
笔记三十二:文档分布式存储
0 / 0 / 创建于 6年前 /
 CrazyZard 的个人博客
CrazyZard 的个人博客
文档储存在分片上
- 文档会存储在具体的某个主分片和副本分片上:例如文档1,会储存在P0 R0分片上
- 文档到分片的映射算法
- 确保文档能均匀分布在所用分片上,充分利用硬件资源,避免部分机器空闲,部门机器繁忙
- 潜在的算法
- 随机/Round Robin.当查询文档1,分片数很多,需要多次查询才能查档文档1
- 维护文档到分片的映射关系,当文档数据量大的时候,维护成本高
- 实时计算,通过文档1,自动算出,需要去哪个分片上获取文档
文档到分片的路由算法
- shard = hash(_routing) % number_of_primary_shards
- Hash 算法确保文档均匀分散到分片中
- 默认的_routing 值是文档id
- 可以自行制定routing数值,例如用相同国家的商品,都分配到制定的shard
- 设置Index Setting 后,Primary 数,不能随意修改的根本原因
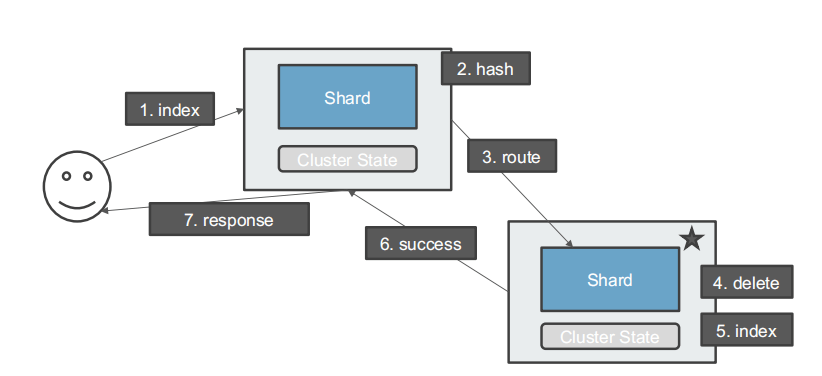
更新文档
- 顺序: index -> hash -> route -> delete -> index -> success -> response
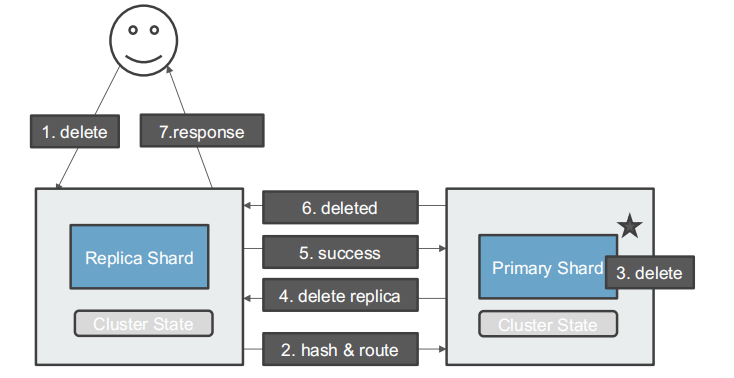
删除一个文档
- 顺序 :detele -> hash&route -> delete -> delete replica -> success -> deleted -> response
总结
- 可以设置Index Settings ,控制数据的分片
- Primary Shard 的值不能修改,修改需要重新Index。默认值是5,从版本7开始,默认值为1
- 索引写入数据后,Replica值可以修改。增加副本,可提高大并发下的读取性能
- 通过控制集群的节点数,设置Primary Shard 数,实现水平扩展
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



