
笔记十五:聚合分析简介
3 / 0 / 创建于 6年前 /
 CrazyZard 的个人博客
CrazyZard 的个人博客
聚合(Aggregation)
- Elasticsearch除搜索以外,提供的针对ES数据进行统计分析的功能
- 实时性
- Hadoop (T+1)
- 通过聚合,我们会得到一个数据的概念,是分析和总结全套的数据,而不是寻找单个文档
- 尖沙咀和香港岛的客房数量
- 不同的价格区间,可预定的经济型酒店和五星级酒店的数量
- 高性能,只需要一条语句,就可以从ES得到分析结果
- 无需再客户端自己去实现分析逻辑
Kibana 可视化报表
集合的分类
- Bucket Aggregation - 一些列满足特定条件的文档的集合
- Metric Aggregation - 一些数学运算,可以对文档字段进行统计分析
- Pipeline Aggregation - 对其他的聚合结果进行二次聚合
- Matrix Aggregation - 支持对多个字段的操作并提供一个结果矩阵
Bucket & Metric
- Metric - 一些系统的统计方法(类似 count)
- Bucket - 一组满足条件的文档(group by)
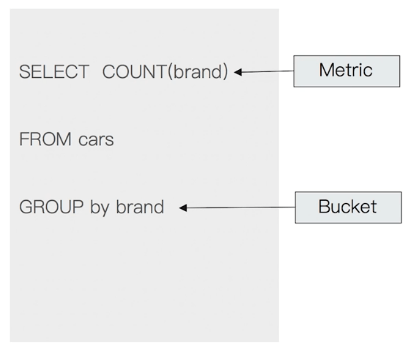
Bucket
- 一些例子
- 杭州属于浙江 / 演员是男或女
- 嵌套关系 - 杭州属于浙江属于中国属于亚洲
- ES 提供了许多的类型的Bucket,帮助用多种方式划分文档
- Tern & Range (时间 / 年龄区间 / 地理位置)
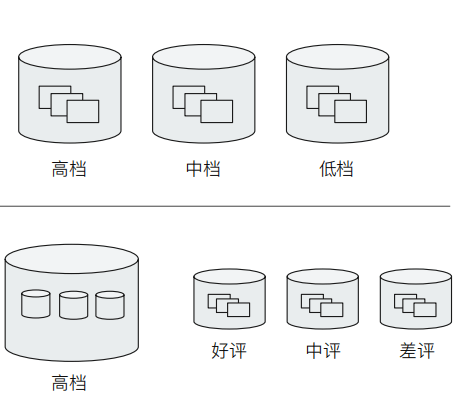
- Tern & Range (时间 / 年龄区间 / 地理位置)
Metric
- Metric 会基于数据集计算结果,除了支持在字段上进行计算,同样也支持在脚本(painless script)产生的结果之上进行计算
- 大多数Metric是数学计算,仅输出一个值
- min / max / sum / avg /cardinality
- 部分metric 支持输出多个数值
- stats / percentiles / percentile_ranks
Demo

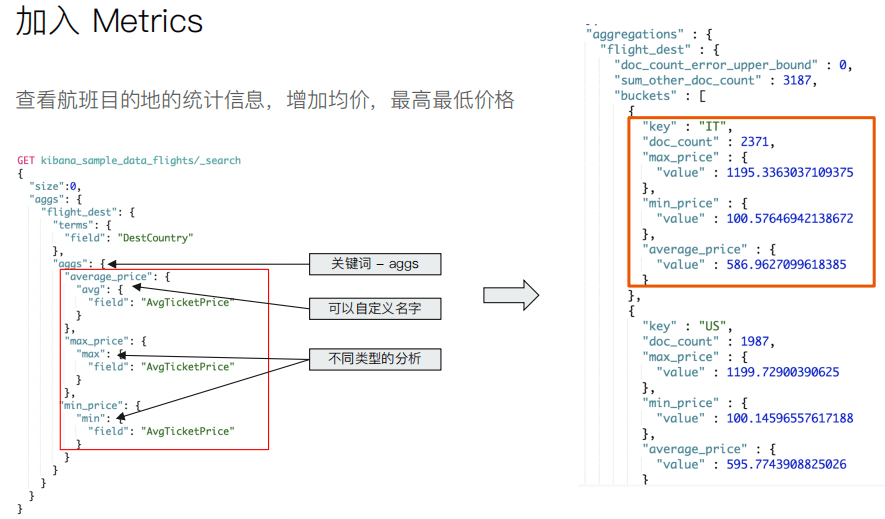

本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



