
笔记四十二:对象及 Nested 对象
0 / 0 / 创建于 6年前 /
 CrazyZard 的个人博客
CrazyZard 的个人博客
数据的关联关系
- 真实世界中很多重要的关联关系
- 博客、作者、评论
- 银行账户有多次交易记录
- 客户有很多银行账户
- 目录文件有很多文件和子目录
关系型数据库的范式化设计
- 范式化设计(Normalization)的主要目标是“减少不必要的更新”
- 副作用:一个完全范式化设计的数据库经常面临“查询缓慢”的问题
- 数据库余额范式化,就需要Join越多的表
- 范式化节省了储存空间,但是储存空间越来越便宜
- 范式化简化了更新,但是数据“读”取操作可能越多

Denormalization
- 反范式化设计
- 数据“Flattening”,不使用关联关系,而是在文档中保存冗余的数据拷贝
- 优点:无需处理Joins操作,数据读取性能好
- Elasticsearch 通过压缩_source字段,减少磁盘空间的开销
- 缺点:不适合在数据频繁修改的场景
- 一条数据(用户名)的改动,可能会引起很多数据的更新
在 Elasticsearch 中处理关联关系
- 关系型数据库,一般会考虑 Normalize 数据;在Elasticsearch,往往考虑 Denormalize 数据
- Denormalize 的好处:读的速度变快、无需表连接、无需行锁
- Elasticsearch 并不擅长处理关联关系,我们一般采用以下四种方法处理关联
- 对象类型
- 嵌套对象(Nested Object)
- 父子关联关系(Parent 、Child)
- 应用端关联
案例1:博客和其作者信息
- 对象类型
- 在每个博客的问下中都保留作者的信息
- 如果作者信息发生变化,需要修改相关的博客文档
PUT /blog
{
"mappings": {
"properties": {
"content": {
"type": "text"
},
"time": {
"type": "date"
},
"user": {
"properties": {
"city": {
"type": "text"
},
"userid": {
"type": "long"
},
"username": {
"type": "keyword"
}
}
}
}
}
}
# 插入一条 Blog 信息
PUT blog/_doc/1
{
"content":"I like Elasticsearch",
"time":"2019-01-01T00:00:00",
"user":{
"userid":1,
"username":"Jack",
"city":"Shanghai"
}
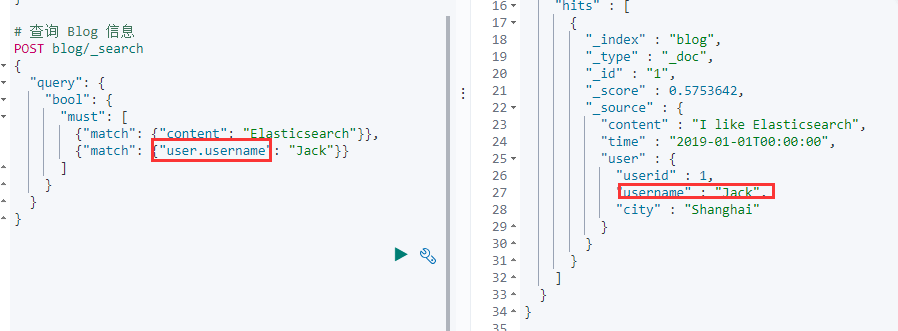
}- 通过一条查询语句即可获取到博客和作者信息
# 查询 Blog 信息 POST blog/_search { "query": { "bool": { "must": [ {"match": {"content": "Elasticsearch"}}, {"match": {"user.username": "Jack"}} ] } } }
案例2:包含对象数组的文档
# 电影的Mapping信息
PUT my_movies
{
"mappings" : {
"properties" : {
"actors" : {
"properties" : {
"first_name" : {
"type" : "keyword"
},
"last_name" : {
"type" : "keyword"
}
}
},
"title" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
# 写入一条电影信息
POST my_movies/_doc/1
{
"title":"Speed",
"actors":[
{
"first_name":"Keanu",
"last_name":"Reeves"
},
{
"first_name":"Dennis",
"last_name":"Hopper"
}
]
}
# 查询电影信息
POST my_movies/_search
{
"query": {
"bool": {
"must": [
{"match": {"actors.first_name": "Keanu"}},
{"match": {"actors.last_name": "Hopper"}}
]
}
}
}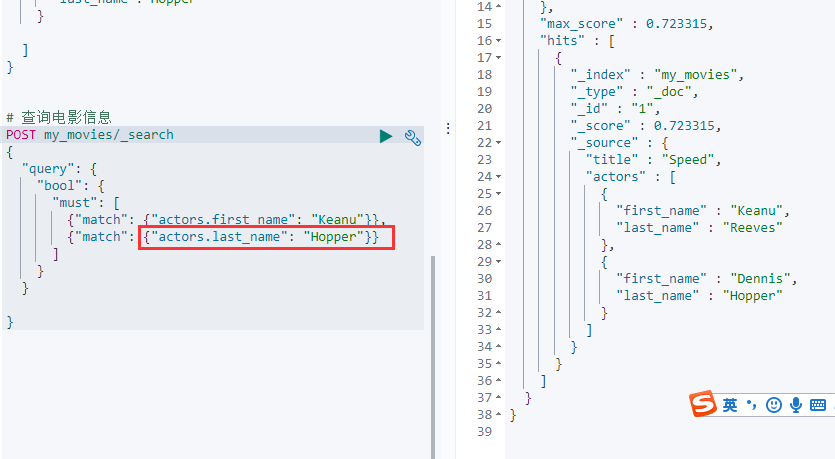
为啥搜不到
- 储存时,内部对象的边界没有在考虑在内,JSON格式被处理成扁平键值对的结构
- 当对多个字段进行查询时,导致了意外的搜索结果
- 可以用 Nested Data Type 解决这个问题
Nested Data Type
- Nested 数据类型:允许对象数组中的对象呗独立索引
- 使用 Nested 和 Properties 关键词,将所有 actors 索引到对个分隔的文档
- 在内部,Nested 文档会被保存在两个 Lucene 文档中,查询时做join处理
PUT my_movies
{
"mappings" : {
"properties" : {
"actors" : {
"type": "nested",
"properties" : {
"first_name" : {"type" : "keyword"},
"last_name" : {"type" : "keyword"}
}},
"title" : {
"type" : "text",
"fields" : {"keyword":{"type":"keyword","ignore_above":256}}
}
}
}
}嵌套查询
- 在内部,Nested 文档被保存在两个Lucene 文档中

# Nested 查询
POST my_movies/_search
{
"query": {
"bool": {
"must": [
{"match": {"title": "Speed"}},
{
"nested": {
"path": "actors",
"query": {
"bool": {
"must": [
{"match": {
"actors.first_name": "Keanu"
}},
{"match": {
"actors.last_name": "Hopper"
}}
]
}
}
}
}
]
}
}
}
//返回
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}嵌套聚合
# Nested Aggregation
POST my_movies/_search
{
"size": 0,
"aggs": {
"actors": {
"nested": {
"path": "actors"
},
"aggs": {
"actor_name": {
"terms": {
"field": "actors.first_name",
"size": 10
}
}
}
}
}
}本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



