
 学习 Python:强大的面向对象编程(第 5 版)
学习 Python:强大的面向对象编程(第 5 版)核心对象类型复习和总结——引用 VS 拷贝
第6章提到:赋值总是存储到对象的引用,而非这些对象的拷贝。在实践中,这通常是你想要的。然而,因为赋值能产生对同一对象的多个引用,所以知道就地改变一个可变对象可能会影响程序中在任何地方的对同一对象的其它引用是很重要的。如果不想要这种行为,则需要明确告诉Python去复制这个对象。
在第6章中学到了这个现象,但当开始涉及从那时开始探索的更大对象时,情况就开始变得更加微妙了。比如,下面例子创建了分配给 X 的一个列表,然后另一个列表被分配给 L ,它嵌套了一个列表 X 的引用。这个例子还创建一个字典 D,它包含另一个列表 X 的引用:
>>> X = [1, 2, 3]
>>> L = ['a', X, 'b'] # Embed references to X's object
>>> D = {'x':X, 'y':2}现在,有三个引用指向第一个被创建的列表:从变量名 X,从被分配给L的列表内,从被分配给D的字典内。情况如图9-2所示:
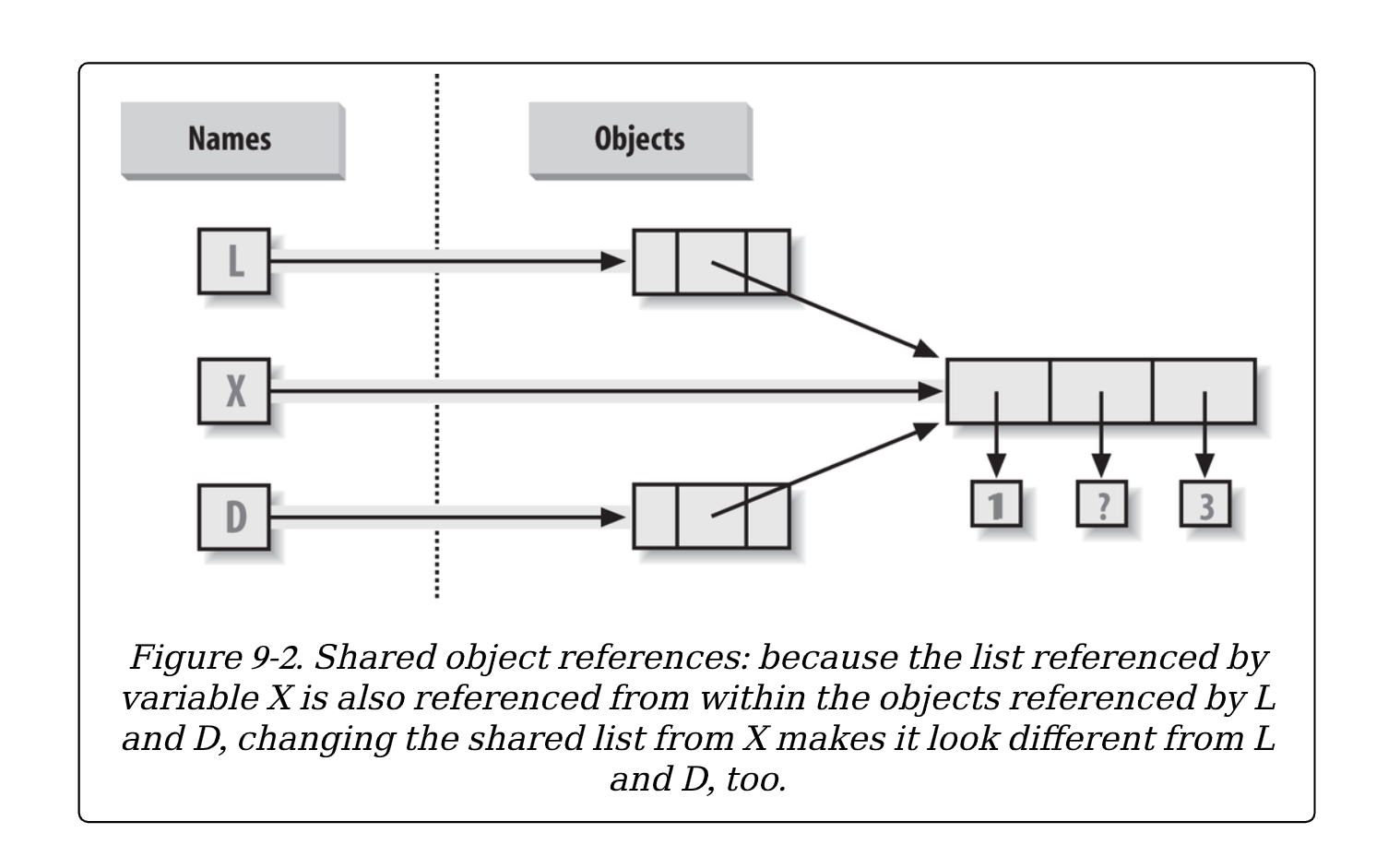
因为列表是可变的,从上述三个引用的任何一个中改变共享的列表对象也会改变其它两个所引用的对象:
>>> X[1] = 'surprise' # Changes all three references!
>>> L
['a', [1, 'surprise', 3], 'b']
>>> D
{'x': [1, 'surprise', 3], 'y': 2}引用是其它语言中“指针”的更高级类比,当被使用时总是被跟随。虽然不能抓住引用本身,但存储同一引用在多于一个地方(变量、列表等)是可能的。这是一个特性——可以在程序中拷贝一个大对象而无需在此过程中产生其昂贵的拷贝。然而,如果真的想要拷贝,可以(用下列方法来)要求它们:
- 限制为空的切片操作(L[:])拷贝序列。
- 字典、set和列表的
copy方法(X.copy())拷贝字典、set或列表(列表的copy是从3.3版本开始新增的)。 - 一些内置函数,如
list和dict创建拷贝(list(L),dict(D),set(S))。 - 当需要时,
copy标准库模块创建完整拷贝。
比如,假如有一个列表和一个字典,且不想让它们的值通过其它变量改变:
>>> L = [1,2,3]
>>> D = {'a':1, 'b':2}要防止这个现象,简单地将拷贝分配给其它变量,而非对同样对象的引用:
>>> A = L[:] # Instead of A = L (or list(L) 也行)
>>> B = D.copy() # Instead of B = D (ditto for sets)这样,从其它变量进行的更改将改变拷贝,而非原变量:
>>> A[1] = 'Ni'
>>> B['c'] = 'spam'
>>>
>>> L, D
([1, 2, 3], {'a': 1, 'b': 2})
>>> A, B
([1, 'Ni', 3], {'a': 1, 'c': 'spam', 'b': 2})就原来的例子而言,可以通过对原来的列表进行切片而非简单地写出其名字来避免引用的副作用:
>>> X = [1, 2, 3]
>>> L = ['a', X[:], 'b'] # Embed copies of X's object
>>> D = {'x':X[:], 'y':2}
>>> X[1] = 'surprise'
>>> L
['a', [1, 2, 3], 'b']
>>> D
{'x': [1, 2, 3], 'y': 2}这改变了图9-2中的情况——L 和 D 现在将指向不同于X的列表。最终效果是通过X的改变将只影响X,而非L和D;类似地,对L或D的改变将不会影响X。
关于拷贝的最后一个说明:空限制的切片和字典的copy方法只创建底层的拷贝;也就是说,它们不会拷贝嵌套的数据结构(如果有的话)。如果需要一个完整的,完全的独立的深层嵌套的数据结构的拷贝(如已经在最近章节中编码过的各种记录结构),请使用在第6章中介绍的标准copy模块:
import copy
X = copy.deepcopy(Y) # Fully copy an arbitrarily nested object
Y这个调用递归地遍历对象来拷贝其所有部分。然而,这是一个非常罕见的情况,这就是为什么要使用这个方案,你必须说更多。引用通常是你需要的;当不需要引用时,切片和拷贝方法通常与你需要的拷贝一样多。






 关于 LearnKu
关于 LearnKu




推荐文章: