
笔记十三:多字段特性及 Mapping 中配置自定义 Analyzer
5 / 0 / 创建于 6年前 /
 CrazyZard 的个人博客
CrazyZard 的个人博客
多字段类型
- 多字段特性
- 厂家名字实现精确匹配
- 增加一个keyword字段
- 使用不同的analyzer
- 不同语言
- pinyin 字段的搜索
- 还支持为搜索和索引指定不同的analyzer
- 厂家名字实现精确匹配
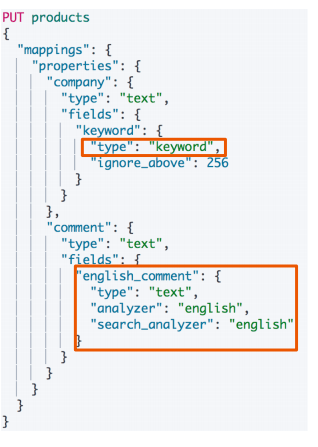
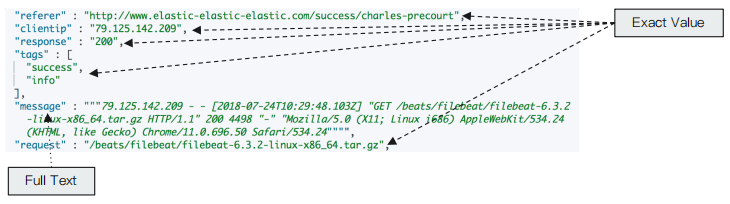
Excat values v.s Full Text
- Excat Values :包括数字 / 日期 / 具体一个字符串 (例如 “Apple Store”)
- Elasticsearch 中的keyword
- 全文本,非结构化的文本数据
- Elasticsearch 中的 text
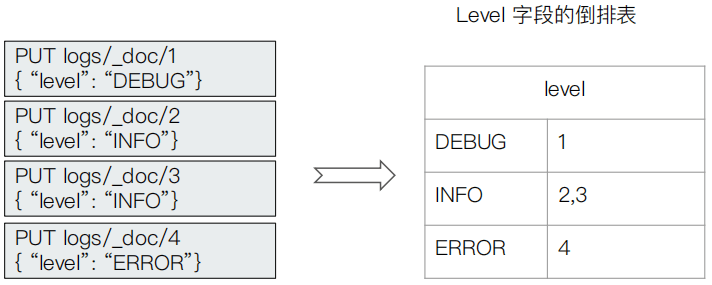
- Elaticsearch 为每一个字段创建一个倒排索引
- Exact Value 在索引时,不需要做特殊的分词处理
- 当Elasticsearch自带的分词器无法满足时,可以自定义分词器。通过自组合不同的组件实现
Character FilterTokenizerToken Filter
Character Filters
- 在
Tokenizer之前对文本进行处理,例如增加删除及替换字符。可以配置多个Character Filters。会影响Tokenizer的position和offset信息 - 一些自带的
Character FiltersHTML strip- 去除html标签Mapping- 字符串替换Pattern replace- 正则匹配替换
Tokenizer
- 将原始的文本按照一定的规则,切分为词(term or token)
Elasticsearch内置的Tokenizerswhitespace|standard|uax_url_email|pattern|keyword|path hierarchy
- 可以用JAVA 开发插件,实现自己的
Tokenizer
Token Filters
- 将
Tokenizer输出的单词,进行增加、修改、删除 - 自带的
Token FiltersLowercase|stop|synonym(添加近义词)
Demo char_filter
char_filter
POST _analyze { "tokenizer":"keyword", "char_filter":["html_strip"], "text": "<b>hello world</b>" } //结果 { "tokens" : [ { "token" : "hello world", "start_offset" : 3, "end_offset" : 18, "type" : "word", "position" : 0 } ] }使用char filter进行替换
POST _analyze { "tokenizer": "standard", "char_filter": [ { "type" : "mapping", "mappings" : [ "- => _"] } ], "text": "123-456, I-test! test-990 650-555-1234" } //返回 { "tokens" : [ { "token" : "123_456", "start_offset" : 0, "end_offset" : 7, "type" : "<NUM>", "position" : 0 }, { "token" : "I_test", "start_offset" : 9, "end_offset" : 15, "type" : "<ALPHANUM>", "position" : 1 }, { "token" : "test_990", "start_offset" : 17, "end_offset" : 25, "type" : "<ALPHANUM>", "position" : 2 }, { "token" : "650_555_1234", "start_offset" : 26, "end_offset" : 38, "type" : "<NUM>", "position" : 3 } ] }char filter 替换表情符号
POST _analyze { "tokenizer": "standard", "char_filter": [ { "type" : "mapping", "mappings" : [ ":) => happy", ":( => sad"] } ], "text": ["I am felling :)", "Feeling :( today"] } //返回 { "tokens" : [ { "token" : "I", "start_offset" : 0, "end_offset" : 1, "type" : "<ALPHANUM>", "position" : 0 }, { "token" : "am", "start_offset" : 2, "end_offset" : 4, "type" : "<ALPHANUM>", "position" : 1 }, { "token" : "felling", "start_offset" : 5, "end_offset" : 12, "type" : "<ALPHANUM>", "position" : 2 }, { "token" : "happy", "start_offset" : 13, "end_offset" : 15, "type" : "<ALPHANUM>", "position" : 3 }, { "token" : "Feeling", "start_offset" : 16, "end_offset" : 23, "type" : "<ALPHANUM>", "position" : 104 }, { "token" : "sad", "start_offset" : 24, "end_offset" : 26, "type" : "<ALPHANUM>", "position" : 105 }, { "token" : "today", "start_offset" : 27, "end_offset" : 32, "type" : "<ALPHANUM>", "position" : 106 } ] }正则表达式
GET _analyze { "tokenizer": "standard", "char_filter": [ { "type" : "pattern_replace", "pattern" : "http://(.*)", "replacement" : "$1" } ], "text" : "http://www.elastic.co" } //返回 { "tokens" : [ { "token" : "www.elastic.co", "start_offset" : 0, "end_offset" : 21, "type" : "<ALPHANUM>", "position" : 0 } ] }
Demo tokenizer
- 通过路劲切分
POST _analyze { "tokenizer":"path_hierarchy", "text":"/user/ymruan/a" } { "tokens" : [ { "token" : "/user", "start_offset" : 0, "end_offset" : 5, "type" : "word", "position" : 0 }, { "token" : "/user/ymruan", "start_offset" : 0, "end_offset" : 12, "type" : "word", "position" : 0 }, { "token" : "/user/ymruan/a", "start_offset" : 0, "end_offset" : 14, "type" : "word", "position" : 0 } ] } - token_filters
GET _analyze { "tokenizer": "whitespace", "filter": ["stop","snowball"], //on the a "text": ["The gilrs in China are playing this game!"] } { "tokens" : [ { "token" : "The", //大写的The 不做过滤 "start_offset" : 0, "end_offset" : 3, "type" : "word", "position" : 0 }, { "token" : "gilr", "start_offset" : 4, "end_offset" : 9, "type" : "word", "position" : 1 }, { "token" : "China", "start_offset" : 13, "end_offset" : 18, "type" : "word", "position" : 3 }, { "token" : "play", "start_offset" : 23, "end_offset" : 30, "type" : "word", "position" : 5 }, { "token" : "game!", "start_offset" : 36, "end_offset" : 41, "type" : "word", "position" : 7 } ] } - 加入lowercase后,The被当成 stopword删除
GET _analyze { "tokenizer": "whitespace", "filter": ["lowercase","stop","snowball"], "text": ["The gilrs in China are playing this game!"] } { "tokens" : [ { "token" : "gilr", "start_offset" : 4, "end_offset" : 9, "type" : "word", "position" : 1 }, { "token" : "china", "start_offset" : 13, "end_offset" : 18, "type" : "word", "position" : 3 }, { "token" : "play", "start_offset" : 23, "end_offset" : 30, "type" : "word", "position" : 5 }, { "token" : "game!", "start_offset" : 36, "end_offset" : 41, "type" : "word", "position" : 7 } ] }
自定义analyzer
- 官网自定义分词器的标准格式
官网看了一下,自定义分析器标准格式是: PUT /my_index { "settings": { "analysis": { "char_filter": { ... custom character filters ... },//字符过滤器 "tokenizer": { ... custom tokenizers ... },//分词器 "filter": { ... custom token filters ... }, //词单元过滤器 "analyzer": { ... custom analyzers ... } } } } - 自定义分词器
#定义自己的分词器 PUT my_index { "settings": { "analysis": { "analyzer": { "my_custom_analyzer":{ "type":"custom", "char_filter":[ "emoticons" ], "tokenizer":"punctuation", "filter":[ "lowercase", "english_stop" ] } }, "tokenizer": { "punctuation":{ "type":"pattern", "pattern": "[ .,!?]" } }, "char_filter": { "emoticons":{ "type":"mapping", "mappings" : [ ":) => happy", ":( => sad" ] } }, "filter": { "english_stop":{ "type":"stop", "stopwords":"_english_" } } } } }
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



