为如果使用B树在进行一个范围查找的时候每次都会进行重新检索,而在B+树中可以充分利用叶子结点的链表。
在建表的时候你可能会添加多个索引,而 InnDB 会为每个索引建立一个 B+树 进行存储索引。
建立一个简单的测试表
create table test(
id int primary key,
a int not null,
name varchar,
index(a)
)engine = InnoDB;这个时候 InnDB 就会为我们建立两个 B+索引树
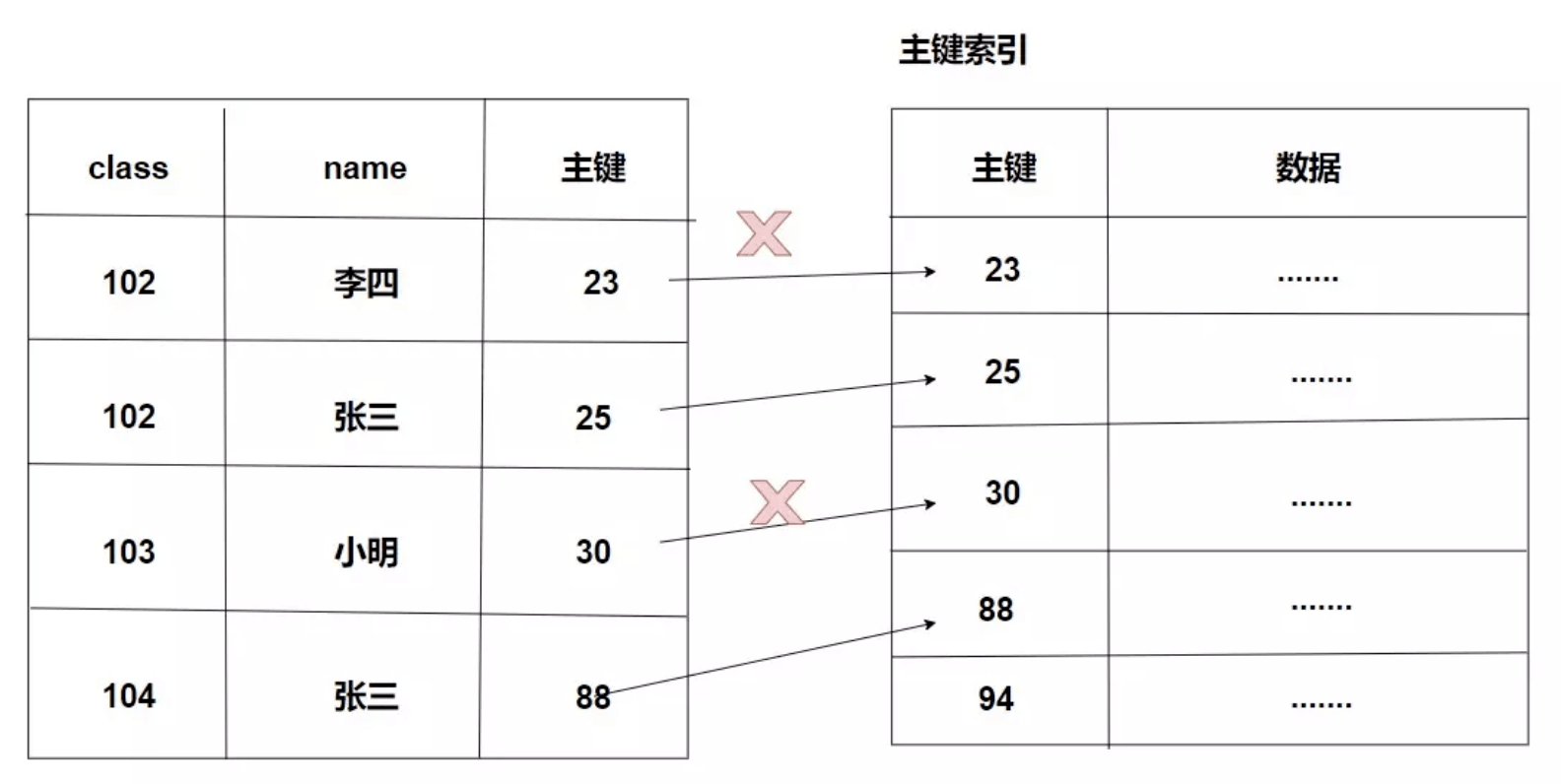
一个是 主键 的 聚簇索引,另一个是 普通索引 的 辅助索引,这里引用 MySQL浅谈(索引、锁)
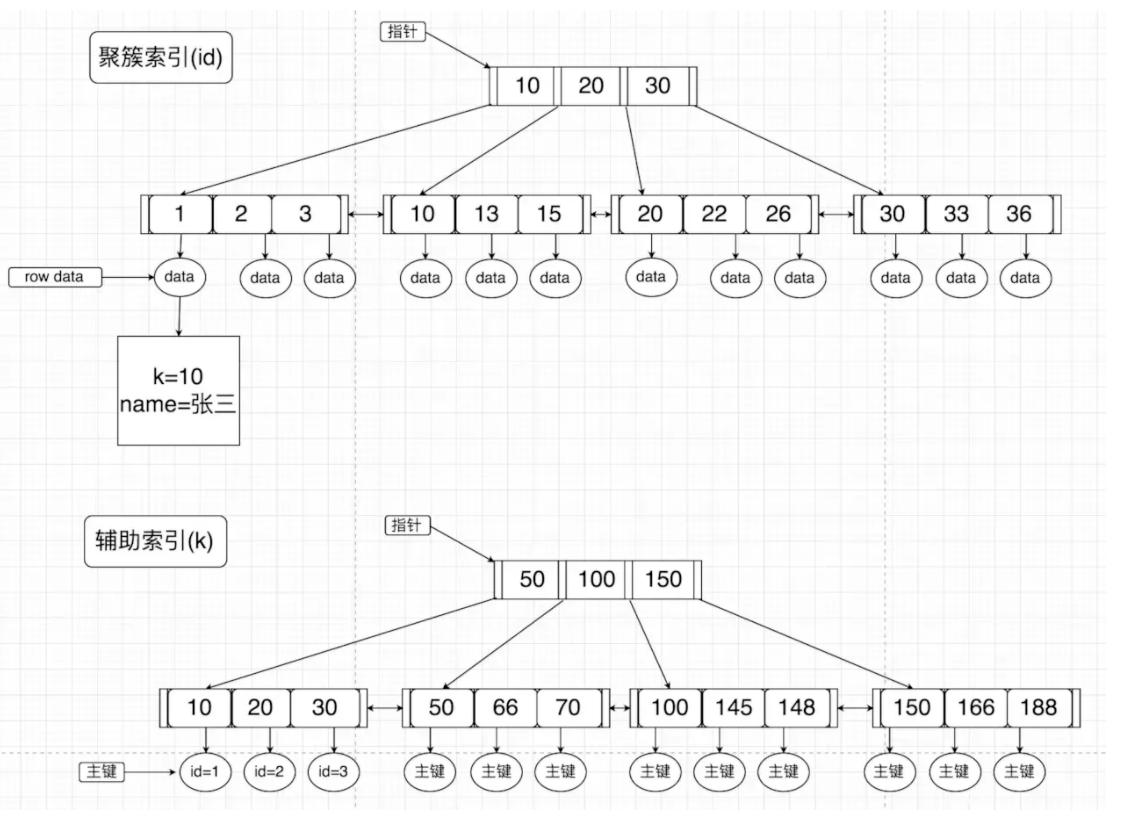
可以看到在辅助索引上面的叶子节点的值只是存了主键的值,而在主键的聚簇索引上的叶子节点才是存上了整条记录的值。
回表
这里就会引申出一个概念叫回表,比如这个时候我们进行一个查询操作
select name from test where a = 30;因为条件 MySQL 是会走 a 的索引的,但是 a 索引上并没有存储 name 的值,此时我们就需要拿到相应 a 上的主键值,然后通过这个主键值去走 聚簇索引 最终拿到其中的name值,这个过程就叫回表。
我们来总结一下回表是什么?MySQL在辅助索引上找到对应的主键值并通过主键值在聚簇索引上查找所要的数据就叫回表。
索引维护
- 我们知道索引是需要占用空间的,索引虽能提升我们的查询速度但是也是不能滥用。
- 比如我们在用户表里用身份证号做主键,那么每个二级索引的叶子节点占用约20个字节,而如果用整型做主键,则只要4个字节,如果是长整型(bigint)则是8个字节。也就是说如果我用整型后面维护了4个g的索引列表,那么用身份证将会是20个g。
- 所以我们可以通过缩减索引的大小来减少索引所占空间。
- 当然B+树为了维护索引的有序性会在删除,插入的时候进行一些必要的维护(在InnoDB中删除会将节点标记为“可复用”以减少对结构的变动)。
- 比如在增加一个节点的时候可能会遇到数据页满了的情况,这个时候就需要做页的分裂,这是一个比较耗时的工作,而且页的分裂还会导致数据页的利用率变低,比如原来存放三个数据的数据页再次添加一个数据的时候需要做页分裂,这个时候就会将现有的四个数据分配到两个数据页中,这样就减少了数据页利用率。
覆盖索引
有时候我们查辅助索引的时候就已经满足了我们需要查的数据,这个时候 InnoDB 就会进行一个叫 覆盖索引 的操作来提升效率,减少回表。
比如这个时候我们进行一个 select 操作
select id from test where a = 1;这个时候很明显我们走了 a 的索引直接能获取到 id 的值,这个时候就不需要进行回表,我们这个时候就使用了 覆盖索引。
简单来说 覆盖索引 就是当我们走辅助索引的时候能获取到我们所需要的数据的时候不需要再次进行回表操作的操作。
联合索引
新建一个学生表
CREATE TABLE `stu` (
`id` int(11) NOT NULL,
`class` int(11) DEFAULT NULL,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `class_name` (`class`,`name`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 假如这个时候我们有一个需求,我们需要通过班级号去找对应的学生姓名,我们使用 class(班级号) 和 name 做一个 联合索引。
select name from stu where class = 102;这个时候我们就可以直接在 辅助索引 上查找到学生姓名而不需要再次回表。
总的来说,设计好索引,充分利用覆盖索引能很大提升检索速度。
最左前缀原则
以 联合索引 作为基础的,是一种联合索引的匹配规则。
我们有个学生迟到,但是他在门卫记录信息的时候只写了自己的名字张三而没有写班级,所以我们需要通过学生姓名去查找相应的班级号。
select class from stu where name = '张三';这个时候因为最左匹配原则我们就不会走我们的联合索引了,而是进行了全表扫描。
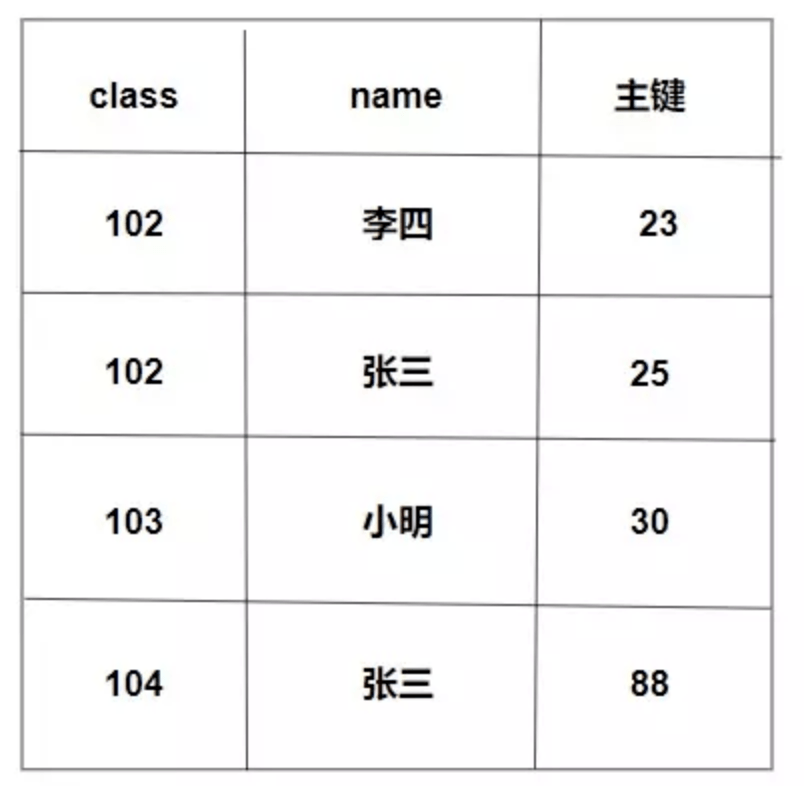
我们可以看到整个索引设计就是这么设计的,所以我们需要查找的时候也需要遵循着这个规则,如果我们直接使用name,那么InnoDB是不知道我们需要干什么的。
当然最左匹配原则还有这些规则
- 全值匹配的时候优化器会改变顺序,也就是说你全值匹配时的顺序和原先的联合索引顺序不一致没有关系,优化器会帮你调好。
- 索引匹配从最左边的地方开始,如果没有则会进行全表扫描,比如你设计了一个(a,b,c)的联合索引,然后你可以使用(a),(a,b),(a,b,c) 而你使用 (b),(b,c),(c)就用不到索引了。
- 遇到范围匹配会取消索引。比如这个时候你进行一个这样的 select 操作
select * from stu where class > 100 and name = '张三';这个时候 InnoDB 就会放弃索引而进行全表扫描,因为这个时候 InnoDB 会不知道怎么进行遍历索引,所以进行全表扫描。
索引下推
刚刚的操作在 MySQL5.6 版本以前是需要进行回表的,但是5.6之后的版本做了一个叫 索引下推 的优化。
select * from stu where class > 100 and name = '张三';如何优化的呢?因为刚刚的最左匹配原则我们放弃了索引,后面我们紧接着会通过回表进行判断 name,这个时候我们所要做的操作应该是这样的
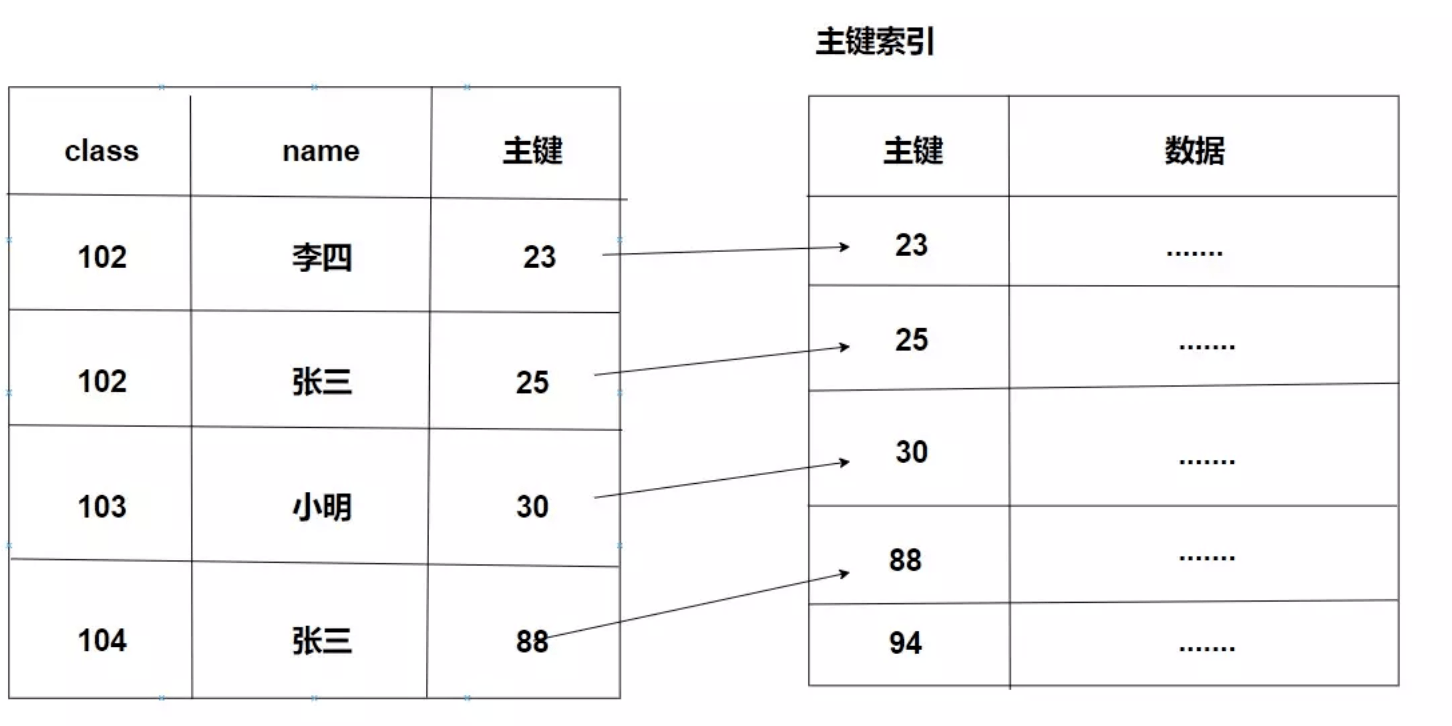
但是有了索引下推之后就变成这样了,此时 “李四” 和 “小明” 这两个不会再进行回表。
因为这里匹配了后面的name = 张三,也就是说,如果最左匹配原则因为范围查询终止了,InnoDB还是会索引下推来优化性能。
查询优化器
一条SQL语句的查询,可以有不同的执行方案,至于最终选择哪种方案,需要通过优化器进行选择,选择执行成本最低的方案。 在一条单表查询语句真正执行之前,MySQL的查询优化器会找出执行该语句所有可能使用的方案,对比之后找出成本最低的方案。这个成本最低的方案就是所谓的执行计划。 优化过程大致如下: 1、根据搜索条件,找出所有可能使用的索引 2、计算全表扫描的代价 3、计算使用不同索引执行查询的代价 4、对比各种执行方案的代价,找出成本最低的那一个
一些最佳实践
哪些情况需要创建索引?
- 频繁作为查询条件的字段应创建索引。
- 多表关联查询的时候,关联字段应该创建索引。
- 查询中的排序字段,应该创建索引。
- 统计或者分组字段需要创建索引。
哪些情况不需要创建索引
- 表记录少。
- 经常增删改查的表。
- 频繁更新的字段。
- where 条件使用不高的字段。
- 字段很大的时候。
其他
- 尽量选择区分度高的列作为索引。
- 不要对索引进行一些函数操作,还应注意隐式的类型转换和字符编码转换。
- 尽可能的扩展索引,不要新建立索引。比如表中已经有了a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
- 多考虑覆盖索引,索引下推,最左匹配。
MySQL备份
逻辑备份
逻辑备份用于备份数据库的结构(CREAET DATABASE、CREATE TABLE)和数据(INSERT),这种备份类型适合数据量小、跨SQL服务器、需要修改数据等场景。如
mysqldump命令就是产生一个逻辑备份工具,使用mysqldump输出的文件包含CREATE TABLE和INSERT语句,能够直接重建表内容和表结构。
使用逻辑备份有以下优势和劣势:
优势
- 可移植性高,SQL语句可直接适用于其他SQL服务器;
- 在数据恢复之前可增加、修改数据;
- 数据恢复粒度小可以是服务器、数据库、表级别;
- 使用文本格式,可读性高;
劣势
- 备份时需要访问mysql服务器,影响其他客户端;
- 需要将数据转换成逻辑格式(SQL,CSV);
- 如果命令运行在客户端,mysql服务器还需要将数据发送给客户端;
- 因为输出格式为文本文件,占用空间较大;
物理备份
物理备份是包括存储数据库内容的目录和文件的副本,这种类型的备份适用于需要在出现问题时快速恢复的大型重要数据库。
优势
- 完整的Mysql文件和目录备份,只需要复制文件不需要转换,速度比逻辑备份更快;
- 除了备份数据,还能备份配置文件和日志文件;
- 不需要运行Mysql服务器就可以完成备份;
- 备份工具简单使用cp、scp、tar命令即可完成备份;
劣势
- 可移植性不高,恢复数据只适用于相同或类似的机器上;
- 为了保持数据库文件的一致性,需要停机备份;
- 恢复粒度不能按表或用户恢复;
在线备份和离线备份
在线备份需要mysql服务器处理运行状态,以便备份工具从mysql服务器中获取数据。离线备份表示mysql服务器处理停止状态。两种备份形式也可以称为“热备份”和“冷备份“。
在线备份的主要特性
- 备份不需要停机,对其他客户端影响较小其他连接能够正常访问mysql服务器(依赖操作类型,如读操作);
- 备份需要加锁,以免在备份期间对数据做出修改;
离线备份的主要特性
- 备份期间服务器不可用;
- 备份过程更简单,不会受到客户端的干扰;
逻辑备份(mysqldump使用)
mysqldump属于逻辑备份命令,使用mysqldump备份的优势是它非常方便和灵活,可以直接编辑输出文件或者使用导入到其他的SQL服务器中去,但是它不能用作备份大量数据的快速解决方案,对于大数据量,即使备份花费的时候可以接受,但是恢复数据也可能会非常缓慢,因为执执行SQL语句会涉及磁盘I/O进行插入,创建索引等。
mysqldump的使用方式非常简单:
shell> mysqldump [options] db_name [tbl_name ...]
shell> mysqldump [options] --databases db_name ...
shell> mysqldump [options] --all-databases使用mysqldump备份时要注意:数据库的一致状态,在执行mysqldump命令时要保证数据不会再发生变更,保持数据的一致性有二种方法:
- 使Mysql服务器只读
- 使用事务加上隔离级别:
REPEATABLE READ
使用REPEATABLE READ事务隔离级别执行mysqldump命令(使用事务保持数据库的一致状态):
mysqldump --master-data=2 \
--flush-logs \
--single-transaction \
--all-databases > /backup/`date +%F-%H`-mysql-all.sql 备份参数说明:
- –master-data: 将二进制日志文件的名称和位置备份
- –flush-logs: 开始备份之前刷新mysql服务器日志文件
- –single-transaction:开始备份之前设置事务隔离级别为REPEATABLE READ然后发送一个START TRANSACTION命令。
- –all-databases:备份所有数据库
物理备份(复制原始文件)
为了保证复制文件的完整性,备份原始文件最好是停止mysql服务器,复制原始文件备份由以下步骤完成:
- 停止mysql服务器
$ mysqladmin shutdown- 使用合适的工具复制原始数据文件
$ tar cf /tmp/dbbackup.tar ./data- 备份完成后,运行mysql服务器
$ mysqld_safe
使用主从备份模式
使用
mysqldump和tar备份或多或少都会对业务产生影响,使用mysqldump备份需要对数据加锁,加锁就意味着其他客户端操作受到限制。使用tar命令需要停止服务器直接导致数据库服务器不可用,有没有办法能解决这两种问题呢?答案是有的,就是使用主从备份模式。
在单机的基础上增加一台Slave机器对Master机器的数据进行同步:
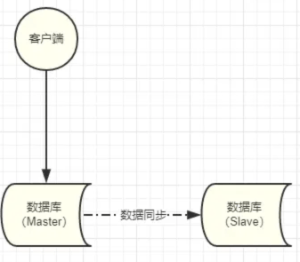
开始备份时对Slave进行备份,这样即使Slave停机或对数据加锁也不会影响业务的正常使用,如果公司有条件或业务非常重要可以选择这种方案来备份数据。
MySQL常见优化方式
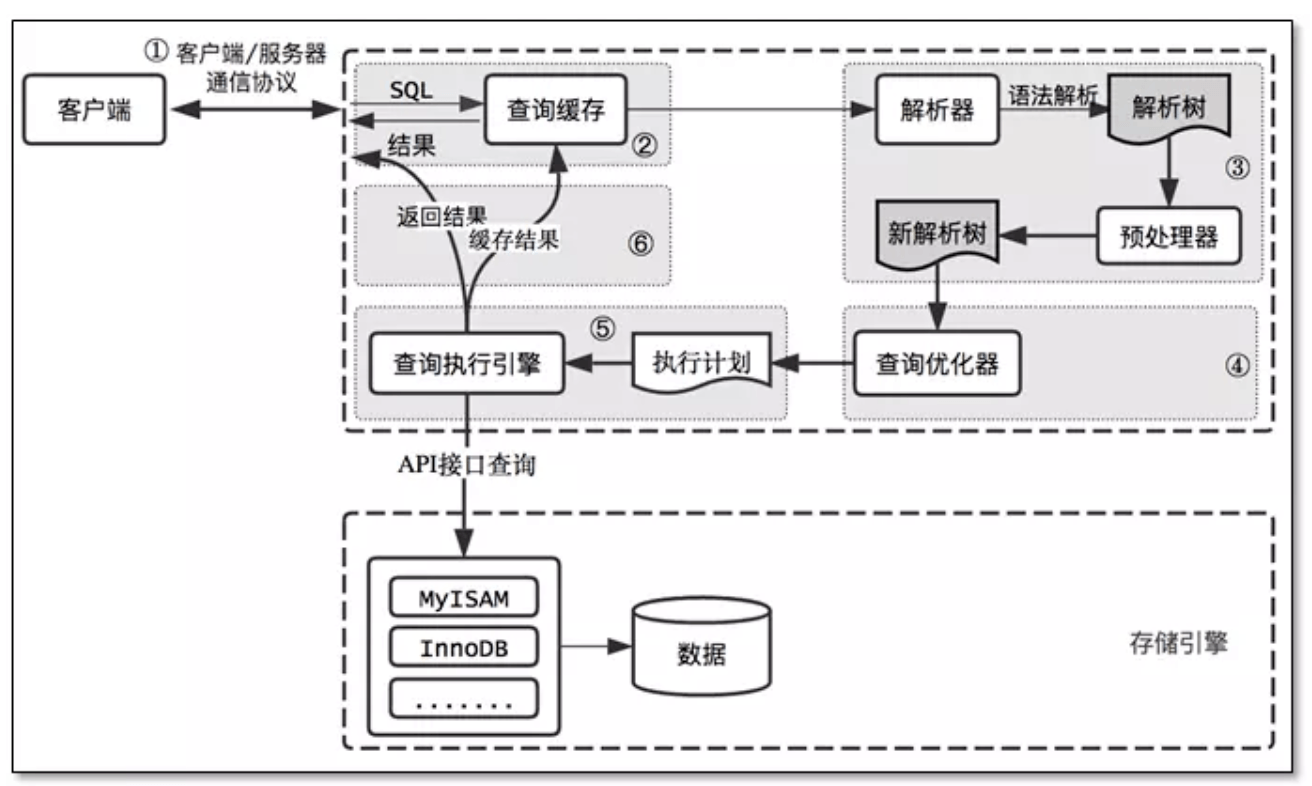
MySQL执行流程
1. 优化思路
1.1 优化什么
在数据库优化上有两个主要方面:即安全与性能。 安全 —> 数据可持续性 性能 —> 数据的高性能访问
1.2 优化的范围有哪些
存 储、主机和操作系统方面:
主机架构稳定性 I/O规划及配置 Swap交换分区 OS内核参数和网络问题
应用程序方面:
应用程序稳定性 SQL语句性能 串行访问资源 性能欠佳会话管理 这个应用适不适合用MySQL
数据库优化方面
内存 数据库结构(物理&逻辑) 实例配置
说明:不管是在,设计系统,定位问题还是优化,都可以按照这个顺序执行。
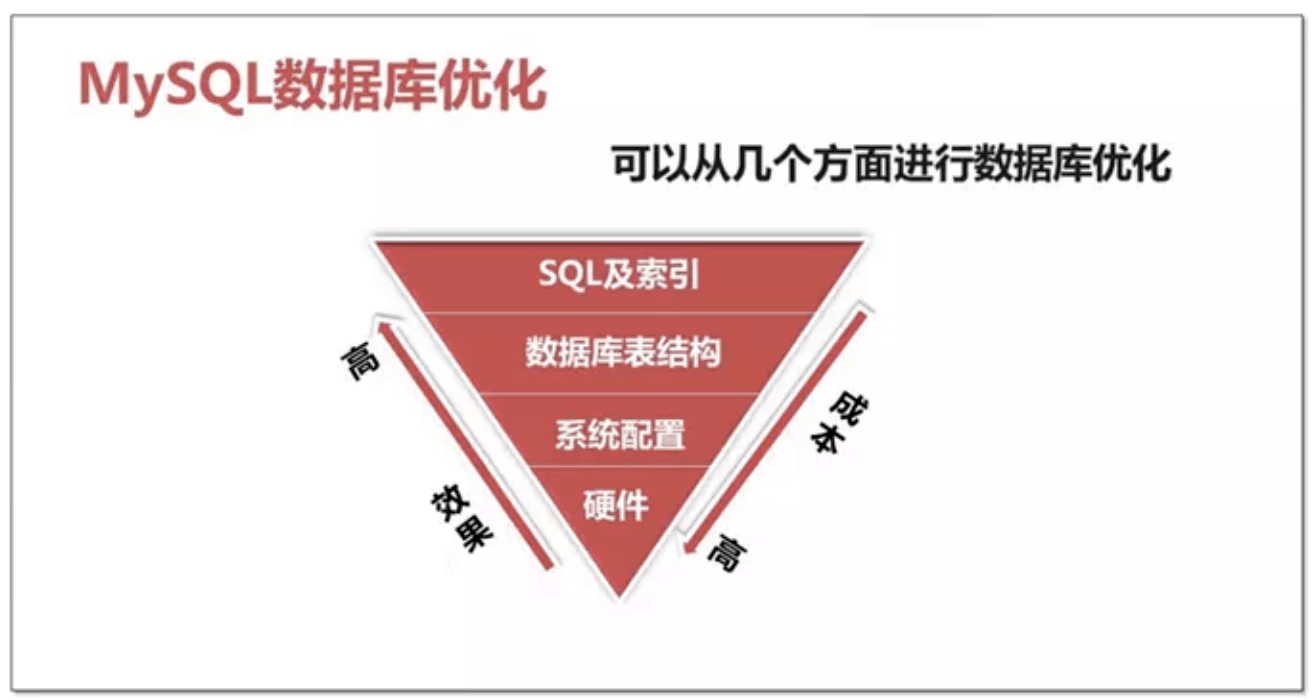
1.3 优化维度
数据库优化维度有四个:
硬件、系统配置、数据库表结构、SQL及索引
2 优化工具有啥?
2.1 数据库层面
检查问题常用工具
mysql
msyqladmin mysql客户端,可进行管理操作
mysqlshow 功能强大的查看shell命令
show [SESSION | GLOBAL] variables 查看数据库参数信息
SHOW [SESSION | GLOBAL] STATUS 查看数据库的状态信息
information_schema 获取元数据的方法
SHOW ENGINE INNODB STATUS Innodb引擎的所有状态
SHOW PROCESSLIST 查看当前所有连接session状态
explain 获取查询语句的执行计划
show index 查看表的索引信息
slow-log 记录慢查询语句
mysqldumpslow 分析slowlog文件的
复制代码不常用但好用的工具
zabbix 监控主机、系统、数据库(部署zabbix监控平台)
pt-query-digest 分析慢日志
mysqlslap 分析慢日志
sysbench 压力测试工具
mysql profiling 统计数据库整体状态工具
Performance Schema mysql性能状态统计的数据
workbench 管理、备份、监控、分析、优化工具(比较费资源)2.2 数据库层面问题解决思路
一般应急调优的思路:
针对突然的业务办理卡顿,无法进行正常的业务处理!需要立马解决的场景!
- show processlist
- explain select id ,name from stu where name=’clsn’; # ALL id name age sex
select id,name from stu where id=2-1 函数 结果集>30; show index from table;- 通过执行计划判断,索引问题(有没有、合不合理)或者语句本身问题
- show status like ‘%lock%’; # 查询锁状态
kill SESSION_ID; # 杀掉有问题的session
常规调优思路:
针对业务周期性的卡顿,例如在每天10-11点业务特别慢,但是还能够使用,过了这段时间就好了。
1、查看slowlog,分析slowlog,分析出查询慢的语句。 2、按照一定优先级,进行一个一个的排查所有慢语句。 3、分析top sql,进行explain调试,查看语句执行时间。 4、调整索引或语句本身。
2.3 系统层面
cpu方面
vmstat、sar top、htop、nmon、mpstat
内存
free 、ps -aux 、
IO设备(磁盘、网络)
iostat 、 ss 、 netstat 、 iptraf、iftop、lsof、
vmstat 命令说明:
Procs:r显示有多少进程正在等待CPU时间。b显示处于不可中断的休眠的进程数量。在等待I/O Memory:swpd显示被交换到磁盘的数据块的数量。未被使用的数据块,用户缓冲数据块,用于操作系统的数据块的数量 Swap:操作系统每秒从磁盘上交换到内存和从内存交换到磁盘的数据块的数量。s1和s0最好是0 Io:每秒从设备中读入b1的写入到设备b0的数据块的数量。反映了磁盘I/O System:显示了每秒发生中断的数量(in)和上下文交换(cs)的数量 Cpu:显示用于运行用户代码,系统代码,空闲,等待I/O的CPU时间
iostat命令说明
实例命令: iostat -dk 1 5 iostat -d -k -x 5 (查看设备使用率(%util)和响应时间(await)) tps:该设备每秒的传输次数。“一次传输”意思是“一次I/O请求”。多个逻辑请求可能会被合并为“一次I/O请求”。 iops :硬件出厂的时候,厂家定义的一个每秒最大的IO次数 “一次传输”请求的大小是未知的。 kB_read/s:每秒从设备(drive expressed)读取的数据量; KB_wrtn/s:每秒向设备(drive expressed)写入的数据量; kB_read:读取的总数据量; kB_wrtn:写入的总数量数据量;这些单位都为Kilobytes。
2.4 系统层面问题解决办法
在实际的生产中,一般认为 cpu只要不超过90%都没什么问题 。
当然不排除下面这些特殊情况:
问题一:cpu负载高,IO负载低
内存不够 磁盘性能差 SQL问题 ——>去数据库层,进一步排查sql问题 IO出问题了(磁盘到临界了、raid设计不好、raid降级、锁、在单位时间内tps过高) tps过高: 大量的小数据IO、大量的全表扫描
问题二:IO负载高,cpu负载低
大量小的IO 写操作:
autocommit ,产生大量小IO
IO/PS,磁盘的一个定值,硬件出厂的时候,厂家定义的一个每秒最大的IO次数。
大量大的IO 写操作
SQL问题的几率比较大
问题三:IO和cpu负载都很高
硬件不够了或sql存在问题
3 基础优化
3.1 优化思路
定位问题点吮吸 硬件 –> 系统 –> 应用 –> 数据库 –> 架构(高可用、读写分离、分库分表)
处理方向 明确优化目标、性能和安全的折中、防患未然
3.2 硬件优化
主机方面:
根据数据库类型,主机CPU选择、内存容量选择、磁盘选择 平衡内存和磁盘资源 随机的I/O和顺序的I/O 主机 RAID卡的BBU(Battery Backup Unit)关闭
cpu的选择:
cpu的两个关键因素:核数、主频 根据不同的业务类型进行选择: cpu密集型:计算比较多,OLTP 主频很高的cpu、核数还要多 IO密集型:查询比较,OLAP 核数要多,主频不一定高的
内存的选择:
OLAP类型数据库,需要更多内存,和数据获取量级有关。 OLTP类型数据一般内存是cpu核心数量的2倍到4倍,没有最佳实践。
存储方面:
根据存储数据种类的不同,选择不同的存储设备 配置合理的RAID级别(raid5、raid10、热备盘)
对与操作系统来讲,不需要太特殊的选择,最好做好冗余(raid1)(ssd、sas 、sata)
raid卡:主机raid卡选择:
实现操作系统磁盘的冗余(raid1)
平衡内存和磁盘资源
随机的I/O和顺序的I/O
主机 RAID卡的BBU(Battery Backup Unit)要关闭。
网络设备方面:
使用流量支持更高的网络设备(交换机、路由器、网线、网卡、HBA卡)
注意:以上这些规划应该在初始设计系统时就应该考虑好。
3.3 服务器硬件优化
- 物理状态灯:
- 自带管理设备:远程控制卡(FENCE设备:ipmi ilo idarc),开关机、硬件监控。
- 第三方的监控软件、设备(snmp、agent)对物理设施进行监控
- 存储设备:自带的监控平台。EMC2(hp收购了), 日立(hds),IBM低端OEM hds,高端存储是自己技术,华为存储
3.4 系统优化
Cpu:
基本不需要调整,在硬件选择方面下功夫即可。
内存:
基本不需要调整,在硬件选择方面下功夫即可。
SWAP:
MySQL尽量避免使用swap。 阿里云的服务器中默认swap为0
IO :
raid、no lvm、 ext4或xfs、ssd、IO调度策略
Swap调整(不使用swap分区)
/proc/sys/vm/swappiness的内容改成0(临时),/etc/sysctl.conf上添加vm.swappiness=0(永久)
这个参数决定了Linux是倾向于使用swap,还是倾向于释放文件系统cache。在内存紧张的情况下,数值越低越倾向于释放文件系统cache。
当然,这个参数只能减少使用swap的概率,并不能避免Linux使用swap。
修改MySQL的配置参数innodb_flush_method,开启O_DIRECT模式。
这种情况下,InnoDB的buffer pool会直接绕过文件系统cache来访问磁盘,但是redo log依旧会使用文件系统cache。
值得注意的是,Redo log是覆写模式的,即使使用了文件系统的cache,也不会占用太多
IO调度策略
#echo deadline>/sys/block/sda/queue/scheduler 临时修改为deadline 永久修改
vi /boot/grub/grub.conf 更改到如下内容: kernel /boot/vmlinuz-2.6.18-8.el5 ro root=LABEL=/ elevator=deadline rhgb quiet
3.5 系统参数调整
Linux系统内核参数优化
vim /etc/sysctl.conf net.ipv4.ip_local_port_range = 1024 65535 # 用户端口范围 net.ipv4.tcp_max_syn_backlog = 4096 net.ipv4.tcp_fin_timeout = 30 fs.file-max=65535 # 系统最大文件句柄,控制的是能打开文件最大数量
用户限制参数(mysql可以不设置以下配置)
vim /etc/security/limits.conf * soft nproc 65535 * hard nproc 65535 * soft nofile 65535 * hard nofile 65535
3.6 应用优化
业务应用和数据库应用独立,
防火墙:iptables、selinux等其他无用服务(关闭):
chkconfig --level 23456 acpid off
chkconfig --level 23456 anacron off
chkconfig --level 23456 autofs off
chkconfig --level 23456 avahi-daemon off
chkconfig --level 23456 bluetooth off
chkconfig --level 23456 cups off
chkconfig --level 23456 firstboot off
chkconfig --level 23456 haldaemon off
chkconfig --level 23456 hplip off
chkconfig --level 23456 ip6tables off
chkconfig --level 23456 iptables off
chkconfig --level 23456 isdn off
chkconfig --level 23456 pcscd off
chkconfig --level 23456 sendmail off
chkconfig --level 23456 yum-updatesd off
安装图形界面的服务器不要启动图形界面 runlevel 3
另外,思考将来我们的业务是否真的需要MySQL,还是使用其他种类的数据库。用数据库的最高境界就是不用数据库。
4 数据库优化
SQL优化方向: 执行计划、索引、SQL改写
架构优化方向: 高可用架构、高性能架构、分库分表
4.1 数据库参数优化
调整:
实例整体(高级优化,扩展):
thread_concurrency # 并发线程数量个数
sort_buffer_size # 排序缓存
read_buffer_size # 顺序读取缓存
read_rnd_buffer_size # 随机读取缓存
key_buffer_size # 索引缓存
thread_cache_size # (1G—>8, 2G—>16, 3G—>32, >3G—>64)
连接层(基础优化)
设置合理的连接客户和连接方式
max_connections # 最大连接数,看交易笔数设置
max_connect_errors # 最大错误连接数,能大则大
connect_timeout # 连接超时
max_user_connections # 最大用户连接数
skip-name-resolve # 跳过域名解析
wait_timeout # 等待超时
back_log # 可以在堆栈中的连接数量4.2 存储引擎层(innodb基础优化参数)
default-storage-engine
innodb_buffer_pool_size # 没有固定大小,50%测试值,看看情况再微调。但是尽量设置不要超过物理内存70%
innodb_file_per_table=(1,0)
innodb_flush_log_at_trx_commit=(0,1,2) # 1是最安全的,0是性能最高,2折中
binlog_sync
Innodb_flush_method=(O_DIRECT, fdatasync)
innodb_log_buffer_size # 100M以下
innodb_log_file_size # 100M 以下
innodb_log_files_in_group # 5个成员以下,一般2-3个够用(iblogfile0-N)
innodb_max_dirty_pages_pct # 达到百分之75的时候刷写 内存脏页到磁盘。
log_bin
max_binlog_cache_size # 可以不设置
max_binlog_size # 可以不设置
innodb_additional_mem_pool_size #小于2G内存的机器,推荐值是20M。32G内存以上100M4.3 SQL层(基础优化)
一、EXPLAIN
做MySQL优化,我们要善用 EXPLAIN 查看SQL执行计划。
下面来个简单的示例,标注(1,2,3,4,5)我们要重点关注的数据

- type列,连接类型。一个好的sql语句至少要达到range级别。杜绝出现all级别
- key列,使用到的索引名。如果没有选择索引,值是NULL。可以采取强制索引方式
- key_len列,索引长度
- rows列,扫描行数。该值是个预估值
- extra列,详细说明。注意常见的不太友好的值有:Using filesort, Using temporary
二、SQL语句中IN包含的值不应过多
MySQL对于IN做了相应的优化,即将IN中的常量全部存储在一个数组里面,而且这个数组是排好序的。但是如果数值较多,产生的消耗也是比较大的。再例如:select id from table_name where num in(1,2,3) 对于连续的数值,能用 between 就不要用 in 了;再或者使用连接来替换。
三、SELECT语句务必指明字段名称
SELECT *增加很多不必要的消耗(cpu、io、内存、网络带宽);增加了使用覆盖索引的可能性;当表结构发生改变时,前断也需要更新。所以要求直接在select后面接上字段名。
四、当只需要一条数据的时候,使用limit 1
这是为了使EXPLAIN中type列达到const类型
五、如果排序字段没有用到索引,就尽量少排序
六、如果限制条件中其他字段没有索引,尽量少用or
or两边的字段中,如果有一个不是索引字段,而其他条件也不是索引字段,会造成该查询不走索引的情况。很多时候使用 union all 或者是union(必要的时候)的方式来代替“or”会得到更好的效果
七、尽量用union all代替union
union和union all的差异主要是前者需要将结果集合并后再进行唯一性过滤操作,这就会涉及到排序,增加大量的CPU运算,加大资源消耗及延迟。当然,union all的前提条件是两个结果集没有重复数据。
八、不使用ORDER BY RAND()
1. select id from `table_name`
2. order by rand() limit 1000;上面的sql语句,可优化为
1. select id from `table_name` t1 join
2. (select rand() * (select max(id) from `table_name`) as nid) t2
3. on t1.id > t2.nid limit 1000;九、区分in和exists, not in和not exists
select * from 表A where id in (select id from 表B)上面sql语句相当于
1. select * from 表A where exists
2. (select * from 表B where 表B.id=表A.id)区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键),如果是exists,那么以外层表为驱动表,先被访问,如果是IN,那么先执行子查询。所以IN适合于外表大而内表小的情况;EXISTS适合于外表小而内表大的情况。
关于not in和not exists,推荐使用not exists,不仅仅是效率问题,not in可能存在逻辑问题。
原sql语句
1. select colname … from A表
2. where a.id not in (select b.id from B表)高效的sql语句
1. select colname … from A表 Left join B表 on
2. where a.id = b.id where b.id is null取出的结果集如下图表示,A表不在B表中的数据

十、使用合理的分页方式以提高分页的效率
select id,name from table_name limit 866613, 20
使用上述sql语句做分页的时候,可能有人会发现,随着表数据量的增加,直接使用limit分页查询会越来越慢。
优化的方法如下:可以取前一页的最大行数的id,然后根据这个最大的id来限制下一页的起点。比如此列中,上一页最大的id是866612。sql可以采用如下的写法:
select id,name from table_name where id> 866612 limit 20十一、分段查询
在一些用户选择页面中,可能一些用户选择的时间范围过大,造成查询缓慢。主要的原因是扫描行数过多。这个时候可以通过程序,分段进行查询,循环遍历,将结果合并处理进行展示。
如下图这个sql语句,扫描的行数成百万级以上的时候就可以使用分段查询

十二、避免在 where 子句中对字段进行 null 值判断
对于null的判断会导致引擎放弃使用索引而进行全表扫描。
十三、不建议使用%前缀模糊查询
例如LIKE “%name”或者LIKE “%name%”,这种查询会导致索引失效而进行全表扫描。但是可以使用LIKE “name%”。
那如何查询%name%?
如下图所示,虽然给secret字段添加了索引,但在explain结果果并没有使用
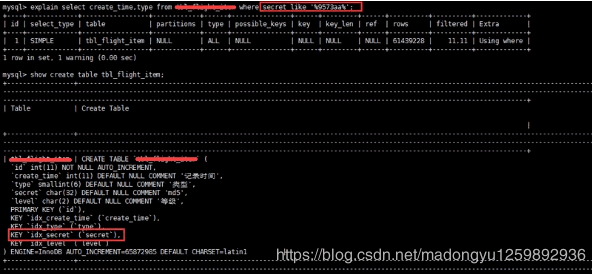
那么如何解决这个问题呢,答案:使用全文索引
在我们查询中经常会用到select id,fnum,fdst from table_name where user_name like '%zhangsan%';。这样的语句,普通索引是无法满足查询需求的。庆幸的是在MySQL中,有全文索引来帮助我们。
创建全文索引的sql语法是:
ALTER TABLE `table_name` ADD FULLTEXT INDEX `idx_user_name` (`user_name`);
使用全文索引的sql语句是:
select id,fnum,fdst from table_name
where match(user_name) against('zhangsan' in boolean mode);
注意:在需要创建全文索引之前,请联系DBA确定能否创建。同时需要注意的是查询语句的写法与普通索引的区别
十四、避免在where子句中对字段进行表达式操作
比如
select user_id,user_project from table_name where age*2=36;
中对字段就行了算术运算,这会造成引擎放弃使用索引,建议改成
select user_id,user_project from table_name where age=36/2;十五、避免隐式类型转换
where 子句中出现 column 字段的类型和传入的参数类型不一致的时候发生的类型转换,建议先确定where中的参数类型
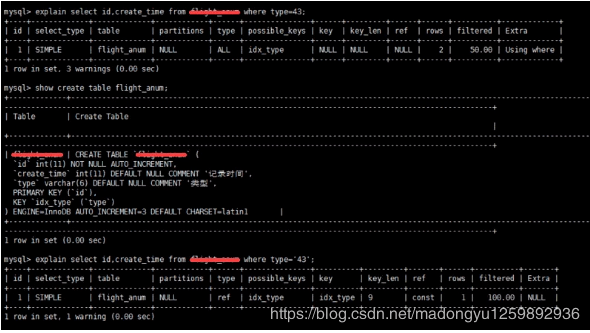
十六、对于联合索引来说,要遵守最左前缀法则
举列来说索引含有字段id,name,school,可以直接用id字段,也可以id,name这样的顺序,但是name,school都无法使用这个索引。所以在创建联合索引的时候一定要注意索引字段顺序,常用的查询字段放在最前面
十七、必要时可以使用force index来强制查询走某个索引
有的时候MySQL优化器采取它认为合适的索引来检索sql语句,但是可能它所采用的索引并不是我们想要的。这时就可以采用force index来强制优化器使用我们制定的索引。
十八、注意范围查询语句
对于联合索引来说,如果存在范围查询,比如between,>,<等条件时,会造成后面的索引字段失效。
十九、关于JOIN优化
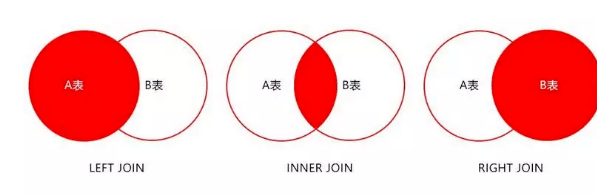
- LEFT JOIN A表为驱动表
- INNER JOIN MySQL会自动找出那个数据少的表作用驱动表
- RIGHT JOIN B表为驱动表
注意:MySQL中没有full join,可以用以下方式来解决
select * from A left join B on B.name = A.name where B.name is null union all select * from B;尽量使用inner join,避免left join
参与联合查询的表至少为2张表,一般都存在大小之分。如果连接方式是inner join,在没有其他过滤条件的情况下MySQL会自动选择小表作为驱动表,但是left join在驱动表的选择上遵循的是左边驱动右边的原则,即left join左边的表名为驱动表。
- 合理利用索引
- 被驱动表的索引字段作为on的限制字段。
- 利用小表去驱动大表
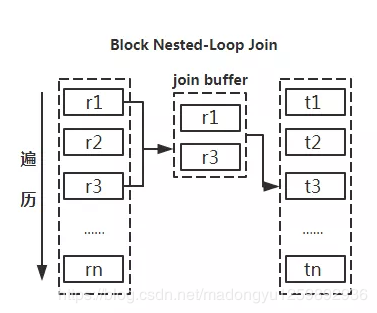
从原理图能够直观的看出如果能够减少驱动表的话,减少嵌套循环中的循环次数,以减少 IO总量及CPU运算的次数。
巧用STRAIGHT_JOIN
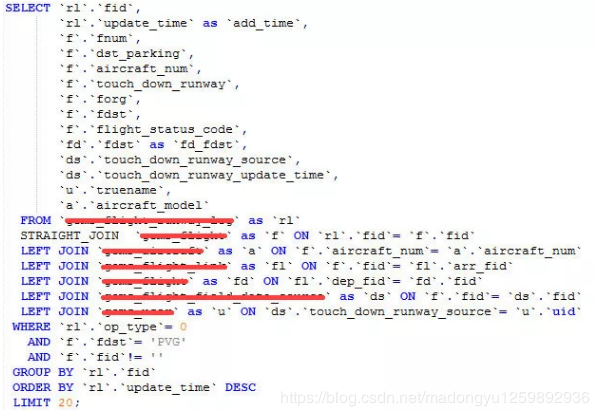
inner join是由mysql选择驱动表,但是有些特殊情况需要选择另个表作为驱动表,比如有group by、order by等「Using filesort」、「Using temporary」时。STRAIGHT_JOIN来强制连接顺序,在STRAIGHT_JOIN左边的表名就是驱动表,右边则是被驱动表。在使用STRAIGHT_JOIN有个前提条件是该查询是内连接,也就是inner join。其他链接不推荐使用STRAIGHT_JOIN,否则可能造成查询结果不准确。
MySQL的锁
乐观锁与悲观锁
- 乐观锁:每次读数据的时候都认为其他人不会修改,所以不会上锁,而是在更新的时候去判断在此期间有没有其他人更新了数据,可以使用版本号机制。在数据库中可以通过为数据表增加一个版本号字段实现。读取数据时将版本号一同读出,数据每次更新时对版本号加一。当我们更新的时候,判断数据库表对应记录的当前版本号与第一次取出来的版本号值进行比对,如果值相等,则予以更新,否则认为是过期数据。乐观锁适用于多读的应用类型,可以提高吞吐量。
- 悲观锁:每次读数据的时候都认为别人会修改,所以每次在读数据的时候都会上锁,这样别人想读这个数据时就会被阻塞。MySQL中就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在操作之前先上锁。
共享锁与排他锁
- 共享锁:共享锁又叫做读锁或S锁,加上共享锁后在事务结束之前其他事务只能再加共享锁、只能对其进行读操作不能写操作,除此之外其他任何类型的锁都不能再加了。
# 加上lock in share mode SELECT description FROM book_book lock in share mode; - 排他锁:排他锁又叫写锁或X锁,某个事务对数据加上排他锁后,只能这个事务对其进行读写,在此事务结束之前,其他事务不能对其加任何锁,可以读取,不能进行写操作,需等待其释放。
# 加上for update SELECT description FROM book_book for update;
行锁与表锁
行锁与表锁区别在于锁的粒度,在Innodb引擎中既支持行锁也支持表锁(MyISAM引擎只支持表锁),只有通过索引条件检索数据InnoDB才使用行级锁,否则,InnoDB将使用表锁。
- 表锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突概率高,并发度最低
- 行锁:开销大,加锁慢;会出现死锁;锁定粒度小,发生锁冲突的概率低,并发度高
这里有个比较疑惑的地方,为什么表锁不会出现死锁?在MyISAM中由于没有事务,一条SQL执行完锁就释放了,不会循环等待,所以只会出现阻塞而不会发生死锁。但是在**InnoDB中有事务就比较疑惑了,希望有了解的小伙伴指点指点@-@
举例
# 事务1
BEGIN;
SELECT description FROM book_book where name = 'JAVA编程思想' lock in share mode;
# 事务2
BEGIN;
UPDATE book_book SET name = 'new book' WHERE name = 'new';
# 查看事务状态
SELECT * FROM INFORMATION_SCHEMA.INNODB_TRX;
trx_id trx_state trx_started trx_tables_locked trx_rows_locked
39452 LOCK WAIT 2018-09-08 19:01:39 1 1
282907511143936 RUNNING 2018-09-08 18:58:47 1 38 事务1给book表加上了共享锁,事务2尝试修改book表发生了阻塞,查看事务状态可以知道事务一由于没有走索引使用了表锁。
# 事务1
BEGIN;
SELECT description FROM book_book WHERE id = 2 lock in share mode;
# 事务2
BEGIN;
UPDATE book_book SET name = 'new book' WHERE id = 1;
# 查看事务状态
SELECT * FROM INFORMATION_SCHEMA.INNODB_TRX;
trx_id trx_state trx_started trx_tables_locked trx_rows_locked
39454 RUNNING 2018-09-08 19:10:44 1 1
282907511143936 RUNNING 2018-09-08 19:10:35 1 1事务1给book表加上了共享锁,事务2尝试修改book表并没有发生阻塞。这是由于事务一和事务二都走了索引,所以使用的是行锁,并不会发生阻塞。
意向锁(InnoDB特有)
意向锁的意义在于方便检测表锁和行锁之间的冲突
意向锁:意向锁是一种表级锁,代表要对某行记录进行操作。分为意向共享锁(IS)和意向排他锁(IX)。
行锁和表锁之间的冲突:事务A给表中的某一行加了共享锁,让这一行只能读不能写。之后事务B申请整个表的排他锁。如果事务B申请成功,那么它就能修改表中的任意一行,这与A持有的行锁是冲突的。InnoDB引入了意向锁来判断它们之间的冲突。
没有意向锁的情况:1、判断表是否已被其他事务用表锁锁表。2、判断表中的每一行是否已被行锁锁住,这样要遍历整个表,效率很低。
意向锁存在的情况:1、判断表是否已被其他事务用表锁锁表。2、判断表上是否有意向锁
意向锁存在时申请锁:*申请意向锁的动作是数据库完成的*,上述例子中事务A申请一行的行锁的时候,数据库会自动先开始申请表的意向锁,当事务B申请表的排他锁时检测到存在意向锁则会阻塞。
意向锁会不会存在冲突: 意向锁之间不会冲突, 因为意向锁只是代表要对某行记录进行操作。
各种锁之间的共存情况
| IX | IS | X | S | |
|---|---|---|---|---|
| IX | 兼容 | 兼容 | 冲突 | 冲突 |
| IS | 兼容 | 兼容 | 冲突 | 兼容 |
| X | 冲突 | 冲突 | 冲突 | 冲突 |
| S | 冲突 | 兼容 | 冲突 | 兼容 |
死锁
- 概念:两个或两个以上的事务在执行过程中,因争夺资源而造成的一种互相等待的现象。
- 存在条件:1、 互斥条件:一个资源每次只能被一个事务使用。2、 请求与保持条件:一个事务因请求资源而阻塞时,对已获得的资源保持不放。3、不剥夺条件:已获得的资源,在末使用完之前不能强行剥夺。4、循环等待条件:形成一种头尾相接的循环等待关系
- 解除正在死锁的状态:撤销其中一个事务
MVCC(多版本并发控制)
MVCC使得InnoDB更好的实现事务隔离级别中的REPEATABLE READ
它使得InnoDB不再单纯的使用行锁来进行数据库的并发控制,取而代之的是把数据库的行锁与行的多个版本结合起来,只需要很小的开销,就可以实现非锁定读,从而大大提高数据库系统的并发性能。
实现:InnoDB实现MVCC的方法是它为每一行存储三个额外的隐藏字段
1.DB_TRX_ID:一个6byte的标识,每处理一个事务,其值自动+1 ,可以通过语句“show engine innodb status”来查找
2.DB_ROLL_PTR: 大小是7byte,指向写到rollback segment(回滚段)的一条undo log记录
3.DB_ROW_ID: 大小是6byte,该值随新行插入单调增加。
SELECT:返回的行数据需要满足的条件: 1、数据行的创建版本号必须小于等于事务的版本2、行的删除版本号(行中的特殊位被设置为将其标记为已删除)一定是未定义的或者大于当前事务的版本号,确定了当前事务开始之前行没有被删除。
INSERT:InnoDB为每个新增行记录当前系统版本号作为创建版本号。
DELETE:InnoDB为每个删除行的记录当前系统版本号作为行的删除版本号。
UPDATE:InnoDB复制了一条数据。这条数据的版本号使用了系统版本号。它也把系统版本号作为老数据的删除号。
说明:这里的读是不加锁的select等,MVCC实现可重复读使用的是读取undo中的已经提交的数据,是非阻塞的。insert操作时”创建时间”=DB_ROW_ID,这时”删除时间”是未定义的;update时,复制新增行的”创建时间”=DB_ROW_ID,删除时间未定义,旧数据行”创建时间”不变,删除时间=该事务的DB_ROW_ID; delete操作,相应数据行的”创建时间”不变,删除时间=该事务的DB_ROW_ID;
间隙锁(Next-Key锁)
间隙锁使得InnoDB解决幻读问题,加上MVCC使得InnoDB的RR隔离级别实现了串行化级别的效果,并且保留了比较好的并发性能。
定义:当我们用范围条件检索数据时请求共享或排他锁时,InnoDB会给符合条件的已有数据的索引加锁;对于键值在条件范围内但并不存在的记录,叫做间隙(GAP),InnoDB也会对这个”间隙”加锁,这种锁机制就是间隙锁。
例如:book表中存在bookId 1-80,90-99的记录。SELECT * FROM book WHERE bookId < 100 FOR UPDATE。InnoDB不仅会对bookId值为1-80,90-99的记录加锁,也会对bookId在81-89之间(这些记录并不存在)的间隙加锁。这样就能避免事务隔离级别可重复读下的幻读。
Postgresql
Key-value
badger
Level DB
Redis
数据结构
- String
- List
- Set
- Hash
- SortedSet
- Hyperloglog
- Geo
- PubSub
模块
- RedisSearch
- BloomFilter
- Redis-ML
Redis分布式锁
分布式锁的实现方式
- 数据库的乐观锁
- 给予zookeeper的分布式锁
- 给予redis的分布式锁
分布式锁的注意事项
互斥性:在任意时刻,只有一个客户端能持有锁
同一性:加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了。
避免死锁:即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。
Redis实现方式
- setnx+del+expire用法
- Redis 2.6.12以上版本为set指令增加了可选参数,伪代码如下:set(key,1,30,NX),这样就可以取代setnx指令。
- 单条指令合并setnx 和 expire, lua脚本了解一下
Redis实现事务
- Redis的事务是通过MULTI,EXEC,DISCARD和WATCH这四个命令来完成。
- Redis的单个命令都是原子性的,所以这里确保事务性的对象是命令集合。
- Redis将命令集合序列化并确保处于一事务的命令集合连续且不被打断的执行。
- Redis不支持回滚的操作。
- MULTI
注:用于标记事务块的开始。
Redis会将后续的命令逐个放入队列中,然后使用EXEC命令原子化地执行这个命令序列。
语法:MULTI - EXEC
在一个事务中执行所有先前放入队列的命令,然后恢复正常的连接状态。
语法:EXEC - DISCARD
清楚所有先前在一个事务中放入队列的命令,然后恢复正常的连接状态。
语法:DISCARD - WATCH
当某个事务需要按条件执行时,就要使用这个命令将给定的键设置为受监控的状态。
语法:WATCH key [key ….]
注:该命令可以实现redis的乐观锁 - UNWATCH
清除所有先前为一个事务监控的键。
语法:UNWATCH
为什么redis不支持事务回滚?
- 大多数事务失败是因为语法错误或者类型错误,这两种错误,再开发阶段都是可以避免的
- Redis为了性能方面就忽略了事务回滚
扫描Key
- keys (有问题,慎用,最好不用)
- scan
Redis做异步队列
- 使用lis- t结构作为队列
- rpush生产消息,lpop消费消息, lpop没有消息的时候,要适当sleep一会再重试
- blpop,在没有消息的时候,它会阻塞住直到消息到来
- 生产一次消费多次: 使用pub/sub主题订阅者模式,可以实现1:N的消息队列
- pub/sub有什么缺点?在消费者下线的情况下,生产的消息会丢失,得使用专业的消息队列如rabbitmq等
- redis如何实现延时队列 – 使用sortedset,拿时间戳作为score,消息内容作为key调用zadd来生产消息,消费者用zrangebyscore指令获取N秒之前的数据轮询进行处理
大量的key需要设置同一时间过期,一般需要注意什么
过期的那个时间点,redis可能会出现短暂的卡顿现象。严重的话会出现缓存雪崩,我们一般需要在时间上加一个随机值,使得过期时间分散一些
Redis如何做持久化的
- bgsave做镜像全量持久化(RDB),aof做增量持久化
- 为bgsave会耗费较长时间,不够实时,在停机的时候会导致大量丢失数据,所以需要aof来配合使用。
- 在redis实例重启时,会使用bgsave持久化文件重新构建内存,再使用aof重放近期的操作指令来实现完整恢复重启之前的状态
- 如果突然机器掉电会怎样?取决于aof日志sync属性的配置,如果不要求性能,在每条写指令时都sync一下磁盘,就不会丢失数据。但是在高性能的要求下每次都sync是不现实的,一般都使用定时sync,比如1s1次,这个时候最多就会丢失1s的数据。
- bgsave的原理是什么 – fork和cow。fork是指redis通过创建子进程来进行bgsave操作,cow指的是copy on write,子进程创建后,父子进程共享数据段,父进程继续提供读写服务,写脏的页面数据会逐渐和子进程分离开来。
RDB 优缺点
- RDB会生成多个数据文件,每个数据文件都代表了某一个时刻中 redis 的数据,这种多个数据文件的方式,非常适合做冷备,可以将这种完整的数据文件发送到一些远程的安全存储上去,比如说 Amazon 的 S3 云服务上去,在国内可以是阿里云的 ODPS 分布式存储上,以预定好的备份策略来定期备份redis中的数据。
RDB 对 redis 对外提供的读写服务,影响非常小,可以让 redis 保持高性能,因为 redis 主进程只需要 fork 一个子进程,让子进程执行磁盘 IO 操作来进行 RDB 持久化即可。
- 相对于 AOF 持久化机制来说,直接基于 RDB 数据文件来重启和恢复 redis 进程,更加快速。
- 如果想要在 redis 故障时,尽可能少的丢失数据,那么 RDB 没有 AOF 好。一般来说,RDB 数据快照文件,都是每隔 5 分钟,或者更长时间生成一次,这个时候就得接受一旦 redis 进程宕机,那么会丢失最近 5 分钟的数据。
RDB 每次在 fork 子进程来执行 RDB 快照数据文件生成的时候,如果数据文件特别大,可能会导致对客户端提供的服务暂停数毫秒,或者甚至数秒。
RDB触发条件
- 符合自定义配置的快照规则
- 执行save或者bgsave命令
- 执行flushall命令
- 执行主从复制操作
在redis.conf中设置自定义快照规则
1、RDB持久化条件
格式:save <seconds> <changes>示例:
- save 900 1:表示15分钟(900秒)内至少1个键更改则进行快照。
- save 300 10:表示5分钟(300秒)内至少10个键被更改则进行快照。
- save 60 10000:表示1分钟内至少10000个键被更改则进行快照。
2、配置dir指定rdb快照文件的位置
# Note that you must specify a directory here, not a file name.
dir ./3、配置dbfilename指定rdb快照文件的名称
# The filename where to dump the DB
dbfilename dump.rdb说明
- Redis启动后会读取RDB快照文件,将数据从硬盘载入到内存
- 根据数据量大小与结构和服务器性能不同,这个时间也不同。通常将记录1千万个字符串类型键,大小为1GB的快照文件载入到内存中需要花费20-30秒钟。
快照的实现原理
- redis使用fork函数复制一份当前进程的副本(子进程)
- 父进程继续接受并处理客户端发来的命令,而子进程开始将内存中的数据写入到硬盘**中的临时文件**。
- 当子进程写入完所有数据后会用该临时文件替换旧的RDB文件,至此,一次快照操作完成。
注意
- redis在进行快照的过程中不会修改RDB文件,只有快照结束后才会将旧的文件替换成新的,也就是说任何时候RDB文件都是完整的。
- 这就使得我们可以通过定时备份RDB文件来实现redis数据库的备份,RDB文件是经过压缩的二进制文件,占用的空间会小于内存中的数据,更加利于传输。
AOF 优缺点
- AOF 可以更好的保护数据不丢失,一般 AOF 会每隔 1 秒,通过一个后台线程执行一次
fsync操作,最多丢失 1 秒钟的数据。 - AOF 日志文件以
append-only模式写入,所以没有任何磁盘寻址的开销,写入性能非常高,而且文件不容易破损,即使文件尾部破损,也很容易修复。 - AOF 日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写。因为在
rewritelog 的时候,会对其中的指导进行压缩,创建出一份需要恢复数据的最小日志出来。再创建新日志文件的时候,老的日志文件还是照常写入。当新的 merge 后的日志文件 ready 的时候,再交换新老日志文件即可。 - AOF 日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如某人不小心用
flushall命令清空了所有数据,只要这个时候后台rewrite还没有发生,那么就可以立即拷贝 AOF 文件,将最后一条flushall命令给删了,然后再将该AOF文件放回去,就可以通过恢复机制,自动恢复所有数据。 - 对于同一份数据来说,AOF 日志文件通常比 RDB 数据快照文件更大。
- AOF 开启后,支持的写 QPS 会比 RDB 支持的写 QPS 低,因为 AOF 一般会配置成每秒
fsync一次日志文件,当然,每秒一次fsync,性能也还是很高的。(如果实时写入,那么 QPS 会大降,redis 性能会大大降低) - 以前 AOF 发生过 bug,就是通过 AOF 记录的日志,进行数据恢复的时候,没有恢复一模一样的数据出来。所以说,类似 AOF 这种较为复杂的基于命令日志/merge/回放的方式,比基于 RDB 每次持久化一份完整的数据快照文件的方式,更加脆弱一些,容易有 bug。不过 AOF 就是为了避免 rewrite 过程导致的 bug,因此每次 rewrite 并不是基于旧的指令日志进行 merge 的,而是基于当时内存中的数据进行指令的重新构建,这样健壮性会好很多。
AOF重写原理(优化AOF文件)
- Redis可以在AOF文件体积变得过大时,自动地后台对AOF进行重写
- 重写后的新AOF文件包含了恢复当前数据集所需的最小命令集合。
- 整个重写操作是绝对安全的,因为Redis在创建新的AOF文件的过程中,会继续将命令追加到现有的AOF文件里面,即使重写过程中发生停机,现有的AOF文件也不会丢失。而一旦新AOF文件创建完毕,Redis就会从旧AOF文件切换到新AOF文件,并开始对新AOF文件进行追加操作。
- AOF文件有序地保存了对数据库执行的所有写入操作,这些写入操作以Redis协议的格式保存,因此AOF文件的内容非常容易被人读懂,对文件进行分析(parse)也很轻松。
同步磁盘数据
Redis每次更改数据的时候,aof机制都会将命令记录到aof文件,但是实际上由于操作系统的缓存机制,数据并没有实时写入到硬盘,而是进入硬盘缓存。再通过硬盘缓存机制去刷新到保存文件中。
参数说明#
- appendfsync always:每次执行写入都会进行同步,这个是最安全但是效率比较低
- appendfsync everysec:每一秒执行
- appendfsync no:不主动进行同步操作,由于操作系统去执行,这个是最快但是最不安全的方式
AOF文件损坏以后如何修复
服务器可能在程序正在对AOF文件进行写入时停机,如果停机造成AOF文件出错(corrupt),那么Redis在重启时会拒绝载入这个AOF文件,从而确保数据的一致性不会被破坏。
当发生这种情况时,可以以以下方式来修复出错的AOF文件:
- 为现有的AOF文件创建一个备份。
- 使用Redis附带的redis-check-aof程序,对原来的AOF文件进行修复。
- 重启Redis服务器,等待服务器字啊如修复后的AOF文件,并进行数据恢复。
如何选择RDB和AOF
- 一般来说,如果对数据的安全性要求非常高的话,应该同时使用两种持久化功能。
- 如果可以承受数分钟以内的数据丢失,那么可以只使用RDB持久化。
- 有很多用户都只使用AOF持久化,但并不推荐这种方式:因为定时生成RDB快照(snapshot)非常便于进行数据库备份,并且RDB恢复数据集的速度也要比AOF恢复的速度要快。
- 两种持久化策略可以同时使用,也可以使用其中一种。如果同时使用的话,那么Redis启动时,会优先使用AOF文件来还原数据。
Redis的同步机制
Redis可以使用主从同步,从从同步。第一次同步时,主节点做一次bgsave,并同时将后续修改操作记录到内存buffer,待完成后将rdb文件全量同步到复制节点,复制节点接受完成后将rdb镜像加载到内存。加载完成后,再通知主节点将期间修改的操作记录同步到复制节点进行重放就完成了同步过程
- redis 采用异步方式复制数据到 slave 节点,不过 redis2.8 开始,slave node 会周期性地确认自己每次复制的数据量;
- 一个 master node 是可以配置多个 slave node 的;
- slave node 也可以连接其他的 slave node;
- slave node 做复制的时候,不会 block master node 的正常工作;
- slave node 在做复制的时候,也不会 block 对自己的查询操作,它会用旧的数据集来提供服务;但是复制完成的时候,需要删除旧数据集,加载新数据集,这个时候就会暂停对外服务了;
- slave node 主要用来进行横向扩容,做读写分离,扩容的 slave node 可以提高读的吞吐量。
注意,如果采用了主从架构,那么建议必须开启 master node 的持久化,不建议用 slave node 作为 master node 的数据热备,因为那样的话,如果你关掉 master 的持久化,可能在 master 宕机重启的时候数据是空的,然后可能一经过复制, slave node 的数据也丢了。
AOF文件损坏以后如何修复
服务器可能在程序正在对AOF文件进行写入时停机,如果停机造成AOF文件出错(corrupt),那么Redis在重启时会拒绝载入这个AOF文件,从而确保数据的一致性不会被破坏。
当发生这种情况时,可以以以下方式来修复出错的AOF文件:
- 为现有的AOF文件创建一个备份。
- 使用Redis附带的redis-check-aof程序,对原来的AOF文件进行修复。
- 重启Redis服务器,等待服务器字啊如修复后的AOF文件,并进行数据恢复
redis 主从复制的核心原理
- 当启动一个 slave node 的时候,它会发送一个
PSYNC命令给 master node。 - 如果这是 slave node 初次连接到 master node,那么会触发一次
full resynchronization全量复制。此时 master 会启动一个后台线程,开始生成一份RDB快照文件,同时还会将从客户端 client 新收到的所有写命令缓存在内存中。RDB文件生成完毕后, master 会将这个RDB发送给 slave,slave 会先写入本地磁盘,然后再从本地磁盘加载到内存中,接着 master 会将内存中缓存的写命令发送到 slave,slave 也会同步这些数据。 - slave node 如果跟 master node 有网络故障,断开了连接,会自动重连,连接之后 master node 仅会复制给 slave 部分缺少的数据。
过期 key 处理
slave 不会过期 key,只会等待 master 过期 key。如果 master 过期了一个 key,或者通过 LRU 淘汰了一个 key,那么会模拟一条 del 命令发送给 slave。
主从复制的断点续传
从 redis2.8 开始,就支持主从复制的断点续传,如果主从复制过程中,网络连接断掉了,那么可以接着上次复制的地方,继续复制下去,而不是从头开始复制一份。
master node 会在内存中维护一个 backlog,master 和 slave 都会保存一个 replica offset 还有一个 master run id,offset 就是保存在 backlog 中的。如果 master 和 slave 网络连接断掉了,slave 会让 master 从上次 replica offset 开始继续复制,如果没有找到对应的 offset,那么就会执行一次 resynchronization。
全量复制
master 执行 bgsave ,在本地生成一份 rdb 快照文件。
master node 将 rdb 快照文件发送给 slave node,如果 rdb 复制时间超过 60秒(repl-timeout),那么 slave node 就会认为复制失败,可以适当调大这个参数(对于千兆网卡的机器,一般每秒传输 100MB,6G 文件,很可能超过 60s)
master node 在生成 rdb 时,会将所有新的写命令缓存在内存中,在 slave node 保存了 rdb 之后,再将新的写命令复制给 slave node。
如果在复制期间,内存缓冲区持续消耗超过 64MB,或者一次性超过 256MB,那么停止复制,复制失败。
client-output-buffer-limit slave 256MB 64MB 60
slave node 接收到 rdb 之后,清空自己的旧数据,然后重新加载 rdb 到自己的内存中,同时基于旧的数据版本对外提供服务。
如果 slave node 开启了 AOF,那么会立即执行 BGREWRITEAOF,重写 AOF。
增量复制
如果全量复制过程中,master-slave 网络连接断掉,那么 slave 重新连接 master 时,会触发增量复制。
master 直接从自己的 backlog 中获取部分丢失的数据,发送给 slave node,默认 backlog 就是1MB。
msater就是根据 slave 发送的 psync 中的 offset 来从 backlog 中获取数据的。
heartbeat
主从节点互相都会发送 heartbeat 信息。
master 默认每隔 10秒 发送一次 heartbeat,slave node 每隔 1秒 发送一个 heartbeat。
异步复制
master 每次接收到写命令之后,先在内部写入数据,然后异步发送给 slave node。
Redis集群,集群的原理是什么
Redis Sentinal着眼于高可用,在master宕机时会自动将slave提升为master,继续提供服务。
Redis Sentinel哨兵机制
Sentinel(哨兵)进程是用于监控redis集群中Master主服务器工作的状态,在Master主服务器发生故障的时候,可以实现Master和Slave服务器的切换,保证系统的高可用,其已经被集成在redis2.6+的版本中,Redis的哨兵模式到2.8版本之后就稳定了下来。
哨兵进程的作用
- 监控(Monitoring):哨兵(Sentinel)会不断地检查你的Master和Slave是否运作正常。
- 提醒(Notification):当被监控的某个Redis节点出现问题时,哨兵(Sentinel)可以通过API向管理员或者其他应用程序发送通知。
- 自动故障迁移(Automatic failover):当一个Master不能正常工作时,哨兵(Sentinel)会开始一次自动故障迁移操作。
- 它会将失效Master的其中一个Slave升级为新的Master,并让失效Master的其他Slave改为复制新的Master;
- 当客户端视图连接失效的Master时,集群也会向客户端返回新Master的地址,使得集群可以使用现在的Master替换失效的Master。
- Master和Slave服务器切换后,Master的redis.conf、Slave的redis.conf和sentinel.conf的配置文件的内容都会发生相应的改变,即Master主服务器的redis.conf配置文件中会多一行Slave的配置,sentinel.conf的监控目标会随之调换。
哨兵进程的工作方式#
- 每个Sentinel(哨兵)进程以每秒钟一次的频率向整个集群中的Master主服务器,Slave从服务器以及其他Sentinel(哨兵)进程发送一个PING命令。
- 如果一个实例(instance)距离最后一次有效回复PING命令的时间超过down-after-milliseconds选项所指定的值,则这个实例会被Sentinel(哨兵)进程标记为主观下线(SDOWN)。
- 如果一个Master主服务器被标记为主观下线(SDOWN),则正在监视这个Master主服务器的所有Sentinel(哨兵)进程要以每秒一次的频率确认Master主服务器确实进入了主观下线状态。
- 当有足够数量的Sentinel(哨兵)进程(大于等于配置文件指定的值)在指定的时间范围内确认Master主服务器进入了主观下线状态(SDOWN),则Master主服务器会被标记为客观下线(ODOWN)。
- 在一般情况下,每个Sentinel(哨兵)进程会以每10秒一次的频率向集群中的所有Master主服务器、Slave从服务器发送INFO命令。
- 当Master主服务器被Sentinel(哨兵)进程标记为客观下线(ODOWN)时,Sentinel(哨兵)进程向下线的Master主服务器的所有Slave从服务器发送INFO命令的频率会从10秒一次改为每秒一次。
- 若没有足够数量的Sentinel(哨兵)进程同意Master主服务器下线,Master主服务器的客观下线状态就会被移除。若Master主服务器重新向Sentinel(哨兵)进程发送PING命令返回有效回复,Master主服务器的主观下线状态就会被移除。
Redis Cluster
- Redis集群最少需要三台主服务器,三台从服务器
- 先启动服务器实例,然后运行创建集群命令行
./redis-trib.rb create --replicas 1 192.168.242.129:7001 192.168.242.129:7002 192.168.242.129:7003 192.168.242.129:7004 192.168.242.129:7005 192.168.242.129:7006
架构细节#
所有的redis节点彼此互联(PING-PING机制),内部使用二进制协议优化传输速度和带宽。
节点的fail是通过集群中超过半数的节点检测失效时才生效。
客户端与redis节点直连,不需要中间proxy层,客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster负责维护node<->slot<->value
Redis集群中内置了16384个哈希槽,当需要在Redis集群中放置一个key-value时,redis先对key使用crc16算法算出一个结果,然后把结果对16384求余数,
这样每个key都会对应一个编号在0-16384之间的哈希槽,redis会根据节点数量大致均等的将哈希槽映射到不同节点。
Redis Cluster着眼于扩展性,在单个redis内存不足时,使用Cluster进行分片存储。
redis 如何才能做到高可用
如果系统在 365 天内,有 99.99% 的时间,都是可以哗哗对外提供服务的,那么就说系统是高可用的。一个 slave 挂掉了,是不会影响可用性的,还有其它的 slave 在提供相同数据下的相同的对外的查询服务。但是,如果 master node 死掉了,会怎么样?没法写数据了,写缓存的时候,全部失效了。slave node 还有什么用呢,没有 master 给它们复制数据了,系统相当于不可用了。redis 的高可用架构,叫做 failover 故障转移,也可以叫做主备切换。master node 在故障时,自动检测,并且将某个 slave node 自动切换位 master node的过程,叫做主备切换。这个过程,实现了 redis 的主从架构下的高可用。
Pipeline有什么好处,为什么要用pipeline?
可以将多次IO往返的时间缩减为一次,前提是pipeline执行的指令之间没有因果相关性。使用redis-benchmark进行压测的时候可以发现影响redis的QPS峰值的一个重要因素是pipeline批次指令的数目。
批处理
lua脚本语言了解一下
Redis 的过期策略都有哪些?内存淘汰机制都有哪些?
redis 过期策略是:定期删除+惰性删除+内存淘汰机制 ****。
定期删除,指的是 redis 默认是每隔 100ms 就随机抽取一些设置了过期时间的 key,检查其是否过期,如果过期就删除。
惰性删除。这就是说,在你获取某个 key 的时候,redis 会检查一下 ,这个 key 如果设置了过期时间那么是否过期了?如果过期了此时就会删除,不会给你返回任何东西。
内存淘汰机制
Redis 内存淘汰机制有以下几个:
- noeviction: 当内存不足以容纳新写入数据时,新写入操作会报错,这个一般没人用吧,实在是太恶心了。
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 key(这个是最常用的)。
- allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个 key,这个一般没人用吧,为啥要随机,肯定是把最近最少使用的 key 给干掉啊。
- volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的 key(这个一般不太合适)。
- volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个 key。
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的 key 优先移除。
redis-cluster投票:容错
- 集群中所有master参与投票,如果半数以上master节点与其中一个master节点通信超过(cluster-node-timeout),认为该master节点挂掉。
- 什么时候整个集群不可用(cluster_state:fail)?
- 如果集群任意master挂掉,且当前master没有slave,则集群进入fail状态。也可以理解成集群的[0-16384]slot映射不完全时进入fail状态。
- 如果集群超过半数以上master挂掉,无论是否有slave,集群进入fail状态。
RocksDB
NewSQL
Dynamo–建设中
Greenplum–建设中
TDEngin–建设中
TiDB–建设中
Elastic Search
列式存储数据库
Cassandra
HBase
- 表:HBase采用表来组织数据,表由行和列组成,列划分为若干列族。
- 行:每个HBase表都由若干行组成,每个行由行键(row key)来标识。
- 列族:一个HBase表被分组成许多“列族”(Column Family)的集合,它是基本的访问控制单元。
- 列限定符:列族里的数据通过限定符(或列)来定位。
- 单元格:在HBase表中,通过行、列族和列限定符确定一个“单元格”(cell),单元格中存储的数据没有数据类型,总被视为字节数组byte[]
- 时间戳:每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引。
Hbase的实现原理
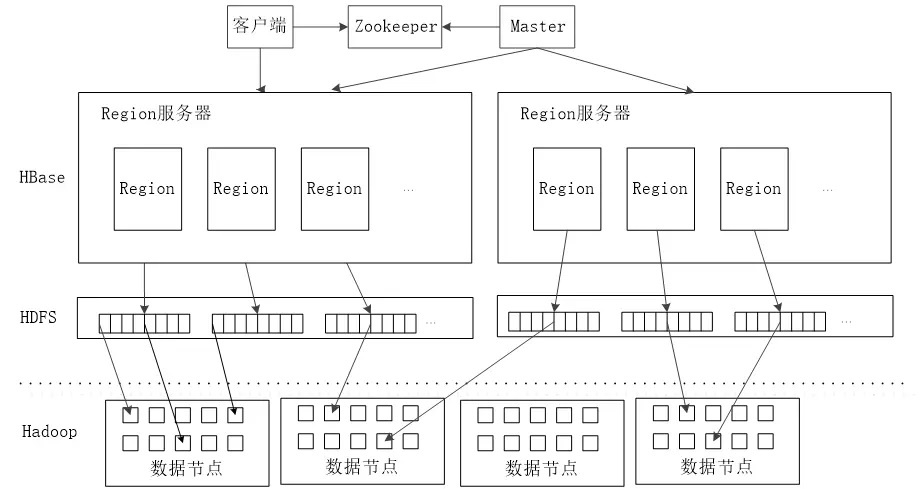
HBase的实现包括三个主要的功能组件:
- 1、库函数:链接到每个客户端
- 2、一个Master主服务器
- 3、许多个Region服务器
主服务器Master负责管理和维护Hbase表的分区信息,维护Region服务器列表,分配Region,负载均衡。
Region服务器负责存储和维护分配给自己的Region,处理来自客户端的读写请求。
客户端并不是直接从Master主服务器上读取数据,而是在获得Region的存储位置信息后,直接从Region服务器上读取数据。
客户端并不依赖Master,而是通过Zookeeper来Region位置信息,大多数客户端甚至从来不和Master通信,这种设计方式使得Master负载很小。
客户端
客户端包含访问Hbase的接口,同时在缓存中维护着已经访问过的Region位置信息,用来加快后续数据访问过程。
Zookeeper服务器
Zookeeper可以帮助选举出一个Master作为集群的总管,并保证在任何时刻总有唯一一个Master在运行,这就避免了Master的“单点失效”的问题。
Master服务器
主服务器Master主要负责表和Region的管理工作:
- 管理用户对表的增加、删除、修改、查询等操作
- 实现不同Region服务器之间的负载均衡
- 在Region分裂或合并后,负责重新调整Region的分布
- 对发生故障失效的Region服务器上Region进行迁移
Region服务器
Region服务器是Hbase中最核心的模块,负责维护分配给自己的Region,并响应用户的读写请求
Region服务器向HDFS文件系统中读写数据过程:
- 1、用户读写数据过程
- 用户写入数据时,被分配到相应Region服务器去执行
- 用户数据首先被写入到MEMStore和Hlog中
- 只有当操作写入Hlog之后,commit()调用才会将其返回给客户端
- 当用户读取数据时,Region服务器首先访问MEMStore缓存,如果找不到,再去磁盘上面的StoreFile中寻找
- 2、缓存的刷新
- 系统会周期性地把MemStore缓存里的内容刷写到磁盘的StoreFile文件中,清空缓存,并在Hlog里面写入一个标记
- 每次刷写都生成一个新的StoreFile文件,因此,每个Store包含多个StoreFile文件
- 每个Region服务器都有一个自己的HLog 文件,每次启动都检查该文件,确认最近一次执行缓存刷新操作之后是否发生新的写入操作;如果发现更新,则先写入MemStore,再刷写到StoreFile,最后删除旧的Hlog文件,开始为用户提供服务。
- 3、StoreFile的合并
- 每次刷写都生成一个新的StoreFile,数量太多,影响查找速度、
- 调用Store.compact()把多个合并成一个
- 合并操作比较耗费资源,只有数量达到一个阈值才启动合并
在Hbase之上构建SQL引擎
NoSQL区别于关系型数据库的一点就是NoSQL不使用SQL作为查询语言,至于为何在NoSQL数据存储HBase上提供SQL接口,有如下原因:
- 1、易使用。使用诸如SQL这样易于理解的语言,使人们能够更加轻松地使用Hasee。
- 2、减少编码。使用诸如SQL这样更高层次的语言来编写,减少了编写的代码量。
解决方案:Hive整合HBase
- Hive与HBase的整合功能从Hive0.6.0版本已经开始出现,利用两者对外的API接口互相通信,通信主要依靠hive_hbase-handler.jar工具包(Hive
- Storage Handlers)。由于HBase有一次比较大的版本变动,所以并不是每个版本的Hive都能和现有的HBase版本进行整合,所以在使用过程中特别注意的就是两者版本的一致性。
构建Hbase二级索引
HBase只有一个针对行键的索引,访问Hbase表中的行,只有三种方式:
- 通过单个行键访问
- 通过一个行键的区间来访问
- 全表扫描
使用其他产品为Hbase行键提供索引功能:
- Hindex二级索引
- Hbase+Redis
- Hbase+solr
时序数据库
图数据库
dgraph–建设中
JanusGraph–建设中
Neo4j–建设中
TigerGraph–建设中
Titan–建设中
Big Data
Big Data
Flink–建设中
Google GFS & BigTable & MapReduce & Spanner & Dataflow
大数据1.0时代的开端—GFS & BigTable & MapReduce 三驾马车
虽然Google没有公布这三个产品的源码,但是他发布了这三个产品的详细设计论文。而且,Yahoo资助的Hadoop也有按照这三篇论文的开源Java实现
Hadoop对应MapReduce, Hadoop Distributed File System (HDFS)对应Google FS, Hbase对应Bigtable。不过在性能上Hadoop比Google要差很多,主要原因应该是谷歌是用C++实现的,以及初期开源版本不完善
Google FS
- GFS是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。它运行于廉价的普通硬件上,提供容错功能。
- 一般的数据检索都是用数据库系统,但是 Google 拥有全球上百亿个 Web 文档,如果用常规数据库系统检索,数据量达到 TB 量级后速度就非常慢了。正是为了解决这个问题,Google 构建出了 GFS。
- GFS 是一个大型的分布式文件系统,为 Google 大数据处理系统提供海量存储,并且与 MapReduce 和 BigTable 等技术结合得十分紧密,处于系统的底层。它的设计受到 Google 特殊的应用负载和技术环境的影响。相对于传统的分布式文件系统,为了达到成本、可靠性和性能的最佳平衡,GFS 从多个方面进行了简化。
- GFS 使用廉价的商用机器构建分布式文件系统,将容错的任务交由文件系统来完成,利用软件的方法解决系统可靠性问题,这样可以使得存储的成本成倍下降。
- 由于 GFS 中服务器数目众多,在 GFS 中,服务器死机现象经常发生,甚至都不应当将其视为异常现象。所以,如何在频繁的故障中确保数据存储的安全,保证提供不间断的数据存储服务是 GFS 最核心的问题。
- GFS 的独特之处在于它采用了多种方法,从多个角度,使用不同的容错措施来确保整个系统的可靠性。
- GFS 的系统架构如图 1 所示,主要由一个 Master Server(主服务器)和多个 Chunk Server(数据块服务器)组成。
- Master Server 主要负责维护系统中的名字空间,访问控制信息,从文件到块的映射及块的当前位置等元数据,并与 Chunk Server 通信。
- Chunk Server 负责具体的存储工作。数据以文件的形式存储在 Chunk Server 上。Client 是应用程序访问 GFS 的接口。
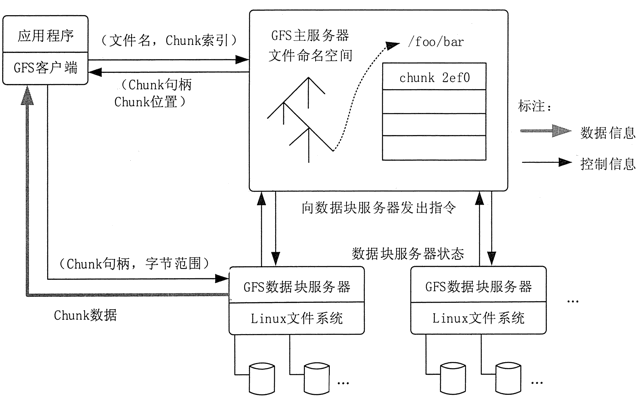
Master Server 的所有信息都存储在内存里,启动时信息从 Chunk Server 中获取。这样不但提高了 Master Server 的性能和吞吐量,也有利于 Master Server 宕机后把后备服务器切换成 Master Server。
GFS 的系统架构设计有两大优势。
Client 和 Master Server 之间只有控制流,没有数据流,因此降低了 Master Server 的负载。
由于 Client 与 Chunk Server 之间直接传输数据流,并且文件被分成多个 Chunk 进行分布式存储,因此 Client 可以同时并行访问多个 Chunk Server,从而让系统的 I/O 并行度提高。
Google 通过减少 Client 与 Master Server 的交互来解决 Master Server 的性能瓶颈冋题。Client 直接与 Chunk Server 进行通信,Master Server 仅提供查询数据块所在的 Chunk Server 的详细位置的功能。
数据块设计成 64MB,也是为了让客户端和 Master Server 的交互减少,让主要数据流量在客户端程序和 Chunk Server 之间直接交互。总之,GFS 具有以下特点。
1)采用中心服务器模式,带来以下优势。
可以方便地增加 Chunk Server。
Master Server可以掌握系统内所有 Chunk Server 的情况,方便进行负载均衡。
不存在元数据的一致性问题。
2)不缓存数据,具有以下优势。
文件操作大部分是流式读/写,不存在大量重复的读/写,因此即使使用缓存对系统性能的提高也不大。
Chunk Server 上的数据存储在本地文件系统上,即使真的出现频繁存取的情况,本地文件系统的缓存也可以支持。
若建立系统缓存,那么缓存中的数据与 Chunk Server 中的数据的一致性很难保证。
Chunk Server 在硬盘上存储实际数据。Google 把每个 chunk 数据块的大小设计成 64MB,每个 chunk 被复制成 3 个副本放到不同的 Chunk Server 中,以创建冗余来避免服务器崩溃。如果某个 Chunk Server 发生故障,Master Server 便把数据备份到一个新的地方。
MapReduce
GFS 解决了 Google 海量数据的存储问题,MapReduce 则是为了解决如何从这些海量数据中快速计算并获取期望结果的问题。
MapReduce 是由 Google 开发的一个针对大规模群组中的海量数据处理的分布式编程模型。
MapReduce 实现了 Map 和 Reduce 两个功能。Map 把一个函数应用于集合中的所有成员,然后返回一个基于这个处理的结果集,而 Reduce 是把两个或更多个 Map 通过多个线程、进程或者独立系统进行并行执行处理得到的结果集进行分类和归纳。
用户只需要提供自己的 Map 函数及 Reduce 函数就可以在集群上进行大规模的分布式数据处理。这一编程环境能够使程序设计人员编写大规模的并行应用程序时不用考虑集群的并发性、分布性、可靠性和可扩展性等问题。应用程序编写人员只需要将精力放在应用程序本身,关于集群的处理问题则交由平台来完成。
与传统的分布式程序设计相比,MapReduce 封装了并行处理、容错处理、本地化计算、负载均衡等细节,具有简单而强大的接口。正是由于 MapReduce 具有函数式编程语言和矢量编程语言的共性,使得这种编程模式特别适合于非结构化和结构化的海量数据的搜索、挖掘、分析等应用。
BigTable
BigTable 是 Google 设计的分布式数据存储系统,是用来处理海量数据的一种非关系型数据库。BigTable 是一个稀疏的、分布式的、持久化存储的多维度排序的映射表。
BigTable 的设计目的是能够可靠地处理 PB 级别的数据,并且能够部署到上千台机器上。Google 设计 BigTable 的动机主要有以下 3 个方面。
1)需要存储的数据种类繁多。
Google 目前向公众开放的服务很多,需要处理的数据类型也非常多,包括 URL、网页内容和用户的个性化设置等数据。
2)海量的服务请求。
Google 运行着目前世界上最繁忙的系统,它每时每刻处理的客户服务请求数量是普通的系统根本无法承受的。
3)商用数据库无法满足 Google 的需求。
一方面,传统的商用数据库的设计着眼点在于通用性,Google 的苛刻服务要求根本无法满足,而且在数量庞大的服务器上根本无法成功部署传统的商用数据库。另一方面,对于底层系统的完全掌控会给后期的系统维护和升级带来极大的便利。
在仔细考察了 Google 的日常需求后,BigTable 开发团队确定了 BigTable 设计所需达到的几个基本目标。
1)广泛的适用性
需要满足一系列 Google 产品而并非特定产品的存储要求。
2)很强的可扩展性
根据需要随时可以加入或撤销服务器。
3)高可用性
确保几乎所有的情况下系统都可用。对于客户来说,有时候即使短暂的服务中断也是不能忍受的。
4)简单性
底层系统的简单性既可以减少系统出错的概率,也为上层应用的开发带来了便利。
BigTable 完全实现了上述目标,已经在超过 60 个 Google 的产品和项目上得到了应用,包括 Google Analytics、GoogleFinance、Orkut、Personalized Search、Writely 和 GoogleEarth等。
以上这些产品对 Bigtable 提出了迥异的需求,有的需要高吞吐量的批处理,有的则需要及时响应,快速返回数据给最终用户。它们使用的 BigTable 集群的配置也有很大的差异,有的集群只需要几台服务器,而有的则需要上千台服务器。
大数据2.0时代-重要的Spanner
为了解决大规模分布式数据库库的问题,谷歌设计了Spanner系统,并发表相应论文,再一次引领了业界。
Spanner的扩展性达到了令人咋舌的全球级,可以扩展到数百万的机器。
Spanner是个可扩展,多版本,全球分布式还支持同步复制的数据库。他是Google的第一个可以全球扩展并且支持外部一致 的事务。Spanner能做到这些,离不开一个用GPS和原子钟实现的时间API。这个API能将数据中心之间的时间同步精确到10ms以内。因此有几个 给力的功能:无锁读事务,原子schema修改,读历史数据无block。
基于Spanner发展出来的不同产品有RocksDB, TiDB等等
简介
Spanner是谷歌设计、构建和部署的、可横向扩展的、全球分布式数据库。从一个最高的抽象层级来看,Spanner将数据散布在很多Paxos [21] 的状态机中,这些 Paxos 状态机位于遍布在全球的数据中心里。 通过Replication保证全球可用性和数据的就近访问(数据本地性);Spanner的Client端可以在多个副本之间自动完成故障切换,并自动从故障的副本重新定向到正常的副本上进行数据访问。当数据量或者服务器的数据发生变化的时候Spanner可以自动完成数据在状态机之间的重分布,并且Spanner还自动在多个状态机之间(甚至可以在多个数据中心之间)进行数据迁移从而进行负载均衡和故障处理。 Spanner被设计为:可扩展到跨数百个数据中心的上百个服务器,并且可以处理和管理数万亿数据行数据。
应用程序在使用Spanner的时候,即使面临大范围的自然灾害也可以借助于Spanner中跨大陆的数据复制机制来实现数据库服务的高可用。Spanner的第一个用户是F1 [35],F1是对Google广告后台服务的重新实现。F1在Spanner中的数据在美国国内部署了5个副本。
大多数其他的应用会在一个地理区域内的3到5个数据中心之间放置数据副本,但是高可用性相对就会比较弱。也就是对于大部分的应用来说,只要能够从1-2个数据中心不可用情况下进行服务恢复,相对于高可用而言,他们更倾向于保证低延时。
Spanner的主要工作就是管理跨数据中心的数据副本,但是我们基于分布式系统基础架构也花费的很大的时间和精力来设计和实现重要的数据库功能特性。虽然在google内部有很多项目都在很愉快地使用Bigtable [9],我们还是会不断的收到来自于Bigtable的用户的抱怨,这些客户抱怨Bigtable 无法很好的服务于一些应用:Schema很复杂且多变的应用或者对跨地域复制具有强一致性要求的应用(其他的用户也有类似的抱怨 [37]) 。在Google内部的很多应用选择使用,虽然在Google Megastore 的写入吞吐量比较低,但是由于其半关系型数据模型和对同步复制的支持,很多应用仍然选择使用 Megastore [5]。因此Spanner已经从一个类似BigTable的多版本的Key-Value存储演变成了一个带有时间属性的多版本数据库。 数据存储在模式化的半关系型存储表中;通过不同的提交时间戳将数据划分为不同的版本;根据配置的不同的垃圾回收策略,对不同的老版本的数据进行垃圾回收;并且应用也可以通过指定特定的时间戳读取老版本的数据。Spanner支持通用的事务,并且提供了基于SQL的查询语句。
作为一个全球范围的分布式数据库,Spanner提供了一些很有意思的特性。
第一:应用程序可以在很细的粒度上对数据的副本数进行动态的控制。应用程序可以指定:
【1】哪些数据中心包含哪些数据
【2】数据离用户多远(为了保证读延时)
【3】每个数据副本之间的距离有多远(为了保证写延时)
【4】总共维护多少个数据副本(为了保证可用性和读性能)
数据也可以在不同的数据中心之间动态地、透明地来回迁移,从而能够动态地平衡各个数据中心的资源使用率。
第二:Spanner还具备两个独有的特性:提供外部一致性[16]读写和基于某个时间戳的跨数据库的全球一致性读。这两个特性使得Spanner可以在全球范围内或者在事务正在执行的同时都可以执行一致性备份、一致性MapReduce执行[12]和原子性Schema信息变更。
这些特性得益于Spanner对于所有的事务(即使是分布式事务)都赋予全球范围一致的时间戳。时间戳反映了序列化的顺序。此外这种序列化顺序也满足了外部一致性(幂等性,线性化[20])的要求;若事务T1在另一个事务T2之前提交,那么T1的提交时间就要被T2的提交时间要小。Spanner是第一个在全球范围内提交这种保证的系统。
实现这种保证的关键就是一个全新的TrueTime API。该API直接提供一个不确定时钟,而Spanner对事务顺序性的保证就依赖于不确定时钟的波动边界。若时钟的波动时间窗口很大,则Spanner就会一直等待直到晚于不确定时钟的波动时间窗口的最后时间再做后续处理,
这个TrueTime API由谷歌的集群管理软件实现并提供,其通过多时钟值参考对比(GPS和原子钟),选出相对而言最准确的时钟值,从而保证不确定时钟的时间窗口的宽度足够小(通常小于10ms)。
本文的第二部分描述了Spanner的架构、特性和工程设计决策。第三部分描述了新的TrueTime API以及该TrueTime API的大体实现。第四部分说明了spanner如何利用TrueTime API来实现分布式事务的外部一致性,无锁只读事务和Schema的原子性变更。第五部分提供了Spanner和True Time API的benchmark性能基准测试报告并讨论了F1。第6,7,8部分说明了未来的一些相关工作计划和文章总结。
可以参考下面的内容
www.jianshu.com/p/6ae6e7989161
时间继续发展到大数据3.0时代的门口,google再次给于助攻, Dataflow
Dataflow解决了大规模实时分布式计算的理论和模型问题
对应的开源产品就是Flink
Dataflow模型在2015年由一群来自Google的大佬提出,目前Google Cloud上也有对应的服务提供,名字就叫Cloud Dataflow,通过Apache Beam主打“简单的流式与批量大数据处理”(Simplified stream and batch data processing)
- 该模型处理的是大规模的、无界的、乱序的数据;
- 在处理这种数据的同时,需要兼顾正确性、时间延迟和资源消耗;
- 该模型是可实现的。
什么是“无界”数据
Google的大佬们认为,当我们提“流式”(stream)这个词时,实际上表达的意思就是在源源不断的连续数据上进行处理。反之,当我们提“批量”(batch)这个词时,就意味着在有限的一块或多块数据上进行处理,亦即“有界”。论文中倾向于用无界/有界来代替流式/批量,因为后者听起来像是在描述计算引擎的语义,而前者才是数据本身的特征。
对无界数据的处理必然要及时输出结果,否则就毫无意义。而输出的结果天然是有界数据,因此在Dataflow模型中,批量处理可以作为流式处理的一个子问题,目的是达到批流融合。这与传统Lambda架构(官网在这里)相比无疑是先进的,因为后者需要维护两套不同的组件分别用来做流式和批量处理,非常繁琐。
什么是“乱序”数据
我们都理解在数据的生成、采集、传输过程中,不可避免地会带来各种各样的延迟,这就意味着处理无界数据时,其顺序很有可能与业务逻辑的原始顺序不同。举个浅显的例子:某用户在7时55分浏览了某商品的详情页面,然后在7时56分加入购物车,57分下单购买,但日志队列中的顺序可能会变成“下单→加入购物车→浏览”。
在Lambda架构下的批量处理中,乱序数据造成问题的可能性往往很小。但是在Dataflow的批流融合构想下,必须正确地处理乱序数据才能保证整个大数据服务的正确性,因此非常重要。下面就来深入地看看Dataflow如何解决论文题目中的这些要点。
Dataflow思路概述
事件时间与处理时间
我们首先要分辨清楚Dataflow中最重要的一对基础概念,即事件时间(event time)和处理时间(processing time),说起来也很简单:
- 事件时间就是数据产生一瞬间的时间戳,比如调用某接口时的时间戳;
- 处理时间就是数据进入流式处理程序的时间戳。
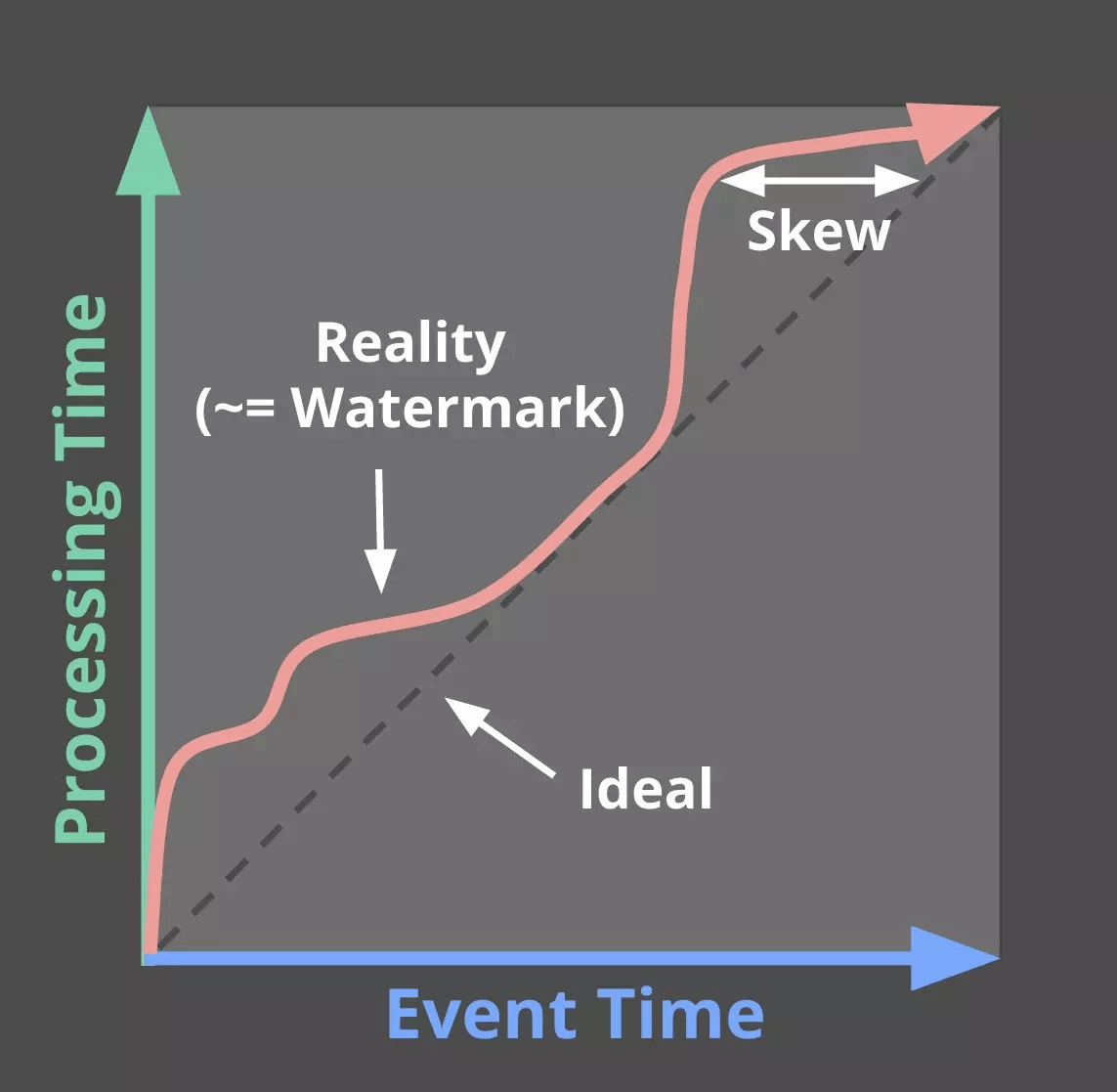
下图示出事件时间和处理时间的关系。在理想情况下,数据总能及时地被处理,两者的关系应该是如虚线所示。但由于各种延迟的存在,实际情况更多地表现为红色粗箭头,两者之间会有一些差距(skew)。
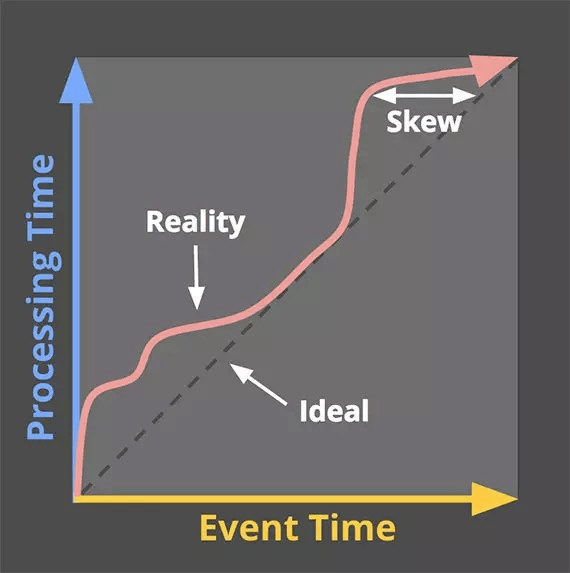
将事件时间和处理时间区别对待,并且采用事件时间作为时间特征,是Dataflow的一大进步。
分解问题
Dataflow将上述无界数据的处理问题分解为4个子问题来考虑:
- 需要产出什么 [What results are being computed];
- 计算什么时间的数据 [Where in event time they are being computed];
- 在哪些时机物化/输出结果 [When in processing time they are materialized];
- 后到的数据如何修正之前的结果 [How earlier results relate to later refinements]。
这样一来就清晰多了。为了解决上面的4个子问题,Dataflow提出了以下这些方案:
- 窗口模型(windowing model),支持基于乱序的事件时间的窗口操作,用于解决Where问题;
- 触发模型(triggering model),能够将数据结果与事件的时间特性绑定,解决When问题;
- 增量更新模型(incremental processing model),能够将后到的数据融合到窗口和触发模型中,解决How问题。
至于最基本的What问题,当然是用户自己要考虑的了。下面分别讨论这三个模型。
Dataflow三大模型
窗口模型
在大学计算机网络课程中,我们都学过窗口的概念,大家明白就好。
前面已经提到过,对无界数据的处理必然要及时输出结果,否则就毫无意义。那么要处理哪个时间范围的数据呢?通过窗口就可以将无界数据时域地划分为一个个的有限数据集,进而能在其上做分组、聚合、连接等比较高级的操作。下图示出乱序事件时间的一种窗口。
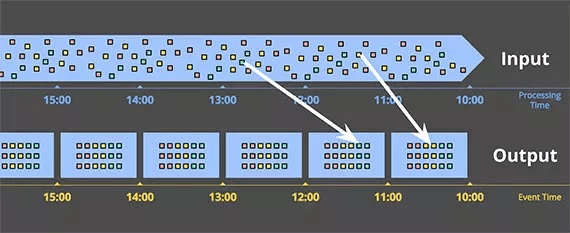
也就是说,Dataflow通过窗口模型将传统流处理中的(key, value)二元组改进为(key, value, event_time, window)四元组。
常见的开窗方式有三种,即固定(fixed/tumbling)窗口,滑动(sliding)窗口,会话(session)窗口,如下图所示。
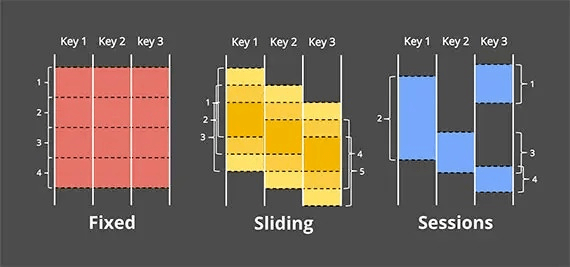
固定窗口显然是最简单的,比如一个5分钟的固定窗口:[7:00, 7:05), [7:05, 7.10), [7:10, 7.15), ...。滑动窗口对我们来说也是老熟人,例如一个窗口时长1小时,滑动时长10分钟的滑动窗口就是以下的时间区间:[7:00, 8:00), [7:10, 8:10), [7:20, 8:20), ...。
会话窗口则不那么常见一些,它是Google在实践中总结出来的,通俗地说就是在一个key连续出现时才形成窗口,如果该key持续不出现超过一定时长,之后再出现就被划分到下一个窗口。这种方式比较灵活,并且容易想到它可以用于用户行为检测、异常检测等方面。
触发模型
如果我们不采用事件时间作为时间特征,而用处理时间的话,就没有必要考虑触发模型,因为窗口的边界与数据没关系。但是一旦用事件时间,由于数据会迟到,窗口的边界就会模糊,也就是无从知道窗口里的数据是否已经齐活了,触发结果的物化变成了一道难题。所以在这里又引入了一个重要的概念,就是水印(watermark)。
水印本质上是个时间戳,对一个无界数据源而言,水印T就表示已经接收到所有t <= T的数据,其他t > T的数据都将被视为迟到,接下来就可以进行输出。在讲解事件时间和处理时间时,图中的红色箭头就是实际的水印时间。
固定窗口显然是最简单的,比如一个5分钟的固定窗口:[7:00, 7:05), [7:05, 7.10), [7:10, 7.15), ...。滑动窗口对我们来说也是老熟人,例如一个窗口时长1小时,滑动时长10分钟的滑动窗口就是以下的时间区间:[7:00, 8:00), [7:10, 8:10), [7:20, 8:20), ...。
会话窗口则不那么常见一些,它是Google在实践中总结出来的,通俗地说就是在一个key连续出现时才形成窗口,如果该key持续不出现超过一定时长,之后再出现就被划分到下一个窗口。这种方式比较灵活,并且容易想到它可以用于用户行为检测、异常检测等方面。
触发模型
如果我们不采用事件时间作为时间特征,而用处理时间的话,就没有必要考虑触发模型,因为窗口的边界与数据没关系。但是一旦用事件时间,由于数据会迟到,窗口的边界就会模糊,也就是无从知道窗口里的数据是否已经齐活了,触发结果的物化变成了一道难题。所以在这里又引入了一个重要的概念,就是水印(watermark)。
水印本质上是个时间戳,对一个无界数据源而言,水印T就表示已经接收到所有t <= T的数据,其他t > T的数据都将被视为迟到,接下来就可以进行输出。在讲解事件时间和处理时间时,图中的红色箭头就是实际的水印时间。
Hadoop and HDFS
其中mapper阶段包括:
(1)数据的读取、
(2)map处理以及写出操作(排序和合并/sort&merge),
而reducer阶段包含:
(1)对mapper端输出数据的获取、
(2)数据合并(sort&merge)、
(3)reduce处理以及写出操作。
那么在这七个子阶段中,能够进行较大力度的进行调优的就是
map端的输出、reducer端的数据合并以及reducer的个数这三个方面的调优操作。
也就是说虽然性能调优包括cpu、内存、磁盘io以及网络这四个大方面,但是从mr程序的执行流程中,我们可以知道主要有调优的是内存、磁盘io以及网络。在mr程序中调优,主要考虑的就是减少网络传输和减少磁盘IO操作,故本次课程的mr调优主要包括服务器调优、代码调优、mapper调优、reducer调优以及runner调优这五个方面。
mapreduce调优
mapreduce.task.io.sort.factor —>mr程序进行合并排序的时候,打开的文件数量,默认为10个.
mapreduce.task.io.sort.mb —> mr程序进行合并排序操作的时候或者mapper写数据的时候,内存大小,默认100M
3. mapreduce.map.sort.spill.percent —> mr程序进行flush操作的阀值,默认0.80。
4. mapreduce.reduce.shuffle.parallelcopies —>mr程序reducer copy数据的线程数,默认5。
5. mapreduce.reduce.shuffle.input.buffer.percent —>reduce复制map数据的时候指定的内存堆大小百分比,默认为0.70,适当的增加该值可以减少map数据的磁盘溢出,能够提高系统能。
6. mapreduce.reduce.shuffle.merge.percent —>reduce进行shuffle的时候,用于启动合并输出和磁盘溢写的过程的阀值,默认为0.66。如果允许,适当增大其比例能够减少磁盘溢写次数,提
高系统性能。同mapreduce.reduce.shuffle.input.buffer.percent一起使用。
7. mapreduce.task.timeout —>mr程序的task执行情况汇报过期时间,默认600000(10分钟),设置为0表示不进行该值的判断。
Uber模式也是一种优化:
1、概念:Uber模式是Hadoop2.0中实现的一种针对MR小作业的优化机制。
即如果作业足够小,则所有task在一个jvm(mrappmaster)中完成要比为每个task启动一个container更划算。
2.下面是该机制的相关参数,这些参数均为客户端配置。
在hadoop2.X版本中新增加了Uber模式运行MR
Hadoop中对Uber模式的定义:
1:mapreduce.job.ubertask.enable=true,首先开启Uber模式,默认是false
2:mapreduce.job.ubertask.maxmaps map任务数的阀值 9
mapreduce.job.ubertask.maxreduces reduce任务数的阀值 1
map的数量<=9, reduce<=1
3:所有的输入文件的总长度<=默认的块的大小(128M)
4:mapreduce.map.memory.mb(默认是1024)<=内存需求(内存需求的大小由yarn.app.mapreduce.am.resource.mb来决定,默认1536M)
5:cpu<=yarn.app.mapreduce.am.resource.cpu-vcores(默认1)
6:采用非链式方式运行MR
Uber模式优点:
针对多个小作业,开启uber模式,mapreduce会将所有的task任务放在一个JVM中完成,就需要每个task都去申请资源,启动一个Container容器,
而是多个task申请一份资源,资源会重复的利用,这样的话可以节省cpu及网络Io,磁盘Io的消耗,节省了job运行的时间。
代码调优,主要是mapper和reducer中,针对多次创建的对象,进行代码提出操作。这个和一般的java程序的代码调优一样。mapper调优主要就是就一个目标:减少输出量。我们可以通过增加combine阶段以及对输出进行压缩设置进行mapper调优。
1.combine介绍:
实现自定义combine要求继承reducer类,特点:
以map的输出key/value键值对作为输入输出键值对,作用是减少网络输出,在map节点上就合并一部分数据。
适用场景,map的输出是数值型的,方便进行统计。
2.压缩设置:
在提交job的时候分别设置启动压缩和指定压缩方式。mapreduce.map.output.compress—>设置是否启动map输出的压缩机制,默认为false。在需要减少网络传输的时候,可以设置为true。
reducer调优主要是通过参数调优和设置reducer的个数来完成。reducer个数调优:
要求:一个reducer和多个reducer的执行结果一致,不能因为多个reducer导致执行结果异常。
规则:一般要求在hadoop集群中的执行mr程序,map执行完成100%后,尽量早的看到reducer执行到33%,可以通过命令hadoop job -status job_id或者web页面来查看。
原因: map的执行process数是通过inputformat返回recordread来定义的;而reducer是有三部分构成的,分别为读取mapper输出数据、合并所有输出数据以及reduce处理,其中第一步要
依赖map的执行,所以在数据量比较大的情况下,一个reducer无法满足性能要求的情况下,我们可以通过调高reducer的个数来解决该问题。
优点:充分利用集群的优势。
缺点:有些mr程序没法利用多reducer的优点,比如获取top n的mr程序。
runner调优其实就是在提交job的时候设置job参数,一般都可以通过代码和xml文件两种方式进行设置。1~8详见ActiveUserRunner(before和configure方法),9详解TransformerBaseRunner(initScans方法)
1. mapred.child.java.opts: 修改childyard进程执行的jvm参数,针对map和reducer均有效,默认:-Xmx200m
2. mapreduce.map.java.opts: 需改map阶段的childyard进程执行jvm参数,默认为空,当为空的时候,使用mapred.child.java.opts。
3. mapreduce.reduce.java.opts:修改reducer阶段的childyard进程执行jvm参数,默认为空,当为空的时候,使用mapred.child.java.opts。
4. mapreduce.job.reduces —> 修改reducer的个数,默认为1。可以通过job.setNumReduceTasks方法来进行更改。
5. mapreduce.map.speculative:是否启动map阶段的推测执行,默认为true。其实一般情况设置为false比较好。可通过方法job.setMapSpeculativeExecution来设置。
6. mapreduce.reduce.speculative:是否需要启动reduce阶段的推测执行,默认为true,其实一般情况设置为fase比较好。可通过方法job.setReduceSpeculativeExecution来设置。
7. mapreduce.map.output.compress —>设置是否启动map输出的压缩机制,默认为false。在需要减少网络传输的时候,可以设置为true。
8. mapreduce.map.output.compress.codec —>设置map输出压缩机制,默认为org.apache.hadoop.io.compress.DefaultCodec,推荐使用SnappyCodec(在之前版本中需要进行安装操作,
现在版本不太清楚,安装参数:www.cnblogs.com/chengxin1982/p/3862...)
9. hbase参数设置
由于hbase默认是一条一条数据拿取的,在mapper节点上执行的时候是每处理一条数据后就从hbase中获取下一条数据,通过设置cache值可以一次获取多条数据,减少网络数据传输。
Hive-建设中
Spark
出处:北京英浦教育
本作品采用《CC 协议》,转载必须注明作者和本文链接









 关于 LearnKu
关于 LearnKu




推荐文章: