
笔记四十一:聚合的精准度问题
0 / 0 / 创建于 5年前 /
 CrazyZard 的个人博客
CrazyZard 的个人博客
分布式系统的近似统计算法
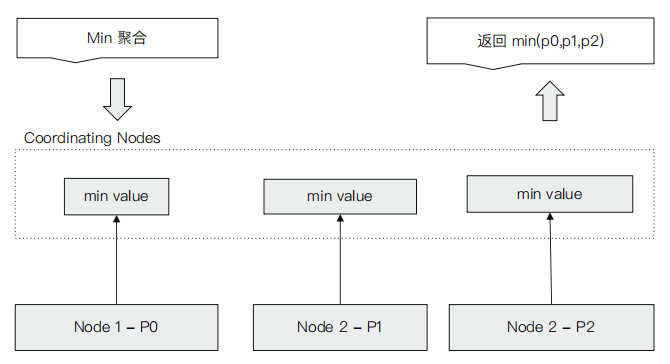
Min 聚合分析的执行流程
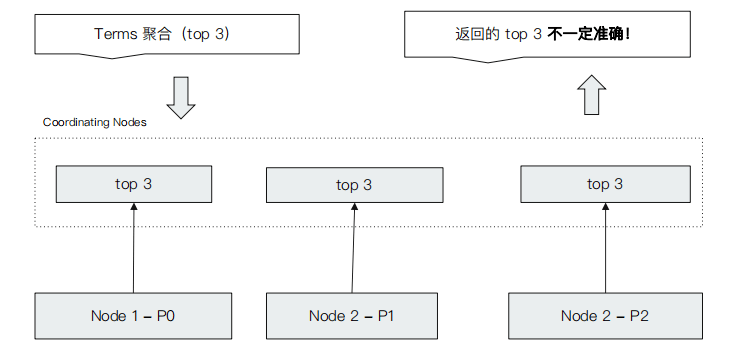
Terms Aggregation 的返回值
- 在Terms Aggregation的返回中有两个特殊的数值
- doc_count_error_upper_bound:被遗漏的term分桶,包含的文档,有可能的最大值
- sum_other_doc_count:处理返回结果bucket的terms以外,其他terms的文档总数(总数-返回的总数)

Terms 聚合分析的执行流程
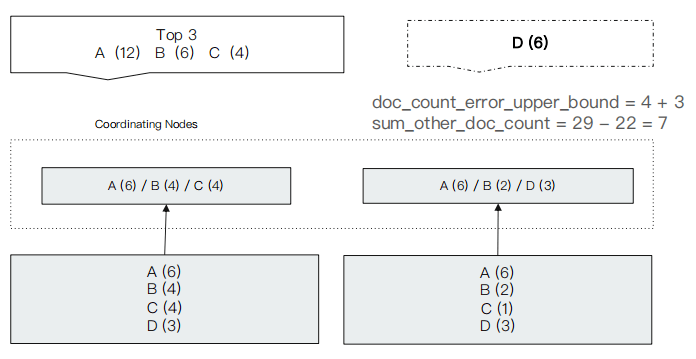
Terms 不正确的案例
如何解决Terms不准的问题:提升 shard_size 的参数
- Terms 聚合分析不准的原因,数据分散在多个分片上,Coordinating Node 无法获取数据全貌
- 解决方案1:当数据量不大时,设置Primary Shard 为1;实现准确性
- 解决方案2:在分布式数据上,设置shard_size 参数,提高精确度
- 原理:每次从Shard 上额外多获取数据,提升准确率

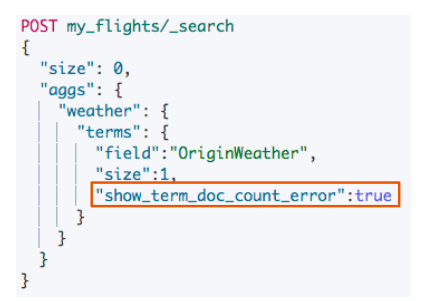
打开 show_term_doc_count_error
shard_size 设定
- 调整 shard size 大小,降低 doc_count_error_upper_bound 来提升准确度
- 增加整体计算量,提高了准确率,但会降低相应时间
- Shard Size 默认大小设定
- shard size = size * 1.5 +10
https://www.elastic.co/guide/en/elasticsea...GET kibana_sample_data_flights/_search { "size": 0, "aggs": { "weather": { "terms": { "field":"OriginWeather", "size":5, "show_term_doc_count_error":true } } } } GET my_flights/_search { "size": 0, "aggs": { "weather": { "terms": { "field":"OriginWeather", "size":1, "shard_size":1, "show_term_doc_count_error":true } } } }
- shard size = size * 1.5 +10
本作品采用《CC 协议》,转载必须注明作者和本文链接



 关于 LearnKu
关于 LearnKu



