
图论之带权图「最小生成树prim的优化」
0 / 0 / 创建于 5年前 /
 iceymoss 的个人博客
iceymoss 的个人博客
带权图最小生成树prim的优化
一、优化内容
- 在prim算法中,使用while循环对每一个节点进行遍历,其中对边进行出堆操作进行了E遍,堆邻边进行遍历为E遍,总体来说prim的时间复杂度为:O(ElogE)。
- 在prim中会对每一条边加入堆中,但取出时,取出的边有可能不再是横切边;那么我们现在要维护一个数据结构用来存储和邻节点连接最短的横切边,在不断的扩大红色节点时只需维护更新每个节点相连的最短的横切边就可以了;而这个数据结构能够取出最小值,又能让其元素更新——最小索引堆(Min Index Heap)。
二、prim的优化过程
如下图:
最小索引堆开节点大小的空间用来存放v-1的边,将0空闲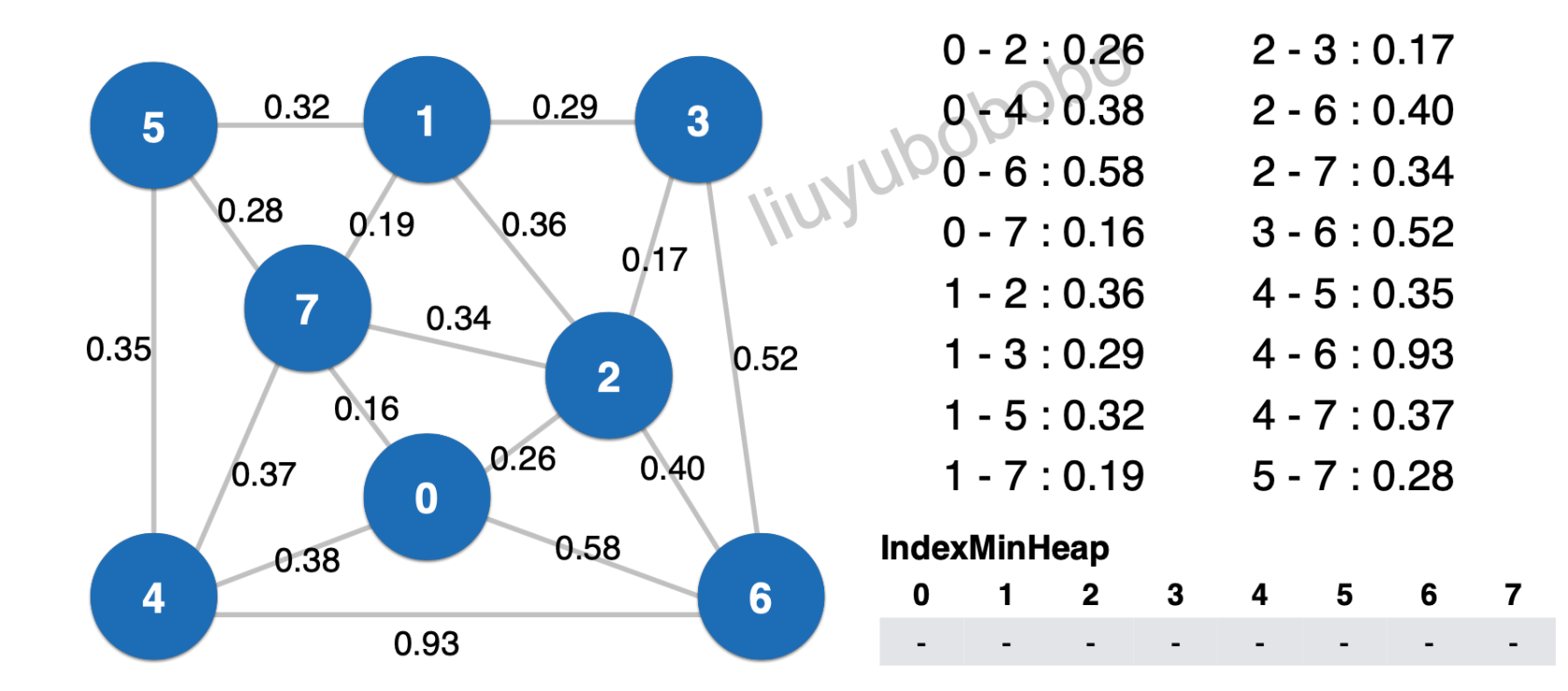
从0开始: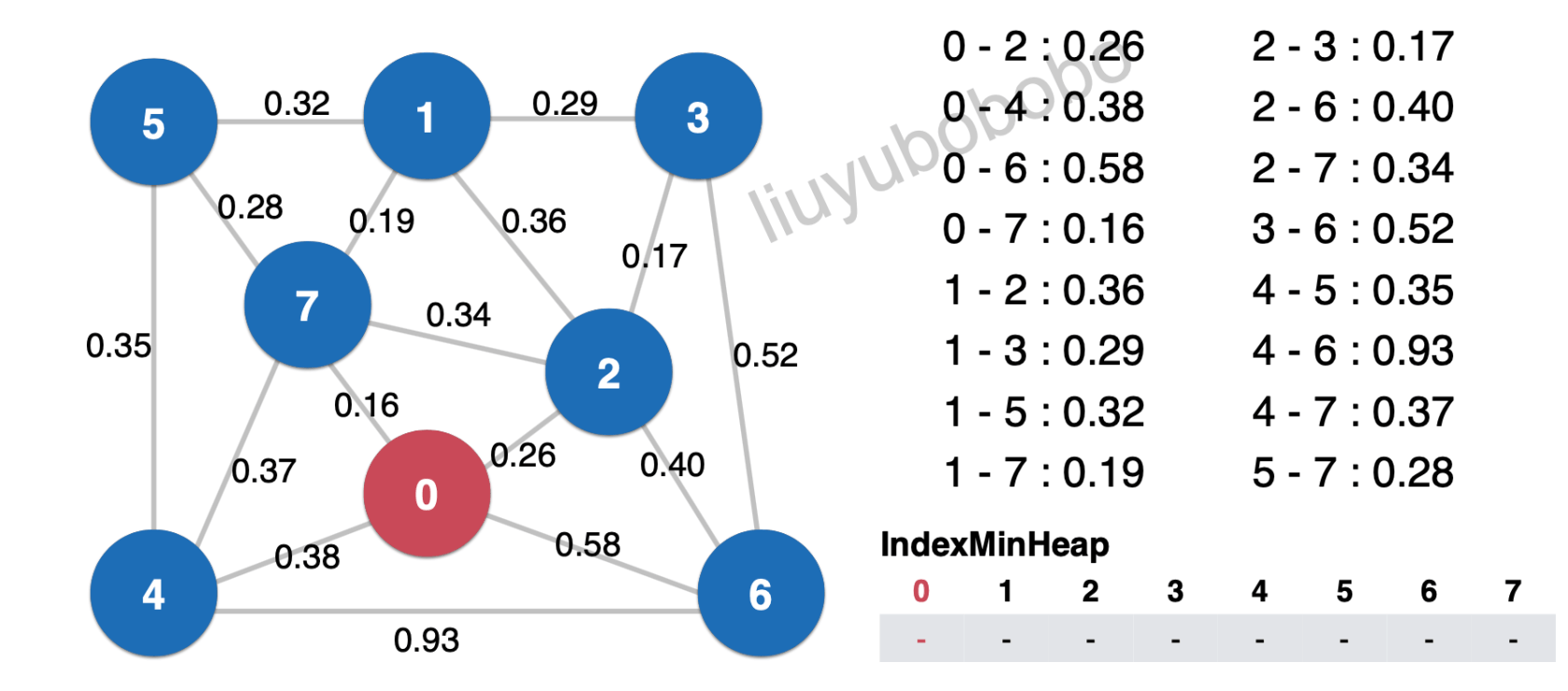
最小索引堆为空,将横切边依次放入最小索引堆中: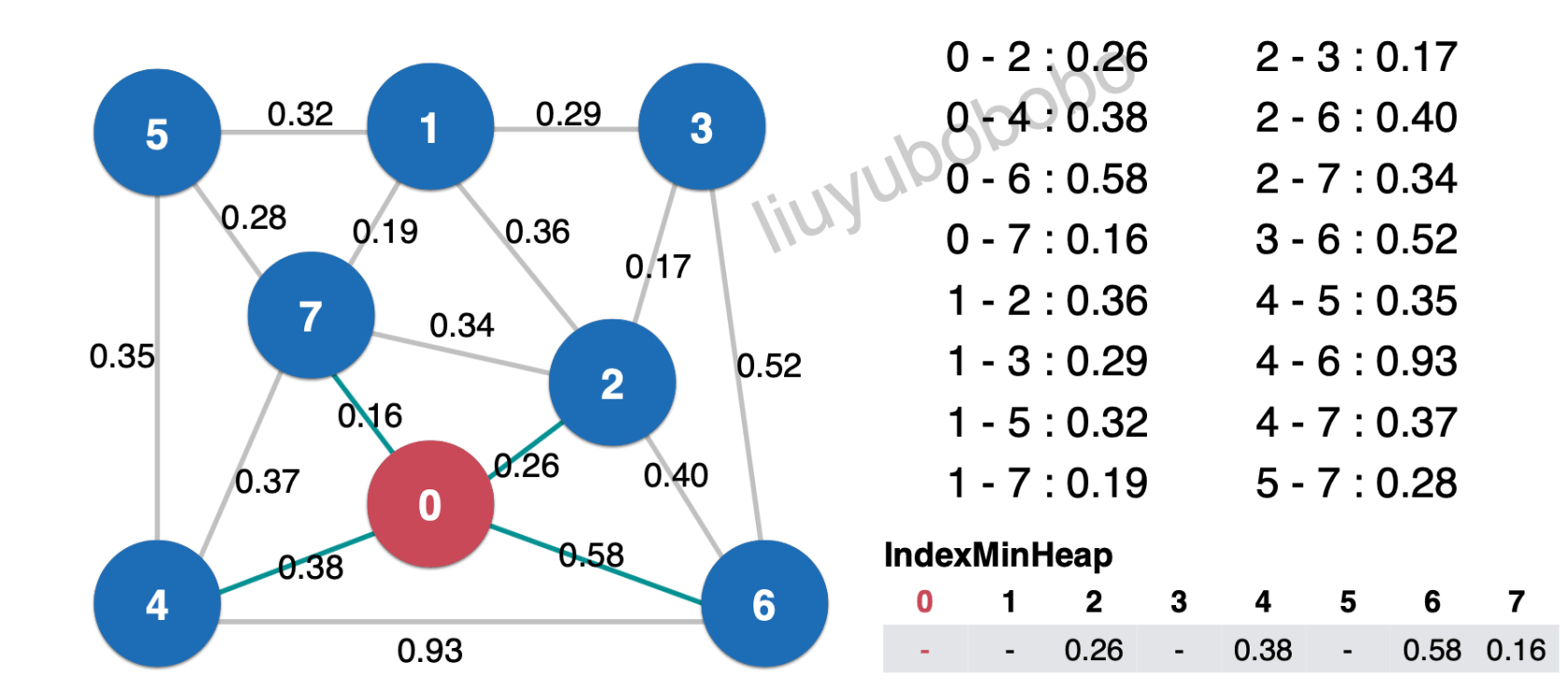
取出最小索引堆堆顶元素0.16,并将其退出最小索引堆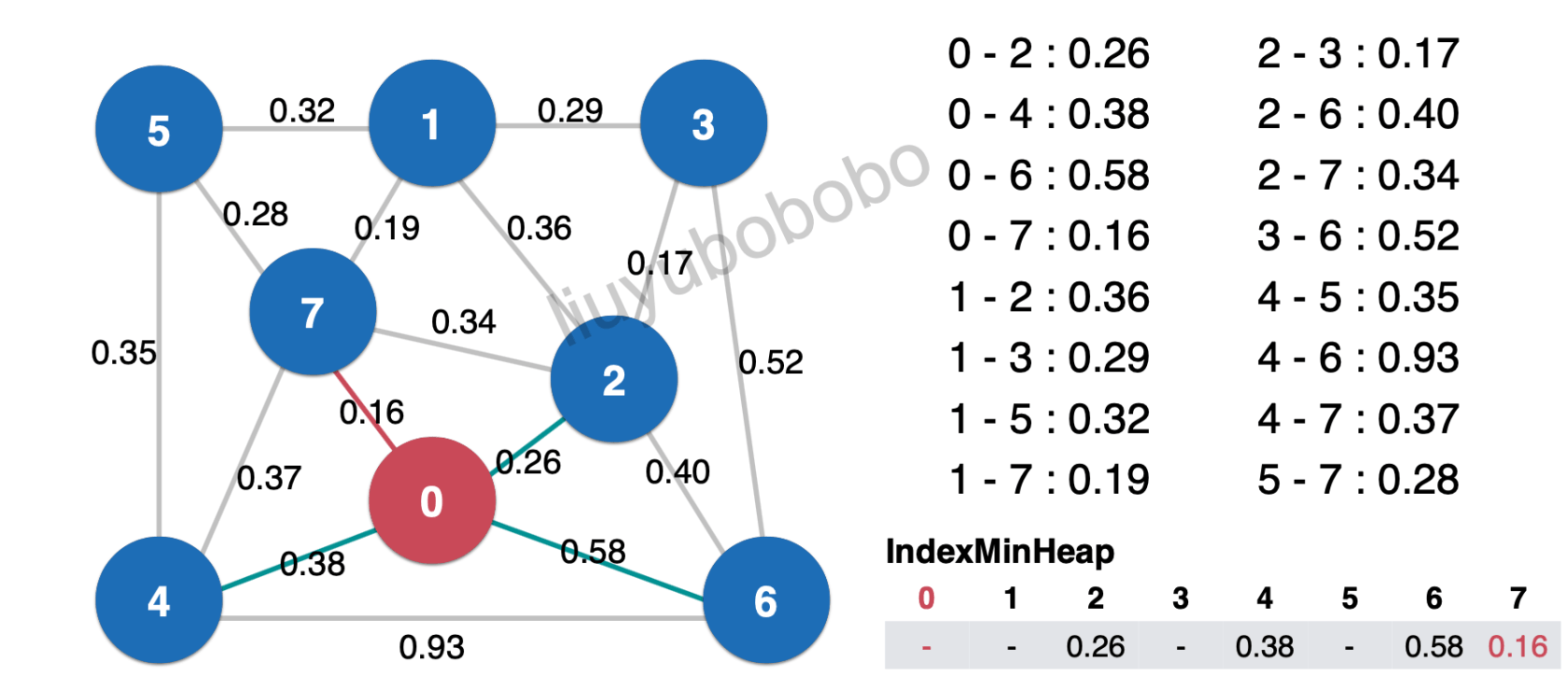
然后将最小生成树中的边 0.16相连的未被访问节点加入红色,并依次遍历节点7相连的边:
在最小索引堆中和节点1相连的值为空,则将新产生的横切中最小的横切7-1边0.19放入最小索引堆中
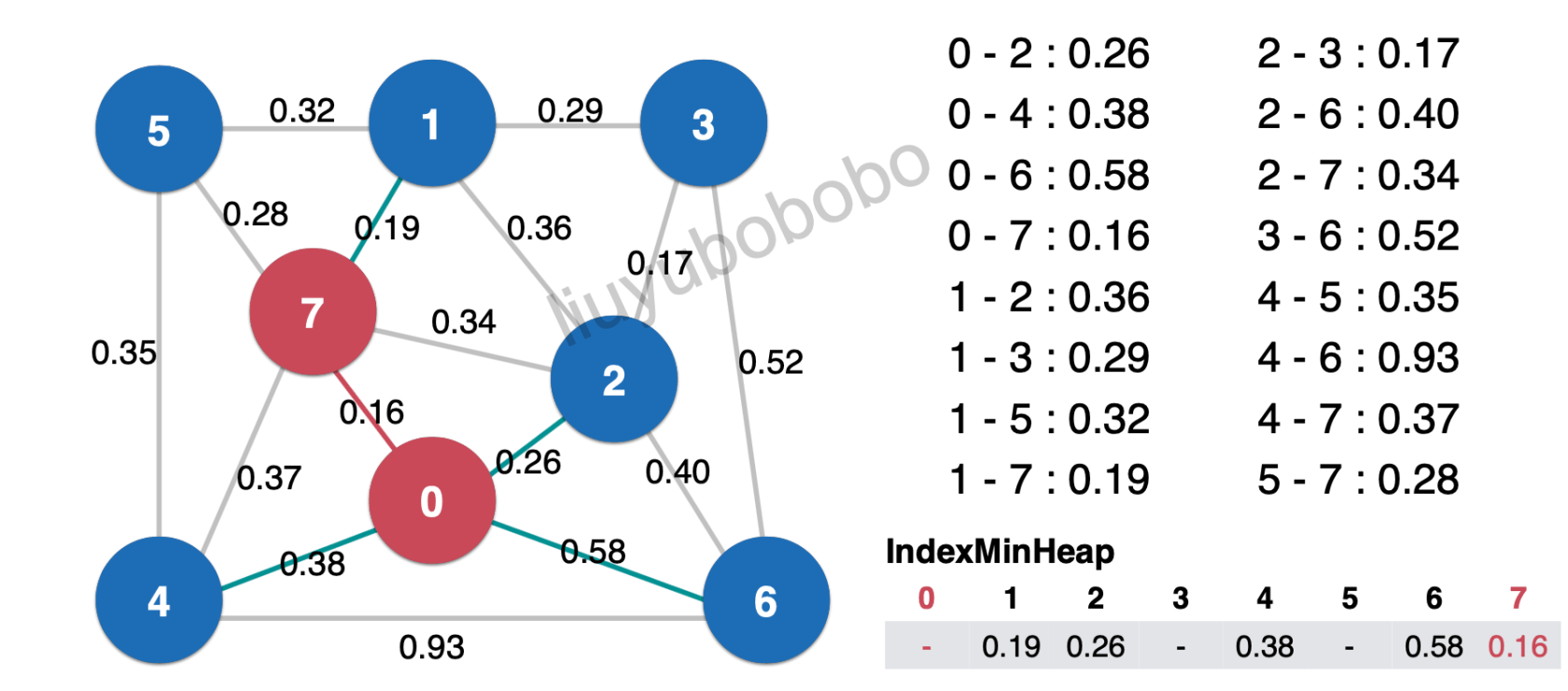
遍历7-2边0.34,此时最小索引堆中和节点2相连边的权值为0.26 这时需要比较0.26 < 0.34,所以将0.34丢弃。
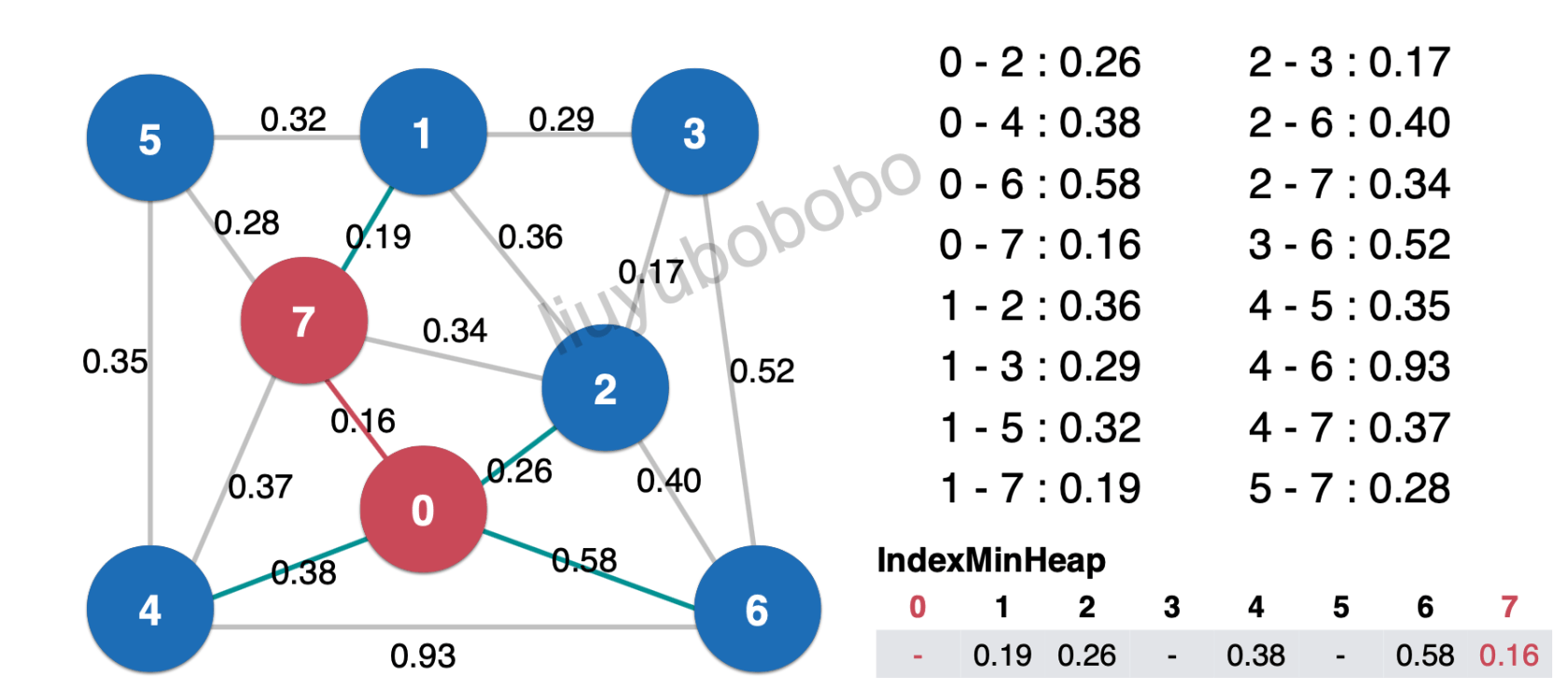
- 此时再看图中边7-4边0.37,跟最小索引堆中和节点4相连的边0.38比较,0.37 < 0.38, 所以将最小索引堆中和节点4相连的边更新为0.37,与此同时也相当于把0.38丢弃了(基于切分定理),如图:
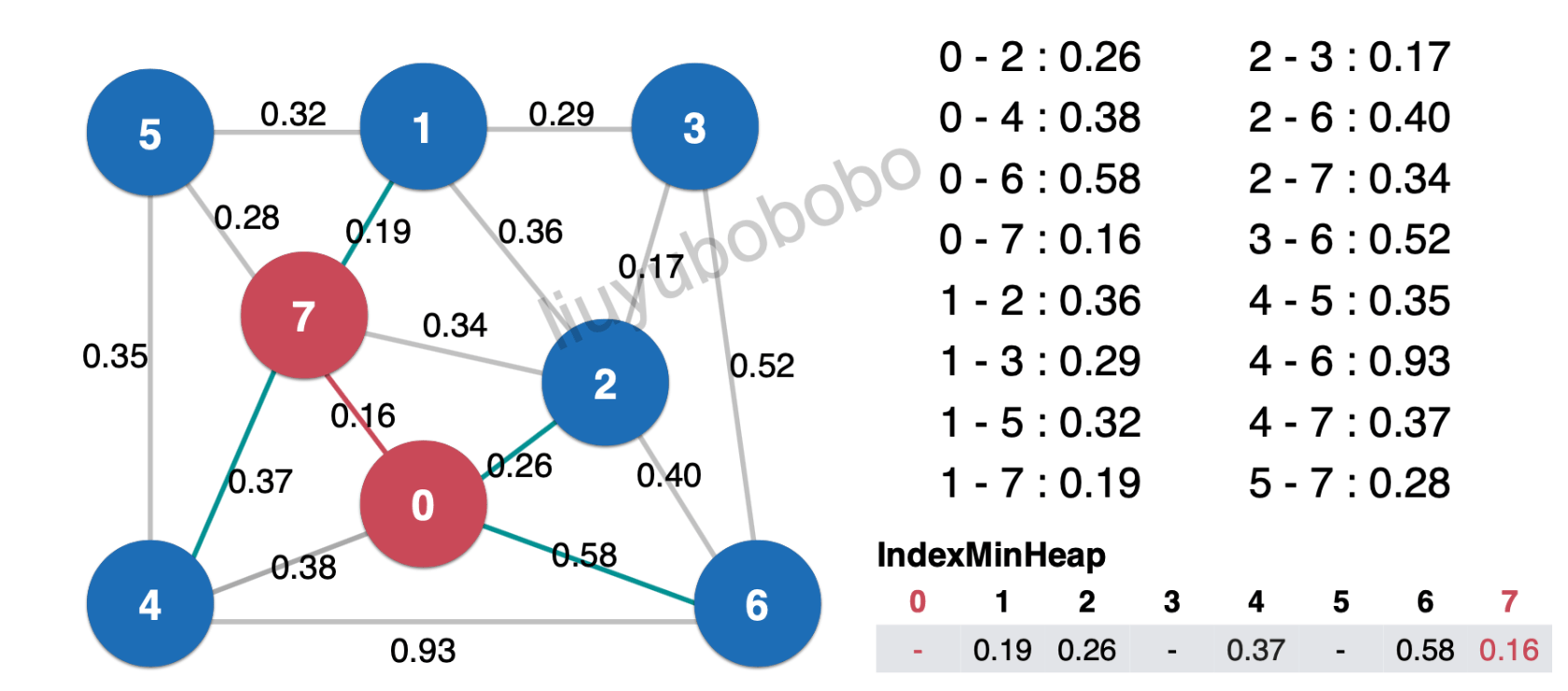
- 再看图中7—5的边为0.28,而在最小索引堆中节点5为空,则将0.28加入堆中:
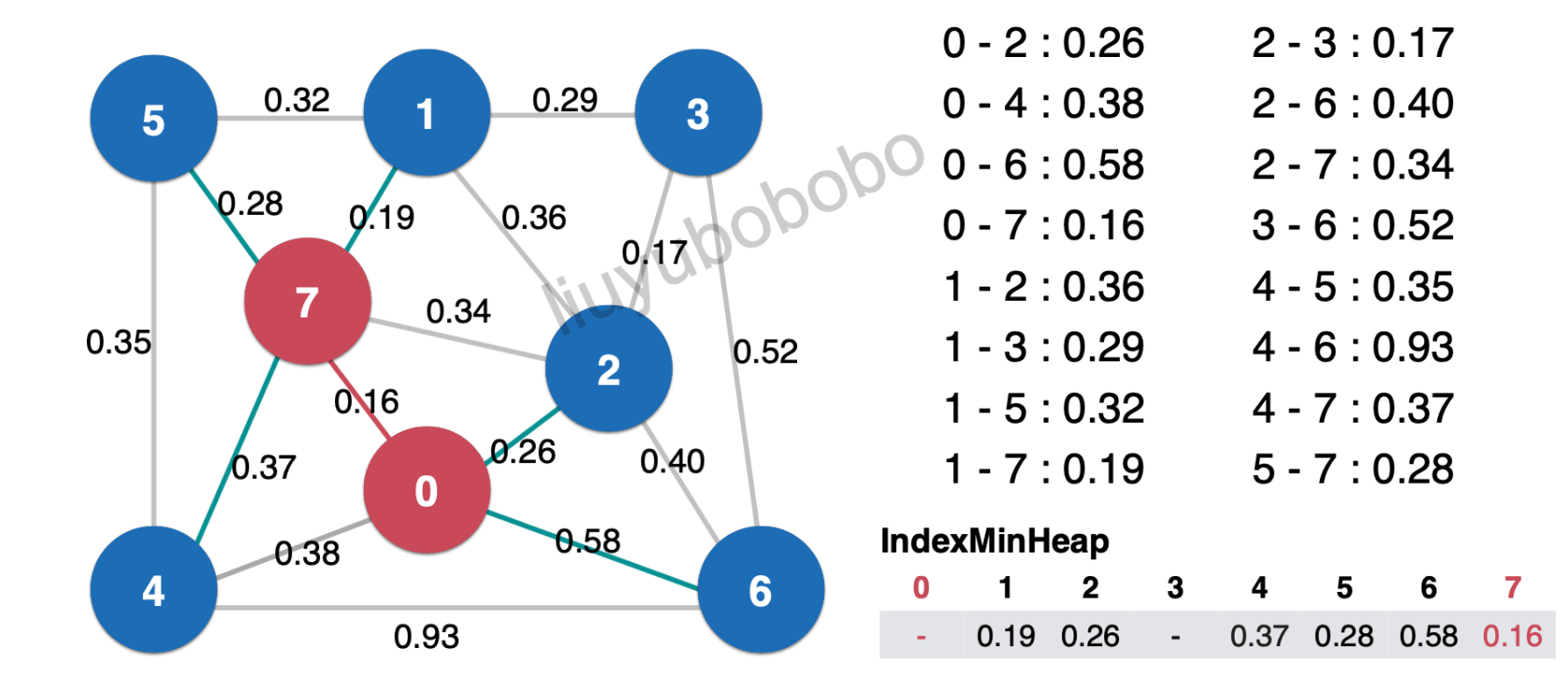
然后再清楚最小索引堆中堆顶元素0.19,加入最小生成树中,这时就需要将边0.19相连且未被访问过的节点加入红色:
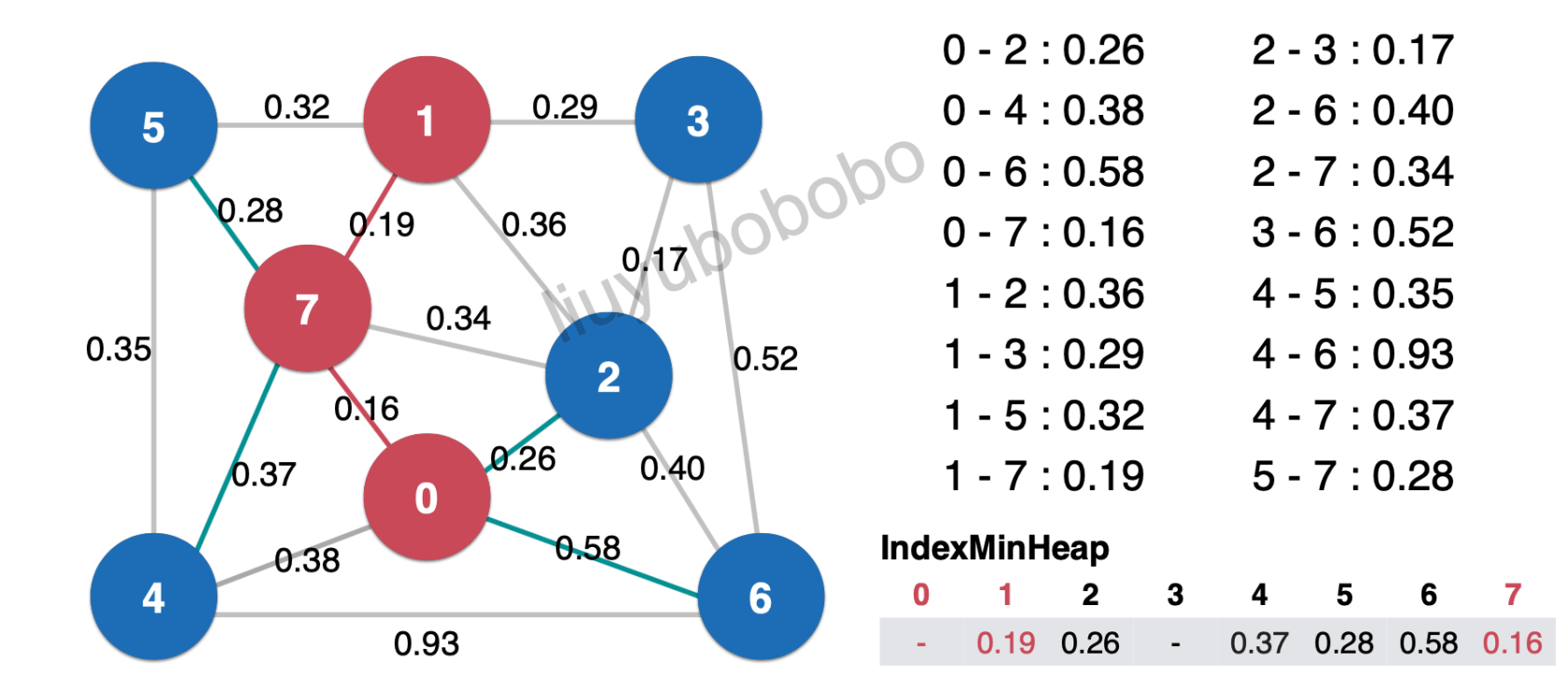
将节点1加入红色阵营后,然后依次对与节点1相连且未被访问过的边进行遍历:
对图中1-2边0.36访问,在最小索引堆中与节点2相连的边0.26;0.26 < 0.36 , 将0.36丢弃

如下图:
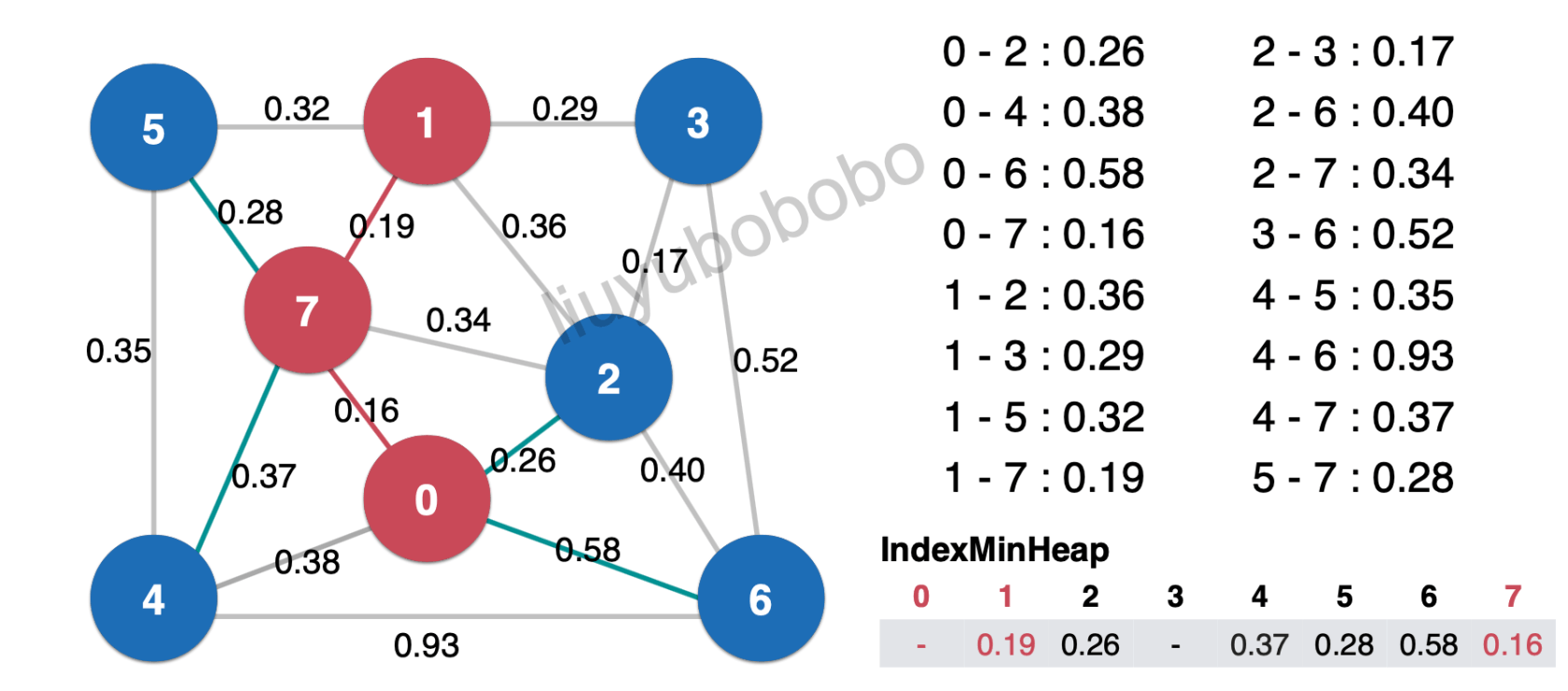
- 然后对1-5边0.32访问,此时在最小索引堆中和节点5相连的边0.28; 0.28 < 0.32,将0.32丢弃:
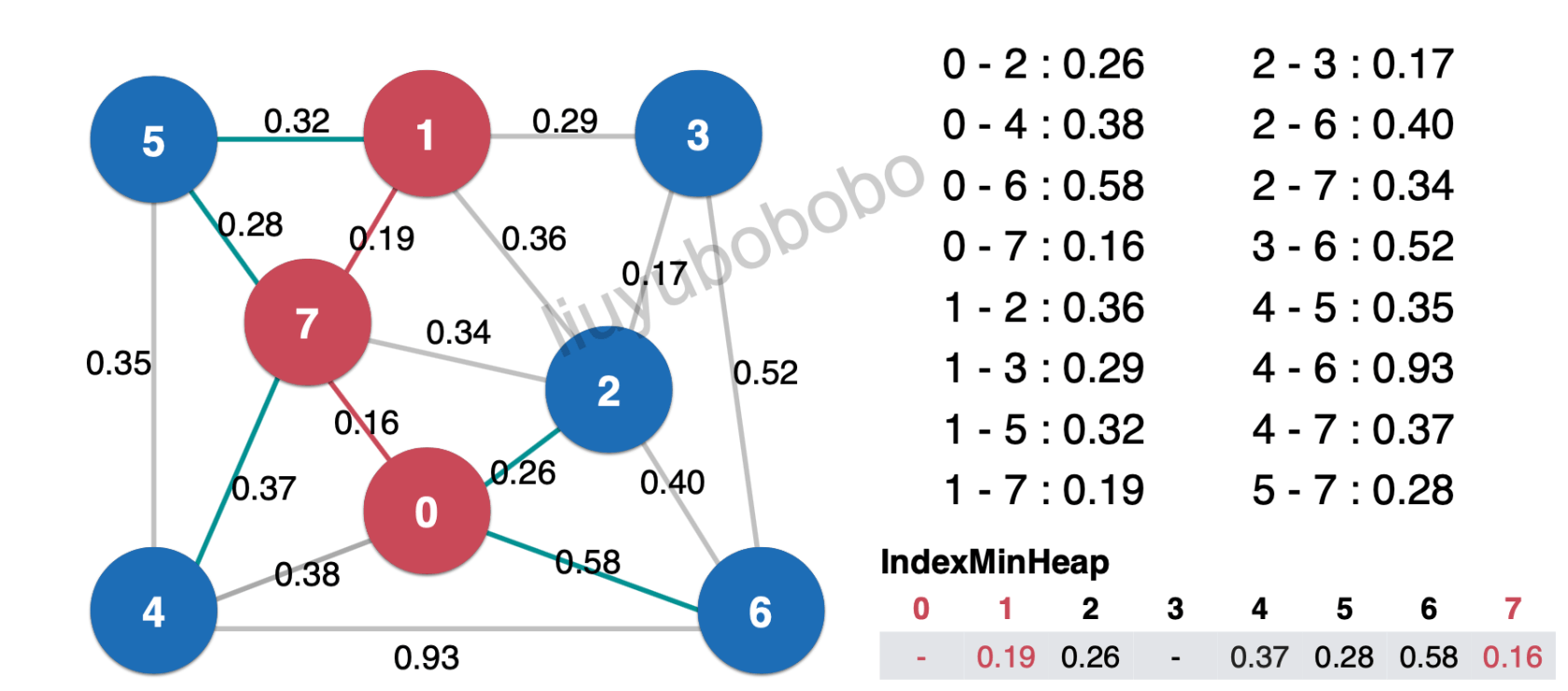
如下图,丢弃0.32:

- 下面对1-3边0.29访问,在最小索引堆中与节点3相连的节点为空,直接加入堆中:
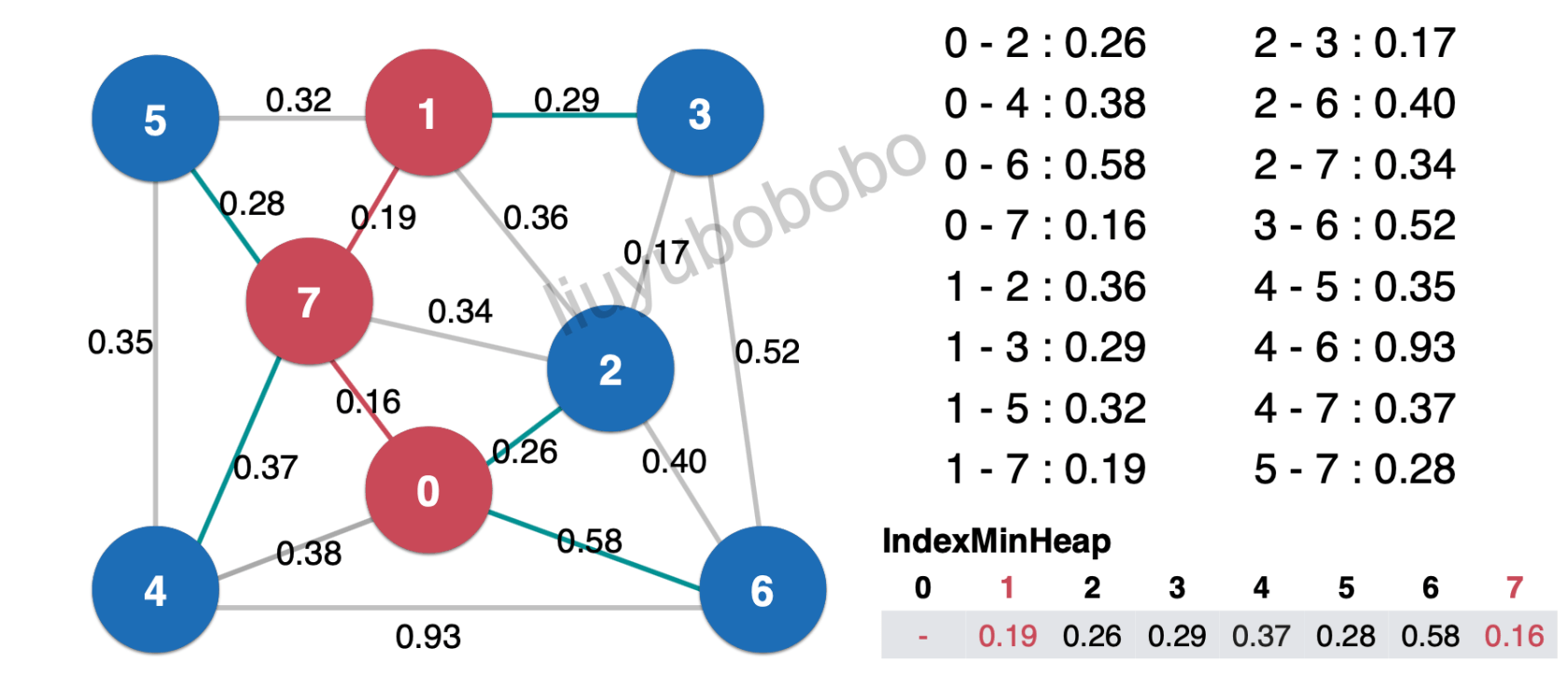
下面再一次从最小索引堆中将最小元素取出:0.26放入最小生成树中
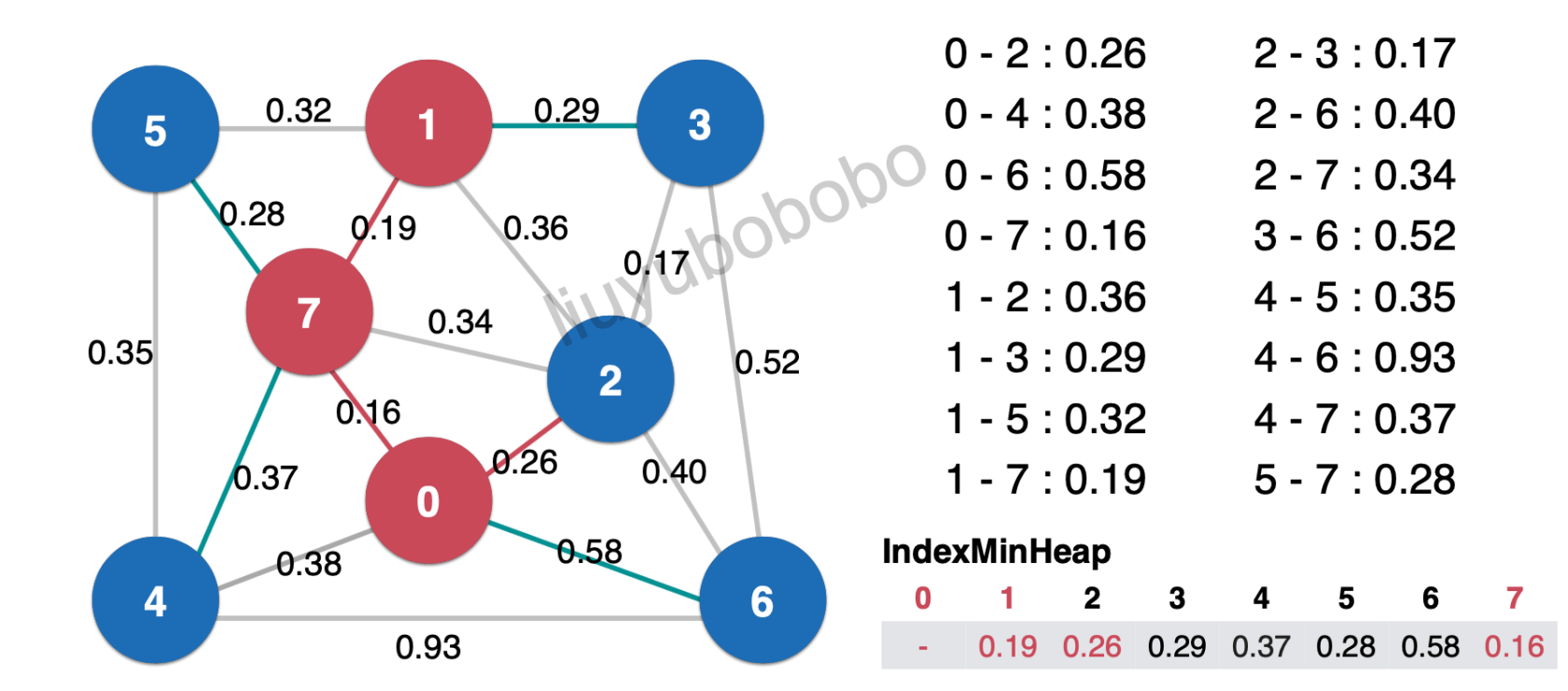
对和边0.26相连且未被访问的节点加入红色阵营
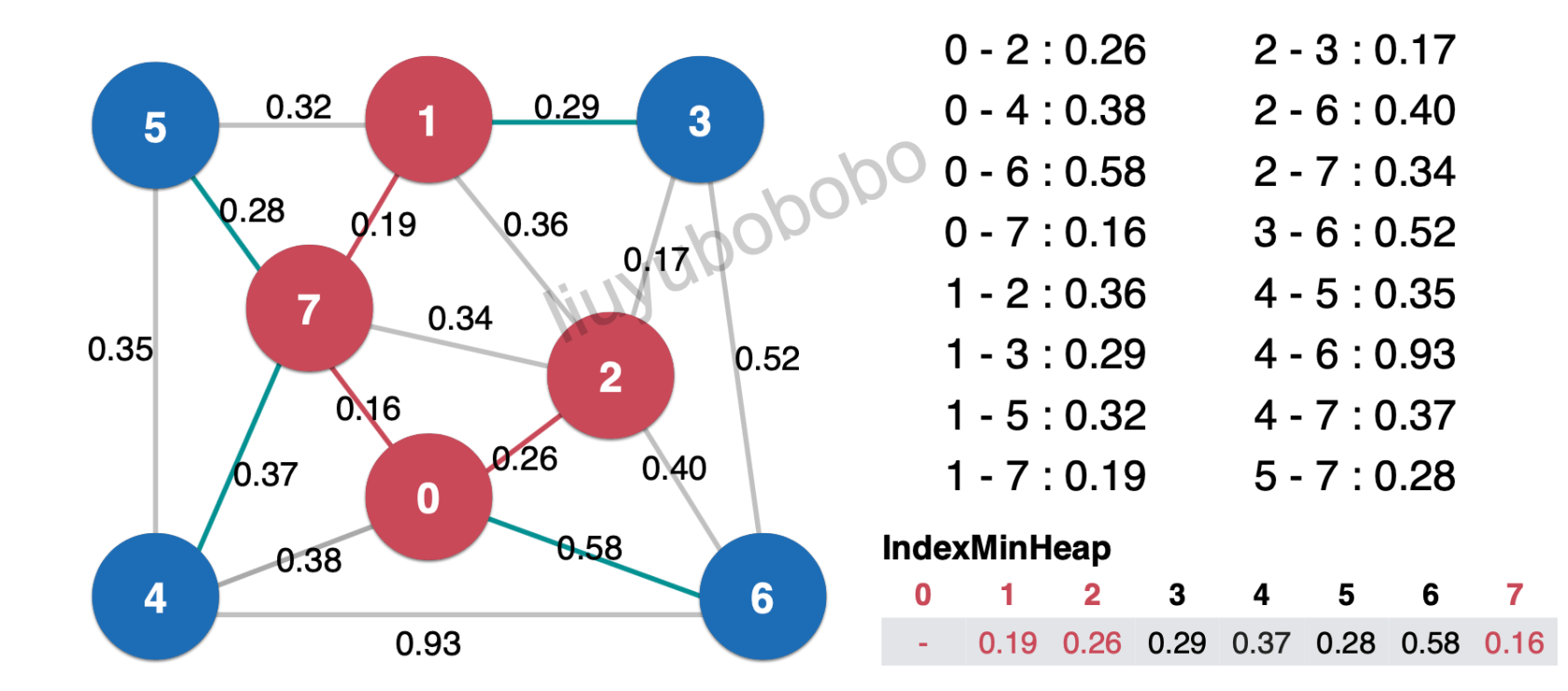
同理对未被访问过的边进行遍历,比较,放入,取出,最后得:
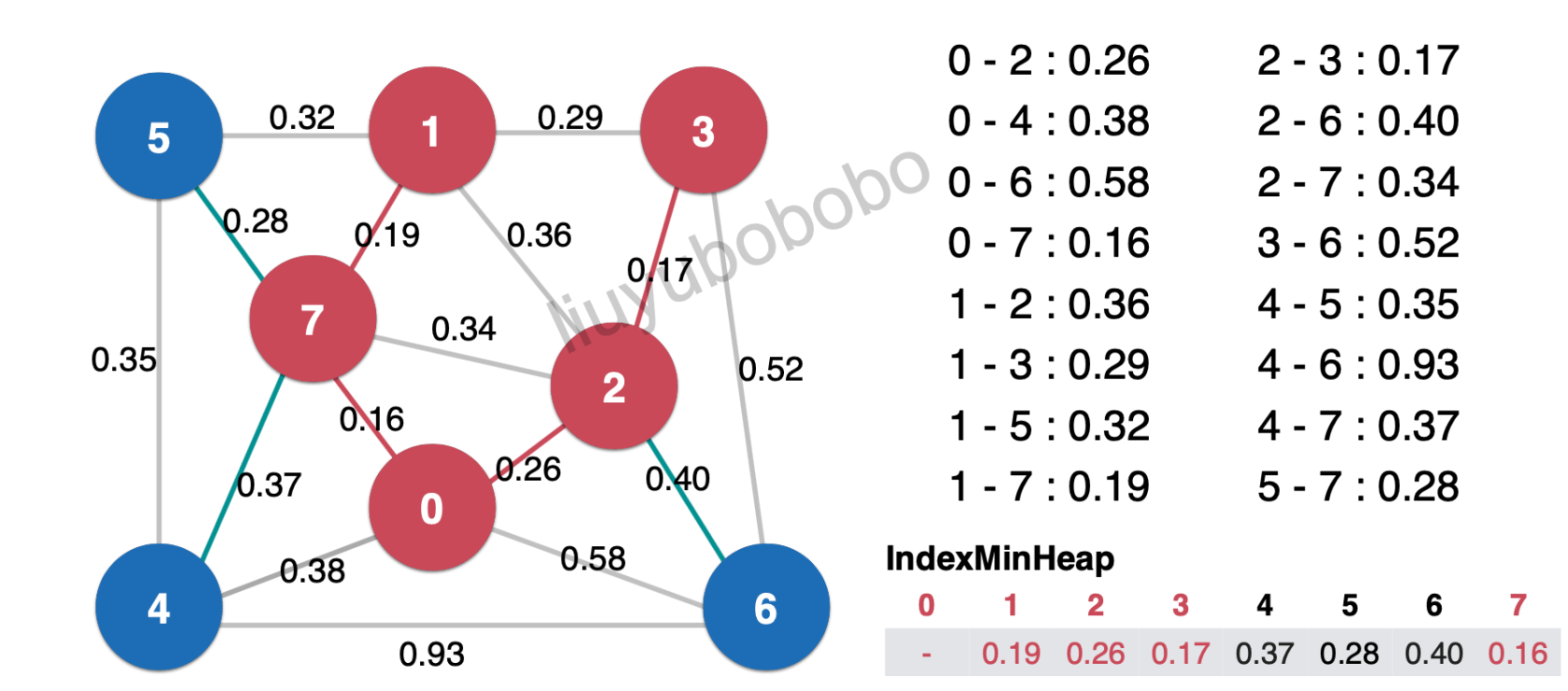
同理,按照步骤继续,运行,最后就可得到最小生成树:
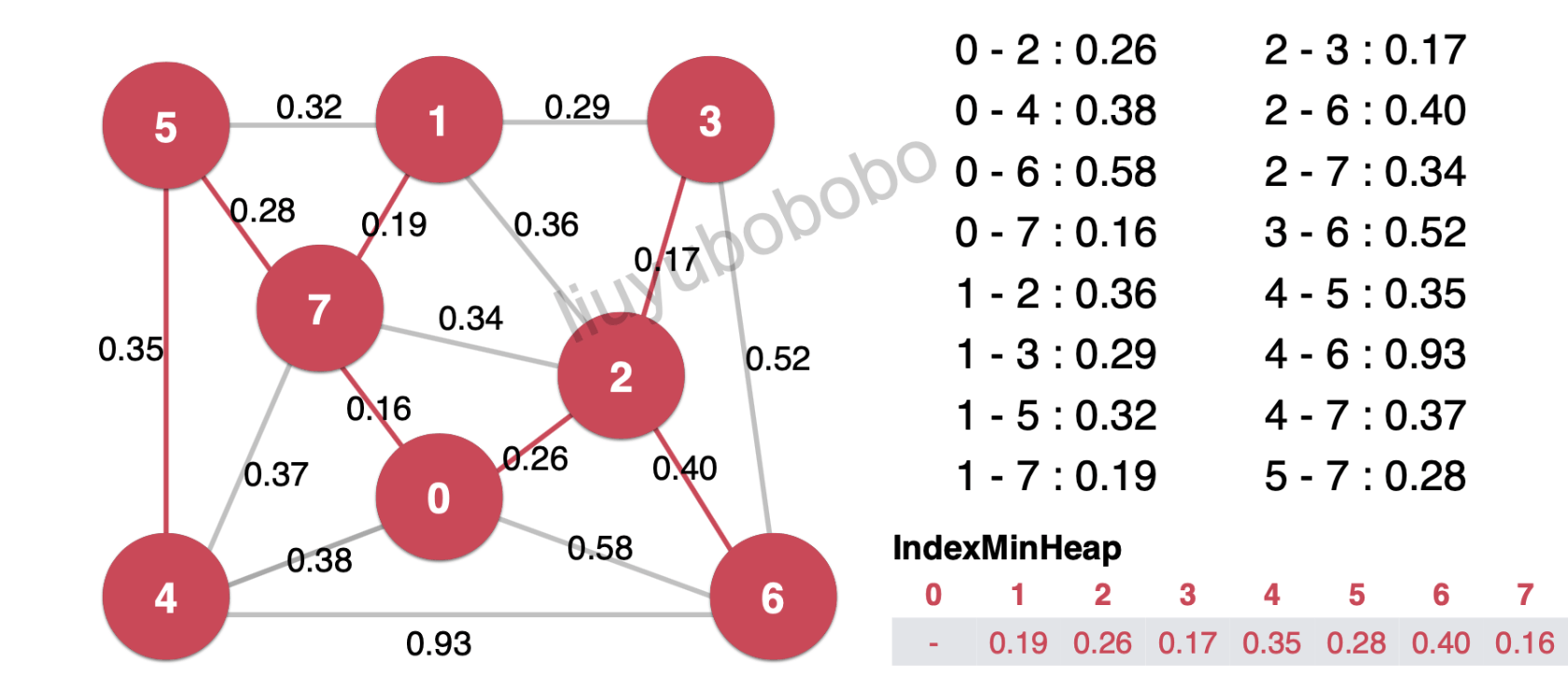
这就是优化后的prim。
三、代码实现
这里需要一个辅助数据结构——最小索引堆
#include <iostream>
#include <algorithm>
#include <cassert>
using namespace std;
//最小索引堆
template <typename Item>
class IndexMinHeap{
private:
Item data; //数据数组
int count; //数据对应索引
int capacity; //堆的容量
int *indexes; //最小索引堆中的索引,indexes[x] = i 表示索引在x的位置
int *reverse; // 最小索引堆中的反向索引, reverse[i] = x 表示索引i在x的位置
// 索引堆中, 数据之间的比较根据data的大小进行比较, 但实际操作的是索引
void shiftUP(int k){
while(data[indexes[k]] < data[indexes[k/2]]){
swap(indexes[k], indexes[k/2]);
reverse[indexes[k/2]] = k/2;
reverse[indexes[k]] = k;
k /= 2;
}
}
// 索引堆中, 数据之间的比较根据data的大小进行比较, 但实际操作的是索引
void shiftDown(int k){
//2*k <= count 至少存在左孩子
while(2*k <= count){
int j = 2*k;
//右孩子存在时
if(data[indexes[j]] > data[indexes[j+1]]){
j += 1;
}
//只有左孩子时
if(data[indexes[j]] >= data[indexes[k]]){
break;
}
swap(indexes[k], indexes[j]);
reverse[indexes[k]] = k;
reverse[indexes[j]] = j;
k = j;
}
}
public:
//构造函数
IndexMinHeap(int capacity){
data = new Item[capacity+1];
indexes = new int[capacity+1];
reverse = new int[capacity+1];
for(int i = 0;i < capacity; i++){
reverse[i] = 0;
}
count = 0;
this->capacity = capacity;
}
//析构函数
~IndexMinHeap(){
delete[] data;
delete[] indexes;
delete[] reverse;
}
//返回堆中元素个数
int size(){
return count;
}
//返回一个布尔值,表示索引堆是否为空
bool isEmpty(){
return count == 0;
}
//向最小索引堆中插入新元素,新元素索引为i,元素为item
//传入的对于用户来说是从0索引的
void insert(int index, Item item){
index += 1;
data[index] = item;
indexes[count+1] = index;
//reverse[index] = count+1 表示用来记录真正元素的索引对应在索引堆中的位置
reverse[index] = count+1;
count ++;
shiftUP(count);
}
// 从最小索引堆中取出堆顶元素, 即索引堆中所存储的最小数据
Item extractMin(){
assert(count > 0);
Item ret = data[indexes[1]];
swap(indexes[1], indexes[count]);
count--;
reverse[indexes[count]] = 0;
reverse[indexes[1]] = 1;
shiftDown(count);
return ret;
}
//获取最小索引堆中堆顶元素
Item getMin(){
assert(count > 0);
return data[indexes[1]];
}
//获取最小索引堆中堆顶元素的索引
int getIndexes(){
assert(count > 0);
return indexes[1]-1;
}
//看索引所在位置是否存在元素
bool contain(int index){
return reverse[index+1] != 0;
}
// 获取最小索引堆中索引为i的元素
Item getItem(int index){
assert(contain(index));
return data[index+1];
}
//将最小索引堆中索引为i元素修改成newItem
void change(int index, Item newItem){
assert( contain(index) );
index += 1;
data[index] = newItem;
shiftUP(reverse[index]);
shiftDown(reverse[index]);
}
};下面是prim的优化:
#include <iostream>
#include <vector>
#include <cassert>
#include "Edge.h"
#include "IndexMinHeap.h"
using namespace std;
// 使用优化的Prim算法求图的最小生成树
template<typename Graph, typename Weight>
class PrimMST{
private:
Graph &G; // 图的引用
IndexMinHeap<Weight> ipq; // 最小索引堆, 算法辅助数据结构
vector<Edge<Weight>*> edgeTo; // 访问的点所对应的边, 算法辅助数据结构
bool* marked; // 标记数组, 在算法运行过程中标记节点i是否被访问
vector<Edge<Weight>> mst; // 最小生成树所包含的所有边
Weight mstWeight; // 最小生成树的权值
// 访问节点v
void visit(int v){
assert( !marked[v] );
marked[v] = true;
// 将和节点v相连接的未访问的另一端点, 和与之相连接的边, 放入最小堆中
typename Graph::adjIterator adj(G,v);
for( Edge<Weight>* e = adj.begin() ; !adj.end() ; e = adj.next() ){
int w = e->other(v);
// 如果边的另一端点未被访问
if( !marked[w] ){
// 如果从没有考虑过这个端点, 直接将这个端点和与之相连接的边加入索引堆
if( !edgeTo[w] ){
edgeTo[w] = e;
ipq.insert(w, e->wt());
}
// 如果曾经考虑这个端点, 但现在的边比之前考虑的边更短, 则进行替换
else if( e->wt() < edgeTo[w]->wt() ){
edgeTo[w] = e;
ipq.change(w, e->wt());
}
}
}
}
public:
// 构造函数, 使用Prim算法求图的最小生成树
PrimMST(Graph &graph):G(graph), ipq(IndexMinHeap<double>(graph.V())){
assert( graph.E() >= 1 );
// 算法初始化
marked = new bool[G.V()];
for( int i = 0 ; i < G.V() ; i ++ ){
marked[i] = false;
edgeTo.push_back(NULL);
}
mst.clear();
// Prim
visit(0);
while( !ipq.isEmpty() ){
// 使用最小索引堆找出已经访问的边中权值最小的边
// 最小索引堆中存储的是点的索引, 通过点的索引找到相对应的边
int v = ipq.extractMinIndex();
assert( edgeTo[v] );
mst.push_back( *edgeTo[v] );
visit( v );
}
mstWeight = mst[0].wt();
for( int i = 1 ; i < mst.size() ; i ++ ){
mstWeight += mst[i].wt();
}
}
//析构函数
~PrimMST(){
delete[] marked;
}
vector<Edge<Weight>> mstEdges(){
return mst;
};
Weight result(){
return mstWeight;
};
};
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



