
笔记三十六:分页与遍历 From, Size,Search After & Scorll API
0 / 0 / 创建于 6年前 /
 CrazyZard 的个人博客
CrazyZard 的个人博客
From / Size
- 默认情况下,查询按照相关度算分排序,返回前10条记录
- 容易理解的分页方案
- From : 开始位置
- Size:期望获取文档的总数
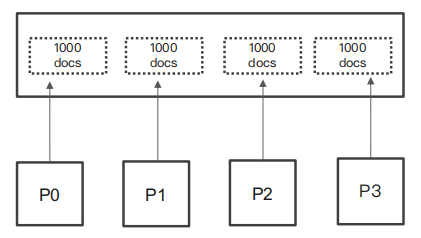
分布式系统中深度分页的问题
- ES 天生就是分布式,查询信息,但是数据分别保存在多个分片,多台机器,ES天生就需要满足排序的需要(按照相关性算分)
- 当一个查询:From = 990 ,Size =10
- 会在每个分片上先获取1000个文档。然后,通过Coordinating Node 聚合所有结果。最后在通过排序选取前1000个文档
- 页数越深,占用内容越多。为了避免深度分页带来的内存开销。ES有个设定,默认限定到10000个文档
POST tmdb/_search
{
"from": 10000,
"size": 1,
"query": {
"match_all": {}
}
}
//Search After 避免深度分页的问题
- 避免深度分页的性能问题,可以实时获取下一页文档信息
- 不支持指定页数(From)
- 不能往下翻
- 第一步搜索需要指定sort,并且保证值是唯一的(可以通过加入_id保证唯一性)
- 然后使用上一次,最后一个文档的sort值进行查询
POST users/_doc {"name":"user1","age":10} POST users/_doc {"name":"user2","age":11} POST users/_doc {"name":"user2","age":12} POST users/_doc {"name":"user2","age":13} POST users/_count POST users/_search { "size": 1, "query": { "match_all": {} }, "sort": [ {"age": "desc"} , {"_id": "asc"} ] } //返回 { "took" : 0, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 5, "relation" : "eq" }, "max_score" : null, "hits" : [ { "_index" : "users", "_type" : "_doc", "_id" : "I5aMPW8Bb23XqE-8Pu1n", "_score" : null, "_source" : { "name" : "user2", "age" : 13 }, "sort" : [ 13, "I5aMPW8Bb23XqE-8Pu1n" ] } ] } } POST users/_search { "size": 1, "query": { "match_all": {} }, "search_after": [ 10, "H5aMPW8Bb23XqE-8IO1c" ], "sort": [ {"age": "desc"} , {"_id": "asc"} ] }Search After 是如何解决深度分页的问题
- 假设Size是10
- 当查询990 -100
- 通过唯一排序值定位,将每次要处理的文档都控制在10
Scoll API
- 创建一个快照,有新的数据写入以后,无法被查找
- 每次查询后,输入上一次的Sroll Id
DELETE users POST users/_doc {"name":"user1","age":10} POST users/_doc {"name":"user2","age":20} POST users/_doc {"name":"user3","age":30} POST users/_doc {"name":"user4","age":40} POST /users/_search?scroll=5m { "size": 1, "query": { "match_all" : { } } } POST /_search/scroll { "scroll" : "1m", "scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAf3oEWQlQzZnpzdzlRdEdIUDFiRndaQU5BZw==" }
不同的搜索类型和使用场景
- Regular
- 需要实时获取顶部的部分文档。例如查询最新的订单
- Scorll
- 需要全部文档,例如导出全部数据
- Pagination
- From 和 Size
- 如何需要深度分页,则选用Search After
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu



