
笔记六十一:提升集群写性能
0 / 0 / 创建于 6年前 /
 CrazyZard 的个人博客
CrazyZard 的个人博客
提高写入性能的方法
- 写性能优化的目标:增大写吞吐量(Events Per Second),越高越好
- 客户端:多线程,批量写
- 可以通过性能测试,确定最佳文档数量
- 多线程:需要观察是否有 HTTP 429 返回,实现 Retry 以及线程数量的自动调节
- 服务器端:单个性能问题,往往是多个因素造成的。需要先分解问题,在单个节点上进行调整并 且结合测试,尽可能压榨硬件资源,以达到最高吞吐量
- 使用更好的硬件。观察 CPU / IO Block
- 线程切换 / 堆栈状况
服务器端优化写入性能的一些手段
- 降低 IO 操作
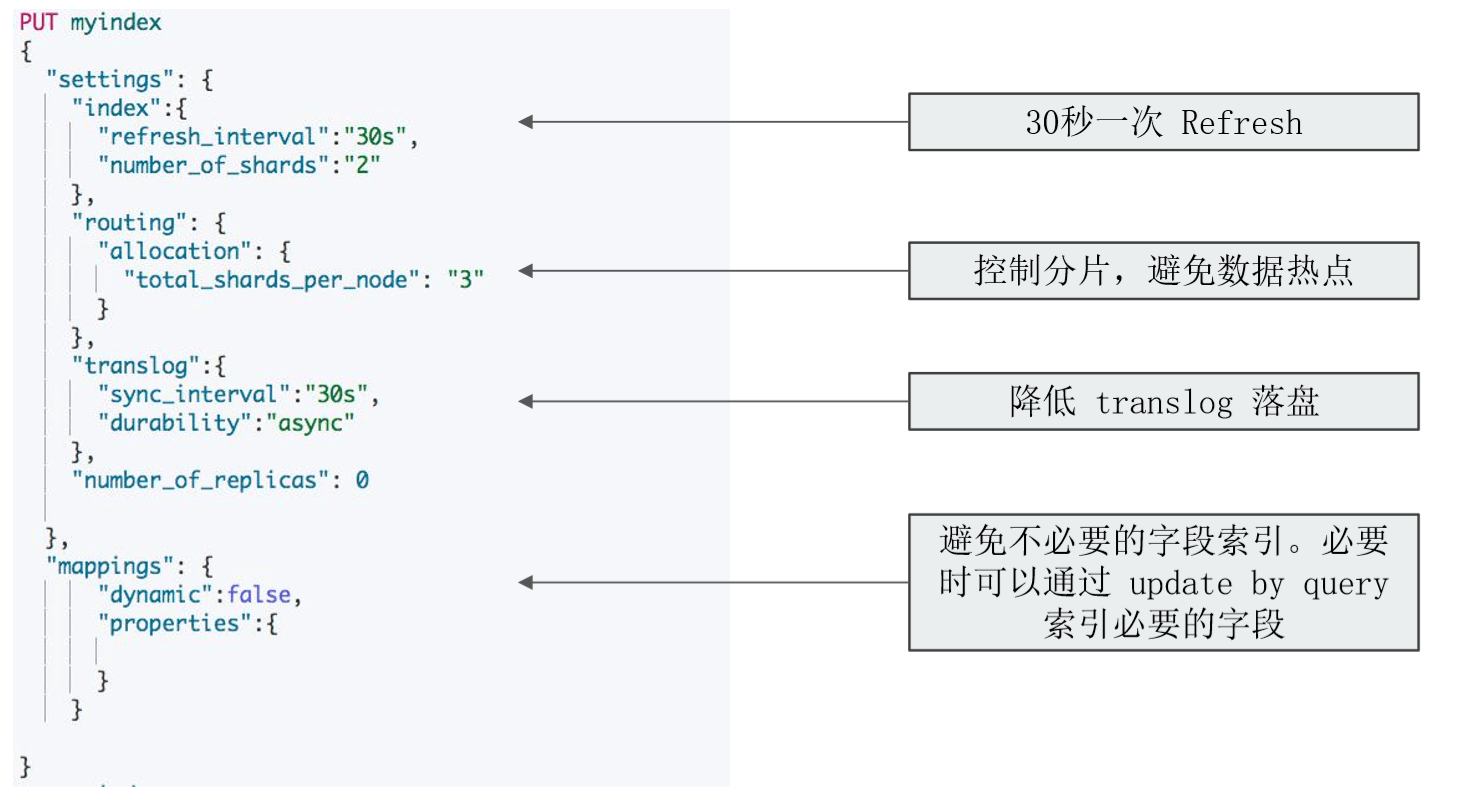
- 使用 ES 自动生成的文档 Id / 一些相关的 ES 配置,如 Refresh Interval
- 降低 CPU 和存储开销
- 减少不必要分词 / 避免不需要的 doc_values /文档的字段尽量保证相同的顺序,可以提高文档的压缩率
- 尽可能做到写入和分片的均衡负载,实现水平扩展
- Shard Filtering / Write Load Balancer
- 调整 Bulk 线程池和队列
优化写入性能
- ES 的默认设置,已经综合考虑了数据可靠性,搜索的实时性质,写入速度,一般不要盲目修改
- 一切优化,都要基于高质量的数据建模
关闭无关的功能
- 只需要聚合不需要搜索, Index 设置成 false
- 不需要算分, Norms 设置成 false
- 不要对字符串使用默认的 dynamic mapping。字段 数量过多,会对性能产生比较大的影响
- Index_options 控制在创建倒排索引时,哪些内容 会被添加到倒排索引中。优化这些设置,一定程度 可以节约 CPU
- 关闭 _source,减少 IO 操作;(适合指标型数据)

针对性能的取舍
- 如果需要追求极致的写入速度,可以牺牲数据可靠性及搜索实时性以换取性能
- 牺牲可靠性:将副本分片设置为 0,写入完毕再调整回去
- 牺牲搜索实时性:增加 Refresh Interval 的时间
- 牺牲可靠性:修改 Translog 的配置
数据写入的过程
- Refresh
- 将文档先保存在
Index buffer中, 以refresh_interval为间隔时间,定期清空buffer,生成segment,借助文件系统缓存的特性,先将segment放在文件系统缓存中,并开放查询,以提升搜索的实时性
- 将文档先保存在
- Translog
- Segment 没有写入磁盘,即便发生了当机,重启后,数据也能恢复,默认配置是每次请求都会落盘
- Flush
- 删除旧的 translog 文件
- 生成 Segment 并写入磁盘 / 更新 commit point 并写入磁盘。 ES 自动完成,可优化点不多
Refresh Interval
- 降低 Refresh 的频率
- 增加 refresh_interval 的数值。默认为 1s ,如果设置成 -1 ,会禁止自动 refresh
- 避免过于频繁的 refresh,而生成过多的 segment 文件
- 但是会降低搜索的实时性
- 增大静态配置参数
indices.memory.index_buffer_size- 默认是 10%, 会导致自动触发 refresh
- 增加 refresh_interval 的数值。默认为 1s ,如果设置成 -1 ,会禁止自动 refresh
Translog
- 降低写磁盘的频率,但是会降低容灾能力
- `Index.translog.durability`:默认是 request,每个请求都落盘。设置成 async,异步写入 - `Index.translog.sync_interval` 设置为 60s,每分钟执行一次 - `Index.translog.flush_threshod_size`: 默认 512 mb,可以适当调大。 当 translog 超过该值,会触发 flush
分片设定
- 副本在写入时设为 0,完成后再增加
- 合理设置主分片数,确保均匀分配在所有数据节点上
Index.routing.allocation.total_share_per_node: 限定每个索引在每个节点上可分配的分片数(replicas and primaries)- 5 个节点的集群。 索引有 5 个主分片,1 个副本,应该如何设置?
- (5+5) / 5 = 2
- 生产环境中要适当调大这个数字,避免有节点下线时,分片无法正常迁移
Bulk,线程池和队列大小
- 客户端
- 单个 bulk 请求体的数据量不要太大,官方建议大约5-15mb - 写入端的 bulk 请求超时需要足够长,建议60s 以上 - 写入端尽量将数据轮询打到不同节点。 - 服务器端
- 索引创建属于计算密集型任务,应该使用固定大小的线程池来配置。来不及处理的放入队列,线程数应该 配置成 CPU 核心数 +1 ,避免过多的上下文切换
- 队列大小可以适当增加,不要过大,否则占用的内存会成为 GC 的负担
一个索引设定的例子
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



