
笔记六十三:段合并优化及注意事项
0 / 0 / 创建于 6年前 /
 CrazyZard 的个人博客
CrazyZard 的个人博客
- Lucene Index 原理回顾
- 在
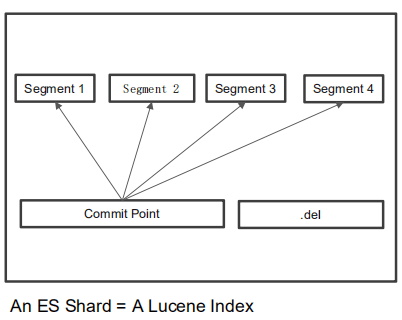
Lucene中,单个倒排索引文件被称为Segment。Segment是自包含的,不可变更的。 多个 Segments 汇总在一起,称为Lucene的 Index,其对应的就是 ES 中的 Shard - 当有新文档写入时,并且执行
Refresh,就会生成一个新Segment。Lucene中有一个文 件,用来记录所有Segments信息,叫做Commit Point。查询时会同时查询所有Segments,并且对结果汇总。 - 删除的文档信息,保存在 “.del” 文件中,查 询后会进行过滤。
- Segment 会定期 Merge,合并成一个,同时删 除已删除文档
- 在
Merge 优化
ES 和 Lucene 会自动进行 Merge 操作
Merge 操作相对比较重,需要优化,降低对系统的影响
优化点一:降低分段产生的数量/频率
- 可以将 Refresh Interval 调整到分钟级别 / indices.memory.index_buffer_size (默认是 10%)
- 尽量避免文档的更新操作
优化点二:降低最大分段大小,避免较大的分段继续参与 Merge,节省系统资源。(最终会有多个分段)
Index.merge.policy.segments_per_tier,默认为 10, 越小需要越多的合并操作Index.merge.policy.max_merged_segment, 默认 5 GB, 操作此大小以后,就不再参与后续的合并操作
Force Merge
- 当 Index 不再有写入操作的时候,建议对其进行 force merge
- 提升查询速度 / 减少内存开销

- 提升查询速度 / 减少内存开销
- 最终分成几个 segments 比较合适?
- 越少越好,最好可以 force merge 成 1 个,但是,Force Merge 会占用大量的网络,IO 和 CPU
- 如果不能在业务高峰期之前做完,就需要考虑增大最终的分段数
- Shard 的大小 /
Index.merge.policy.max_merged_segment的大小
- Shard 的大小 /
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



